前言:
Spark Application的运行架构由两部分组成:driver program(SparkContext)和executor。Spark Application一般都是在集群中运行,比如Spark Standalone,YARN,mesos,这些集群给spark Application提供了计算资源和这些资源管理,这些资源既可以给executor运行,也可以给driver program运行。根据Spark Application的driver program是否在资源集群中运行,Spark
Application的运行方式又可以分为Cluster模式和client模式。spark1.0.0提供了一个Spark Application的部署工具bin/spark-submit。
1.1基本术语
关于Application中的几个概念如下图所示: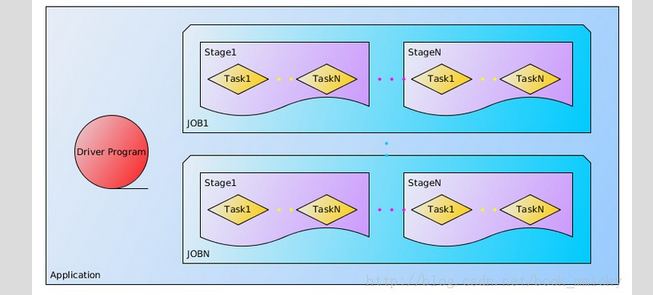
Application:基于Spark的用户程序,包含了一个driver program和集群中多个的
executor
Driver progaram:运行Application的main()函数并且创建SparkContext,通常用SparkContext代表Driver Program。
Cluster Manager:在集群上获取资源的外部服务(例如:Standalone,Mesos,Yarn)
Worker Node:集群中任何可以运行Application代码的节点
Executor:是为某Application运行在worker node上的一个进程,该进程负责运行
Task,并且负责将数据存在内存或者磁盘上。每个Application都有个字独立的executors。
Task: 被送到某个executor上的工作单元
Job: 包含多个Task组成的并行计算,往往由Spark action催生,该术语可以经常在日志中看到。
Stage:
每个Job会被拆分很多组task,每组任务被称为Stage,也可称TaskSet,该术语可以经常在日志中看到。
RDD:Spark的基本计算单元,可以通过一系列算子进行操作(主要有Transformation和Action操作),详情见RDD
细解、Spark1.0.0编程模型。
DAG Scheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,详见DAG
Scheduler 细解。
TaskScheduler:将Taskset提交给worker(集群)运行并回报结果,详见TaskScheduler
细解。
1.2Spark运行模式概述
Spark运行模式多种多样,在单机上可以以本地模式运行,也可以以伪分布式模式运行。
而当以分布式的方式在cluster集群中运行时,底层的资源管理器可以使用Spark自带的standalone模式,也可以使用Yarn或者Mesos模式。
Spark的运行模式主要取决于传递给SparkContext的deploy-mode和Master变量的值,个别模式还需要辅助的程序接口来配合使用。目前Master有local,yarn-client,yarn-client,spark(standalone),mesos模式,而deploy-mode必须是client(默认方式)或cluster中的一种。
1.3Spark的基本工作流程
Spark的Application在运行时,首先在Driver程序中创建SparkContext,将其作为调度的总入口,在其初始化的过程中会分别创建DAGSchedule(进行Stage调度)和TaskSchedule(进行Task调度)两个模块。DAGSchedule模块是基于Stage的调度模块,它为每个Spark job计算具有依赖关系的多个Stage任务阶段然后将每个Stage划分为一组具体的任务以TaskSet的
形式提交给底层的TaskSchedule模块来具体执行。TaskSchedule负责具体启动任务,监控和汇报任务的运行情况。而任务运行所需的资源需要向Cluster Manager申请。