原文引自:http://www.cnblogs.com/shishanyuan/p/4637631.html
1、环境说明
部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
l 虚拟机操作系统: CentOS6.6 64位,单核,1G内存
l JDK:1.7.0_55 64位
l Hadoop:1.1.2
2、HDFS原理
HDFS(Hadoop Distributed File System)是一个分布式文件系统,是谷歌的GFS山寨版本。它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞吐量的海量数据存储解决方案。
l高吞吐量访问:HDFS的每个Block分布在不同的Rack上,在用户访问时,HDFS会计算使用最近和访问量最小的服务器给用户提供。由于Block在不同的Rack上都有备份,所以不再是单数据访问,所以速度和效率是非常快的。另外HDFS可以并行从服务器集群中读写,增加了文件读写的访问带宽。
l高容错性:系统故障是不可避免的,如何做到故障之后的数据恢复和容错处理是至关重要的。HDFS通过多方面保证数据的可靠性,多份复制并且分布到物理位置的不同服务器上,数据校验功能、后台的连续自检数据一致性功能都为高容错提供了可能。
l线性扩展:因为HDFS的Block信息存放到NameNode上,文件的Block分布到DataNode上,当扩充的时候仅仅添加DataNode数量,系统可以在不停止服务的情况下做扩充,不需要人工干预。
2.1HDFS架构

如上图所示HDFS是Master和Slave的结构,分为NameNode、Secondary NameNode和DataNode三种角色。
lNameNode:在Hadoop1.X中只有一个Master节点,管理HDFS的名称空间和数据块映射信息、配置副本策略和处理客户端请求;
lSecondary NameNode:辅助NameNode,分担NameNode工作,定期合并fsimage和fsedits并推送给NameNode,紧急情况下可辅助恢复NameNode;
lDataNode:Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode;
2.2HDFS读操作
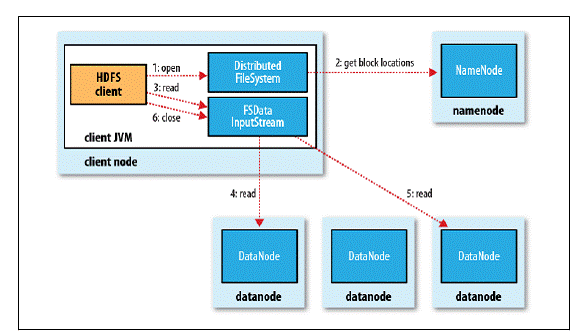
1. 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象时分布文件系统的一个实例;
2. DistributedFileSystem通过使用RPC来调用NameNode以确定文件起始块的位置,同一Block按照重复数会返回多个位置,这些位置按照Hadoop集群拓扑结构排序,距离客户端近的排在前面;
3. 前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流,客户端对这个输入流调用read()方法;
4. 存储着文件起始块的DataNode地址的DFSInputStream随即连接距离最近的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端;
5. 到达块的末端时,DFSInputStream会关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode,这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流;
6. 一旦客户端完成读取,就对FSDataInputStream调用close()方法关闭文件读取。
2.3HDFS写操作
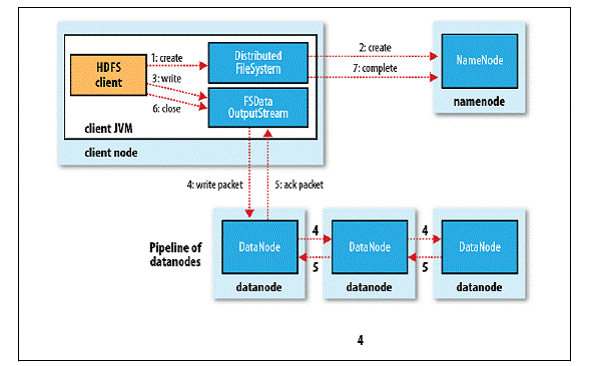
1. 客户端通过调用DistributedFileSystem的create()方法创建新文件;
2. DistributedFileSystem通过RPC调用NameNode去创建一个没有Blocks关联的新文件,创建前NameNode会做各种校验,比如文件是否存在、客户端有无权限去创建等。如果校验通过,NameNode会为创建新文件记录一条记录,否则就会抛出IO异常;
3. 前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream可以协调NameNode和Datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小的数据包,并写入内部队列称为“数据队列”(Data Queue);
4. DataStreamer会去处理接受Data Queue,它先问询NameNode这个新的Block最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的DataNode,把他们排成一个pipeline.DataStreamer把Packet按队列输出到管道的第一个Datanode中,第一个DataNode又把Packet输出到第二个DataNode中,以此类推;
5. DFSOutputStream还有一个对列叫Ack Quene,也是有Packet组成,等待DataNode的收到响应,当Pipeline中的所有DataNode都表示已经收到的时候,这时Akc Quene才会把对应的Packet包移除掉;
6. 客户端完成写数据后调用close()方法关闭写入流;
7. DataStreamer把剩余的包都刷到Pipeline里然后等待Ack信息,收到最后一个Ack后,通知NameNode把文件标示为已完成。
2.4HDFS中常用到的命令
lhadoop fs
hadoop fs -ls /
hadoop fs -lsr
hadoop fs -mkdir /user/hadoop
hadoop fs -put a.txt /user/hadoop/
hadoop fs -get /user/hadoop/a.txt /
hadoop fs -cp src dst
hadoop fs -mv src dst
hadoop fs -cat /user/hadoop/a.txt
hadoop fs -rm /user/hadoop/a.txt
hadoop fs -rmr /user/hadoop/a.txt
hadoop fs -text /user/hadoop/a.txt
hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似。
hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件。
lhadoop fsadmin
hadoop dfsadmin -report
hadoop dfsadmin -safemode enter | leave | get | wait
hadoop dfsadmin -setBalancerBandwidth 1000
lhadoop fsck
lstart-balancer.sh
相关HDFS API可以到Apache官网进行查看:
3、测试例子1
3.1测试例子1内容
在Hadoop集群中编译并运行《权威指南》中的例3.2,读取HDFS文件内容。
3.2 运行代码
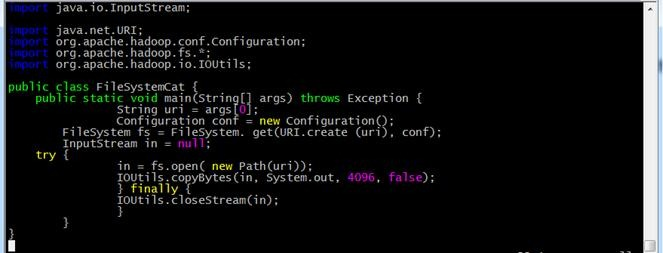
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem. get(URI.create (uri), conf);
InputStream in = null;
try {
in = fs.open( new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
3.3实现过程
3.3.1创建代码目录
使用如下命令启动Hadoop
cd /app/hadoop-1.1.2/bin
./start-all.sh
在/app/hadoop-1.1.2目录下使用如下命令建立myclass和input目录:
cd /app/hadoop-1.1.2
mkdir myclass
mkdir input

3.3.2建立例子文件上传到HDFS中
进入/app/hadoop-1.1.2/input目录,在该目录中建立quangle.txt文件
cd /app/hadoop-1.1.2/input
touch quangle.txt
vi quangle.txt
内容为:
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.

使用如下命令在hdfs中建立目录/class4
hadoop fs -mkdir /class4
hadoop fs -ls /
(如果需要直接使用hadoop命令,需要把/app/hadoop-1.1.2加入到Path路径中)

3.3.3配置本地环境
对/app/hadoop-1.1.2/conf目录中的hadoop-env.sh进行配置,如下如所示:
cd /app/hadoop-1.1.2/conf
sudo vi hadoop-env.sh
加入对HADOOP_CLASPATH变量值,值为/app/hadoop-1.1.2/myclass,设置完毕后编译该配置文件,使配置生效
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/app/hadoop-1.1.2/myclass

3.3.4编写代码
进入/app/hadoop-1.1.2/myclass目录,在该目录中建立FileSystemCat.java代码文件,命令如下:
cd /app/hadoop-1.1.2/myclass/
vi FileSystemCat.java
输入代码内容:
3.3.5编译代码
在/app/hadoop-1.1.2/myclass目录中,使用如下命令编译代码:
javac -classpath ../hadoop-core-1.1.2.jar FileSystemCat.java
ls

3.3.6使用编译代码读取HDFS文件
使用如下命令读取HDFS中/class4/quangle.txt内容:
hadoop FileSystemCat /class4/quangle.txt

4、测试例子2
4.1测试例子2内容
在本地文件系统生成一个大约100字节的文本文件,写一段程序读入这个文件并将其第101-120字节的内容写入HDFS成为一个新文件。
4.2运行代码
注意:在编译前请先删除中文注释!