原文引自:http://blog.csdn.net/u011497897/article/details/71440323
一、Spark简介
1、什么是Spark
发源于AMPLab实验室的分布式内存计算平台,它克服了MapReduce在迭代式计算和交互式计算方面的不足。
相比于MapReduce,Spark能充分利用内存资源提高计算效率。
2、Spark计算框架
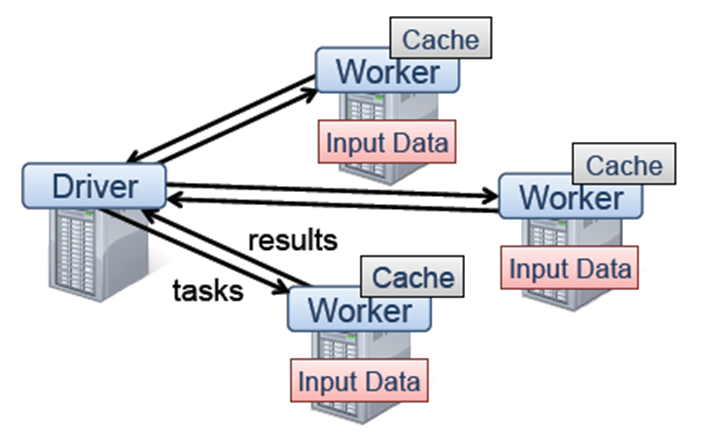
Driver程序启动很多workers,然后workers在(分布式)文件系统中读取数据后转化为RDD(弹性分布式数据集),最后对RDD在内存中进行缓存和计算
(2)优化执行计划
4、Spark Api语言支持
(1)Scala
(2)Java
(3)Python
5、怎么运行Spark
Local本地模式、Spark独立集群、Mesos、Yarn-Standalone、Yarn-Client
二、编程模型
1、RDD(弹性分布式数据集)是什么
只读的、分块的数据记录集合
可以通过读取来不同存储类型的数据进行创建、或者通过RDD操作生成(map、filter操作等)
使用者只能控制RDD的缓存或者分区方式
RDD的数据可以有多种类型存储方式(可(序列化)存在内存或硬盘中)
2、RDD 存储类型
RDD可以设置不同类型存储方式,只存硬盘、只存内存等。

3、RDD操作
Transformation:根据已有RDD创建新的RDD数据集build

JavaSparkContext sc = new JavaSparkContext("local","SparkTest");
接受2个参数:
第一个参数表示运行方式(local、yarn-client、yarn-standalone等)
第二个参数表示应用名字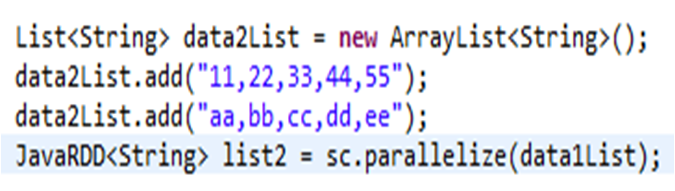

执行结果:对list1数据集每行数据用","进行切分
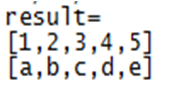
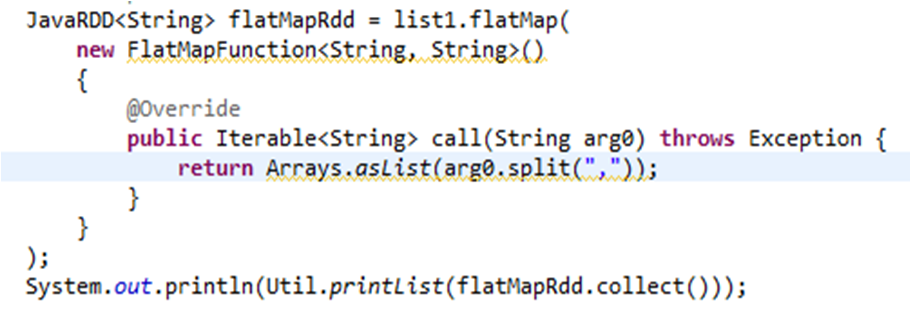
执行结果:对list1数据集每行数据用","进行切分
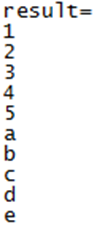
3)filter
filter对每行数据执行过滤操作,返回true则保留,返回false则过滤该行数据
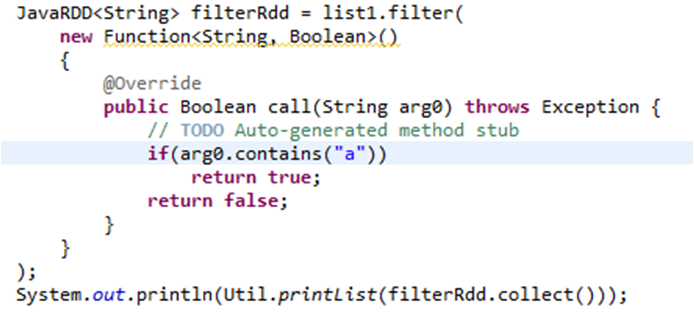
执行结果:过滤list1数据集中包含‘a’字符的行
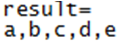
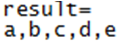
4)union
union操作对两个RDD数据进行合并。与SQL中的union一样

执行结果:合并list1与list2数据集
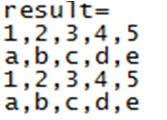

执行结果:对pair1RDD数据集按key进行group by

(6)reduceByKey
reduceByKey对pair中的key先进行group by操作,然后根据函数对聚合数据后的数据操作
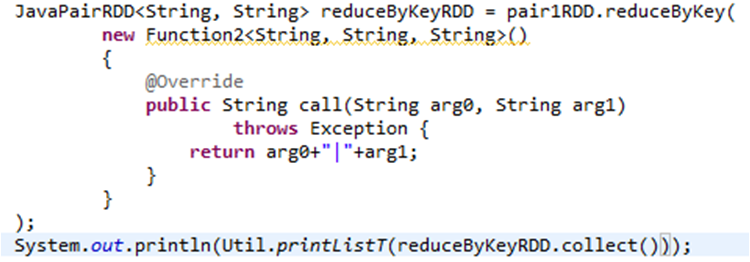
执行结果:先group by操作后进行concat
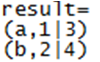
(7)mapValues
mapValues操作对pair中的value部分执行函数里面的操作
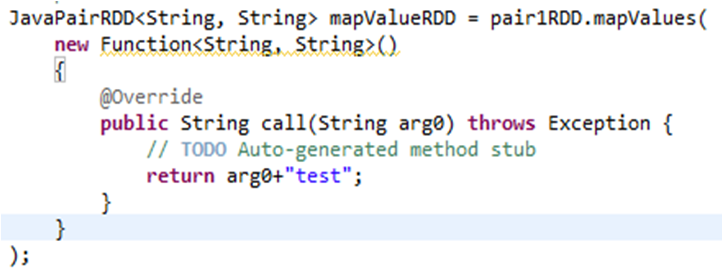
执行结果:对pair1RDD中value部分加上test字符串

8)join
join与sql中join含义一致,将两个RDD中key一致的进行join连接操作

执行结果:对pair1RDD与pair2RDD按key进行join

(9)cogroup
cogroup对两个RDD数据集按key进行group by,并对每个RDD的value进行单独group by

执行结果:对pair1RDD与pair2RDD按key进行cogroup

6、RDD数据如何输出
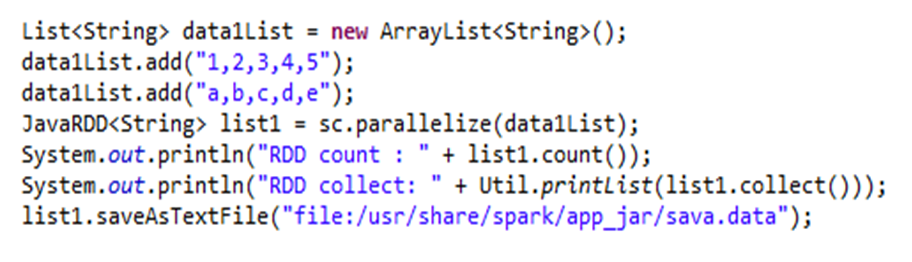
执行结果:
count:统计输出数据行数
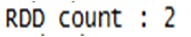
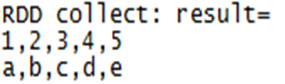
collect:输出所有输出数据
save:保存输出数据至外部存储
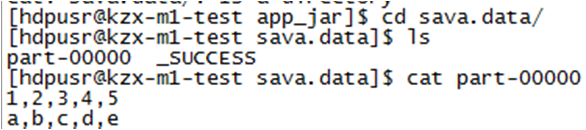
7、WordCount实例

执行结果:

8、广播变量& 累加器
Broadcast variables(广播变量)
Accumulators(累加器)
三、调度机制
1、DAG Scheduler
为每个job分割stage,同时会决定最佳路径,并且DAG Scheduler会记录哪个RDD或者stage的数据被checkpoint,从而找到最优调度方案 (transformations是延迟执行的原因)
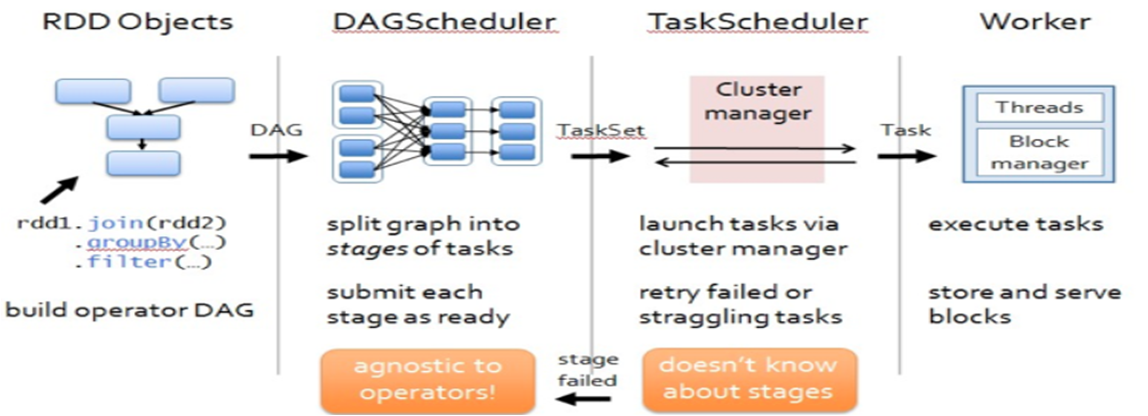
2、DAG Scheduler优化
单个Stage内Pipeline执行
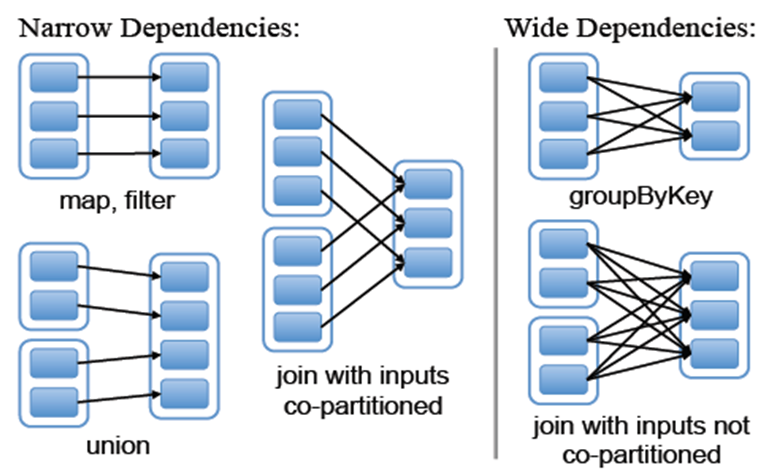
3、窄依赖& 宽依赖
窄依赖:每个子分区只依赖有限数目的父分区
宽依赖:每个子分区只依赖所有的父分区
4、Stage
调度器会在产生宽依赖的地方形成一个stage,同一个stage内的RDD操作会流式执行,不会发生数据迁移。
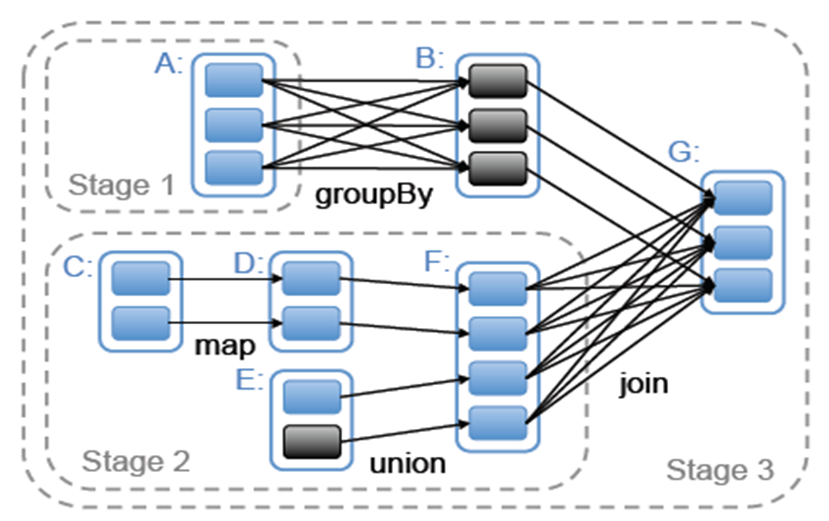
rdd join操作属于宽依赖,从spark产生的日志可以看出需要分3个stage执行
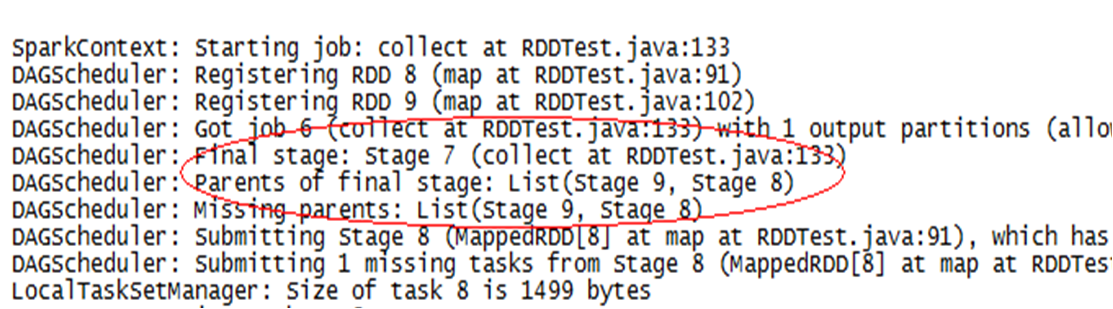
rdd flatMap、Map操作属于窄依赖,从spark产生的日志可以看出需要分1个stage执行

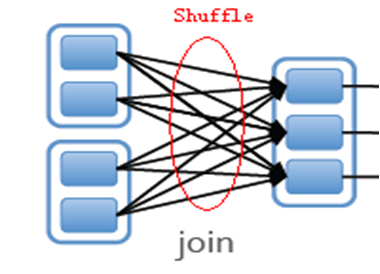
5、Shuffle
每个RDD都可以选择Partitioner进行shuffle操作
shuffle需要在node之间移动数据,会影响spark执行效率,应该尽量避免RDD操作中发生shuffle。