一、如何选择合适的列建立索引
- 在where从句,group by从句,order by从句,on从句中出现的列
- 索引字段越小越好
- 离散度大的列放到联合索引的前面
explain select * from payment where staff_id=2 and customer_id=584; -- 思考: index(staff_id,customer_id)好?还是index(customer_id,staff_id)好? select count(distinct customer_id),count(distinct staff_id) from payment; +-----------------------------+--------------------------+ | count(distinct customer_id) | count(distinct staff_id) | +-----------------------------+--------------------------+ | 599 | 2 | +-----------------------------+--------------------------+ -- 由于customer_id的离散度更大(重复率小,可选择性更大),所以应该使用 index(customer_id,staff_id)
二、索引的维护
1、重复及冗余索引
-- 冗余索引是指多个索引的前缀列相同,或是在联合索引中包含了主键的索引。如下:key(name,id)就是一 个冗余索引 -- 可以删除冗余索引,达到优化效果。 create table test( id int not null primary key, name varchar(10) not null, key(name,id) )engine=innodb;
2、检查重复及冗余索引
使用pt-duplicate-key-checker工具检查重复及冗余索引,安装如下:
wget http://www.percona.com/downloads/percona-toolkit/2.2.4/percona-toolkit-2.2.4.tar.gz tar -xzvf percona-toolkit-2.2.4.tar.gz cd percona-toolkit-2.2.4 perl Makefile.PL make && make install #如果报错(Can't locate Time/HiRes.pm in @INC (@INC contains....) yum -y install perl-Time-HiRes #如果报错: Cannot connect to MySQL because the Perl DBD::mysql module is not installed or not found. yum -y install perl-DBD-mysql
使用:
pt-duplicate-key-checker -h127.0.0.1 -uroot -proot
#指定数据库 pt-duplicate-key-checker -h127.0.0.1 -uroot -proot -dsakila
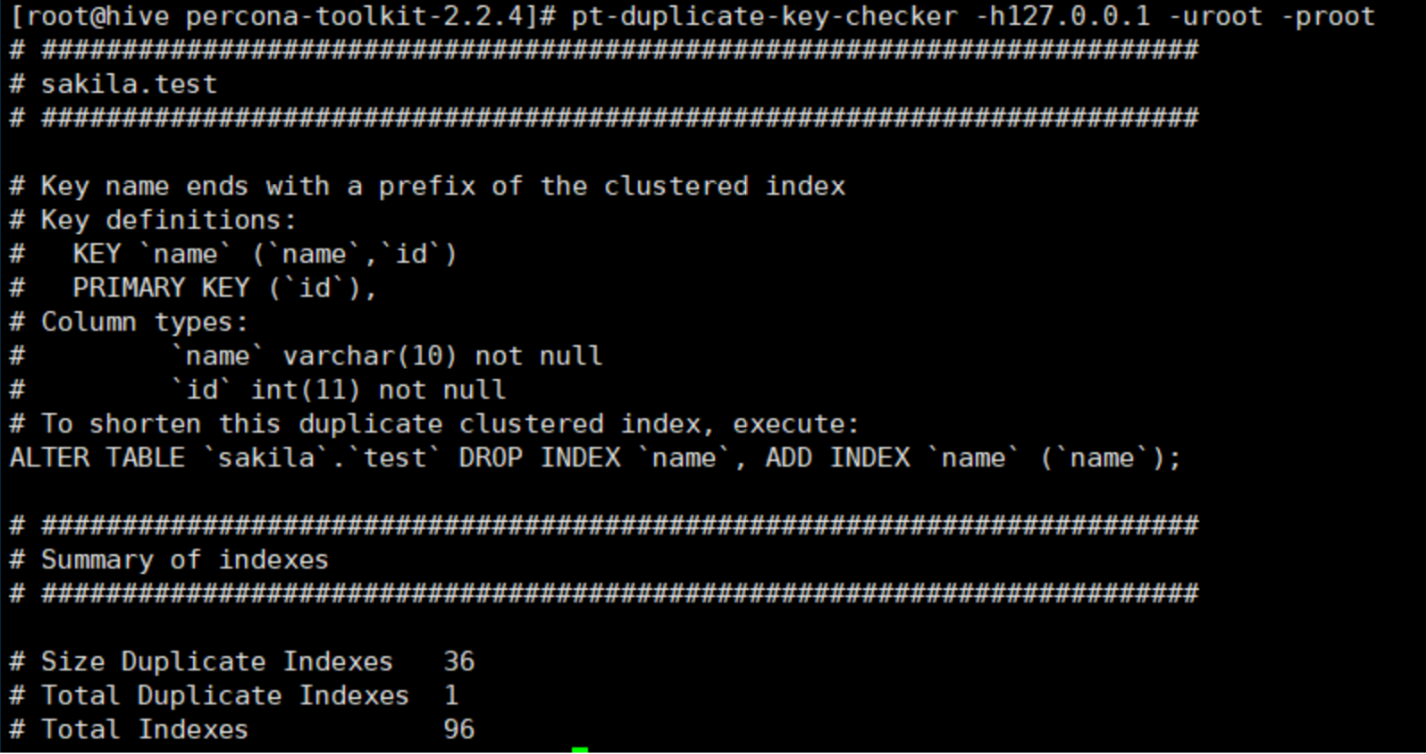
3、删除不用索引
在mysql中可以通过慢查日志配合pt-index-usage工具来进行索引使用情况分析。
pt-index-usage -h127.0.0.1 -uroot -proot /data/mysql/hive-slow.log

三、SQL优化(慢查询)
1、慢查询
如何发现有问题的SQL?我们可以 使用Mysql慢查询日志对有效率问题的SQL进行监控。
-- 查看包含log的参数 show variables like '%log%'; -- 查看慢查询日志是否开启 show variables like 'slow_query_log'; -- 查看慢查询日志存储位置 show variables like 'slow_query_log_file'; -- 开启慢查询日志 set global slow_query_log=on; -- 指定慢查询日志存储位置 set global show_query_log_file='/data/mysql/hive-slow.log'; -- 记录没有使用索引的sql 开启慢查询日志 set global log_queries_not_using_indexes=on; -- 查看慢查询设置的时间 超过此时间记录到慢查询日志中 show variables like 'long_query_time'; #记录查询超过1s的sql set global long_query_time=1;
如:

测试:
-- 执行sql select sleep(3);
#查看日志 [root@hive ~]# tail -f /data/mysql/hive-slow.log /root/mysql/bin/mysqld, Version: 5.6.38 (MySQL Community Server (GPL)). started with: Tcp port: 3306 Unix socket: /tmp/mysql.sock Time Id Command Argument # Time: 190708 9:38:47 # User@Host: root[root] @ [192.168.3.36] Id: 40 //执行sql的主机信息 # Query_time: 3.000991 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0 //sql的执行信息 SET timestamp=1562593127; //sql执行时间 select sleep(3); //sql的内容
2、慢查询日志分析工具 mysqldumpslow
安装完MySQL后,默认就带了mysqldumpslow,mysql官方提供的一个常用工具。
-- 查看参数列表
mysqldumpslow -h -- 分析慢查询日志中前三条比较慢的sql mysqldumpslow -t 3 /data/mysql/hive-slow.log | more
输出效果:
[root@hive ~]# mysqldumpslow -t 3 /data/mysql/hive-slow.log | more Reading mysql slow query log from /data/mysql/hive-slow.log Died at /root/mysql/bin/mysqldumpslow line 161, <> chunk 1. Count: 1 Time=3.00s (3s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@[192.168.3.36] select sleep(N)
3、慢查询日志分析工具pt-query-digest
分析结果比mysqldumpslow更详细全面,它可以分析binlog、General log、slowlog, 安装 :
wget percona.com/get/pt-query-digest chmod u+x pt-query-digest mv /root/pt-query-digest /usr/bin/ #如果出现Can't locate Time/HiRes.pm in @INC 错误 yum -y install perl-Time-HiRes
#查看参数列表
pt-query-digest --help [root@hive bin]# pt-query-digest /data/mysql/hive-slow.log | more # 50ms user time, 50ms system time, 20.09M rss, 165.33M vsz # Current date: Mon Jul 8 10:35:26 2019 # Hostname: hive # Files: /data/mysql/hive-slow.log # Overall: 1 total, 1 unique, 0 QPS, 0x concurrency ______________________ # Time range: all events occurred at 2019-07-08 09:38:47 # Attribute # ============ # Exec time #Locktime 0000000 #Rowssent 1111101 #Rowsexamine 0000000 # Query size 15 15 15 15 15 0 15 total min max avg 95% stddev median ======= ======= ======= ======= ======= ======= ======= 3s 3s 3s 3s 3s 0 3s # Profile # Rank Query ID Response time Calls R/Call V/M # ==== ================================== ============= ===== ====== ===== # 1 0x59A74D08D407B5EDF9A57DD5A41825CA 3.0010 100.0% 1 3.0010 0.00 SELECT # Query 1: 0 QPS, 0x concurrency, ID 0x59A74D08D407B5EDF9A57DD5A41825CA at byte 0 # This item is included in the report because it matches --limit. # Scores: V/M = 0.00 # Time range: all events occurred at 2019-07-08 09:38:47 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 100 1 # Exec time 100 3s 3s #Locktime 0 0 0 #Rowssent 100 1 1 #Rowsexamine0 0 0 # Query size # String: # Hosts 192.168.3.36 # Users root # Query_time distribution # 1us # 10us # 100us # 1ms # 10ms # 100ms # 1s ################################################################ # 10s+ # EXPLAIN /*!50100 PARTITIONS*/ select sleep(3)G
输出分为三部分:
- 显示除了日志的时间范围,以及总的sql数量和不同的sql数量
- Response Time:响应时间占比 Calls:sql执行次数
- sql的具体日志
如何通过慢查询日志发现有问题的SQL?
- 查询次数多且每次查询占用时间长的SQL:通常为pt-query-digest分析的前几个查询
- IO大的SQL(数据库主要瓶颈出现在IO层次):注意pt-query-digest分析中的Rows examine项
- 未命中索引的SQL:注意pt-query-digest分析中的Rows examine和Rows Sent的对比
四、常见优化实例
1、Count()和Max()的优化
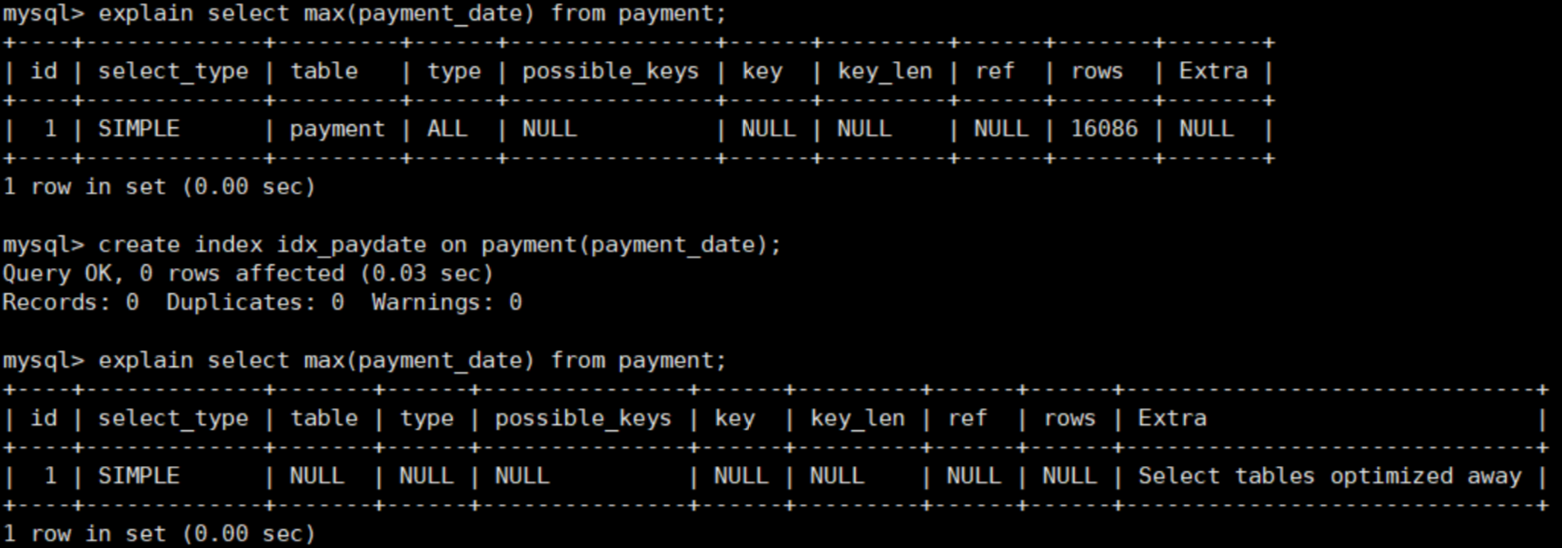
-- 查询最后支付时间--优化max()函数 explain select max(payment_date) from payment;
-- 给payment_date建立索引(覆盖索引) create index idx_paydate on payment(payment_date);
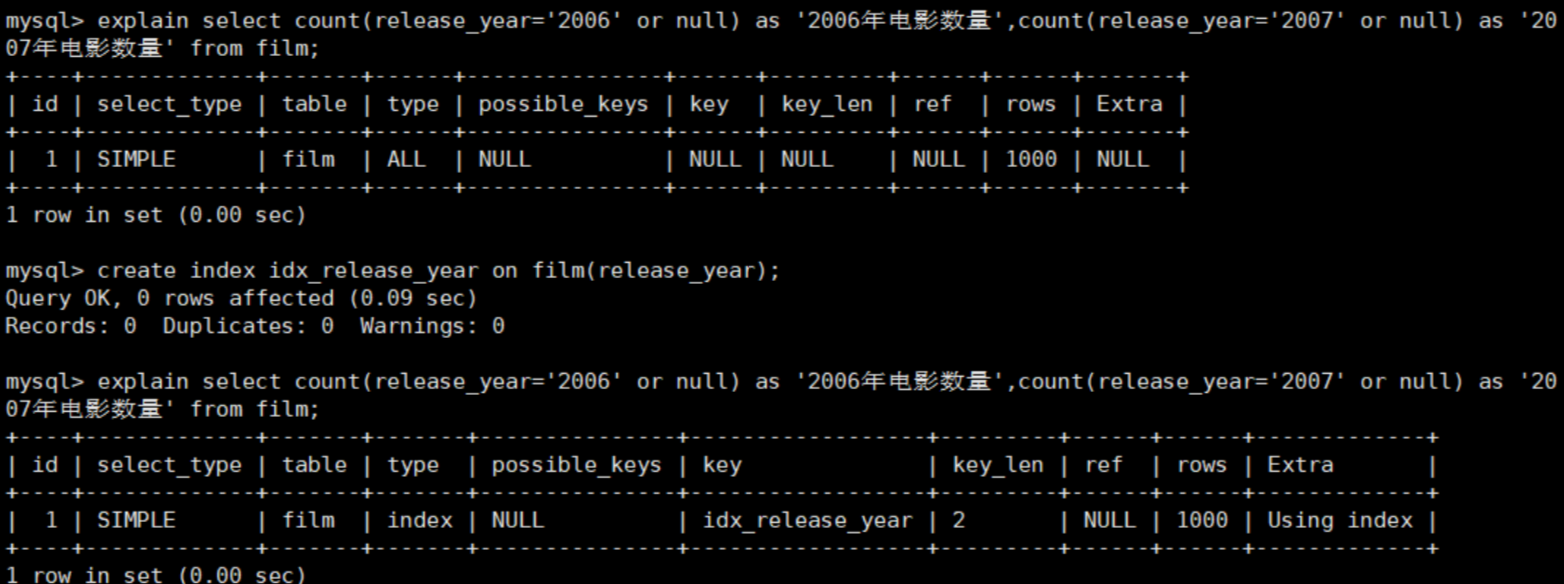
-- 删除索引 drop index idx_release_year on payment; -- 显示索引 show index from payment; -- 在一条SQL中同时查出2006年和2007年电影的数量--优化Count()函数 -- count('任意内容')都会统计出所有记录数,因为count只有在遇见null时不计数,即 count(null)==0 explain select count(release_year='2006' or null) as '2006年电影数 量',count(release_year='2007' or null) as '2007年电影数量' from film; -- 优化,为release_year列设置索引 create index idx_release_year on film(release_year);
2、子查询优化
通常情况下,需要把子查询优化为join查询,但在优化时要注意关联键是否有一对多的关系,要注意重复数据。
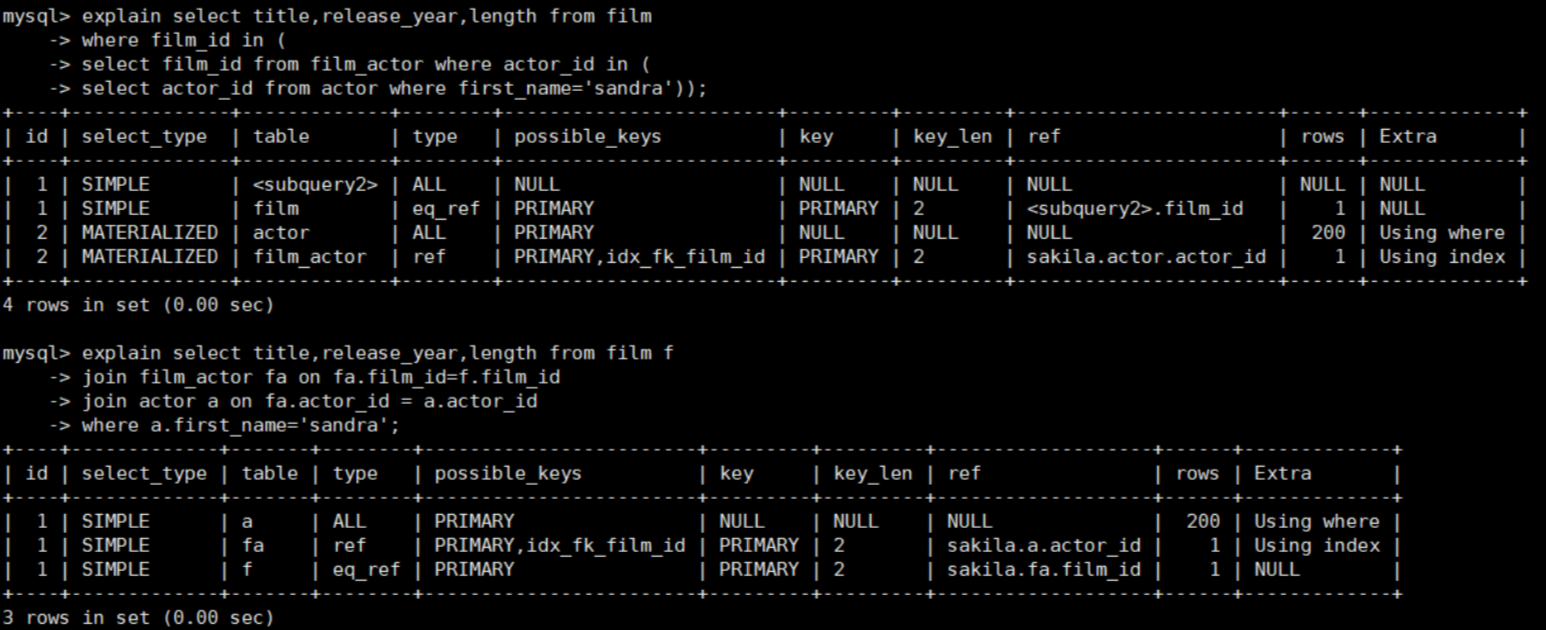
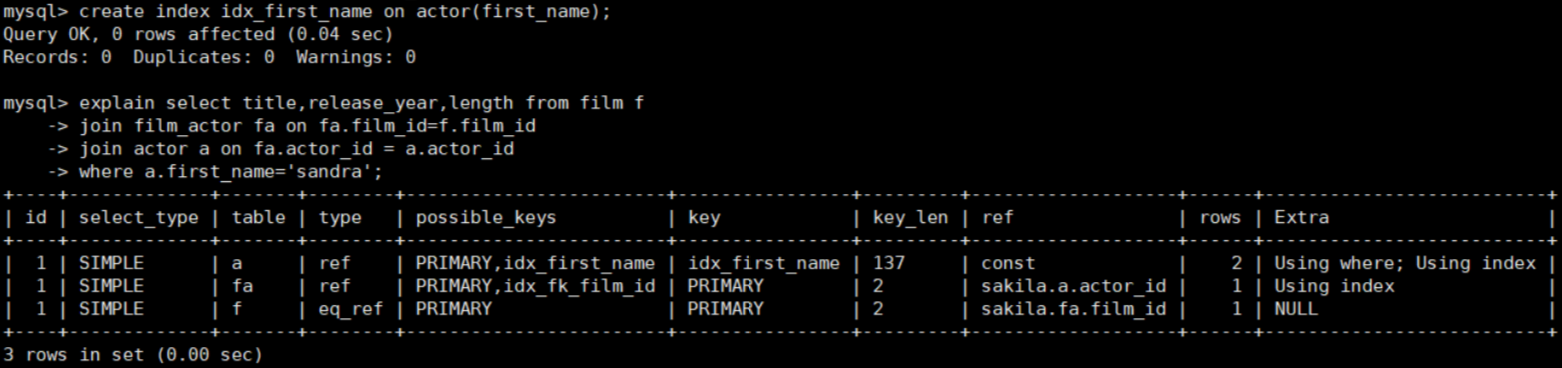
-- 查询sandra出演的所有影片 explain select title,release_year,length from film where film_id in ( select film_id from film_actor where actor_id in ( select actor_id from actor where first_name='sandra')); -- 优化之后 explain select title,release_year,length from film f join film_actor fa on fa.film_id=f.film_id join actor a on fa.actor_id = a.actor_id where a.first_name='sandra';
继续优化,将first_name设为索引:
create index idx_first_name on actor(first_name);
3、group by的优化
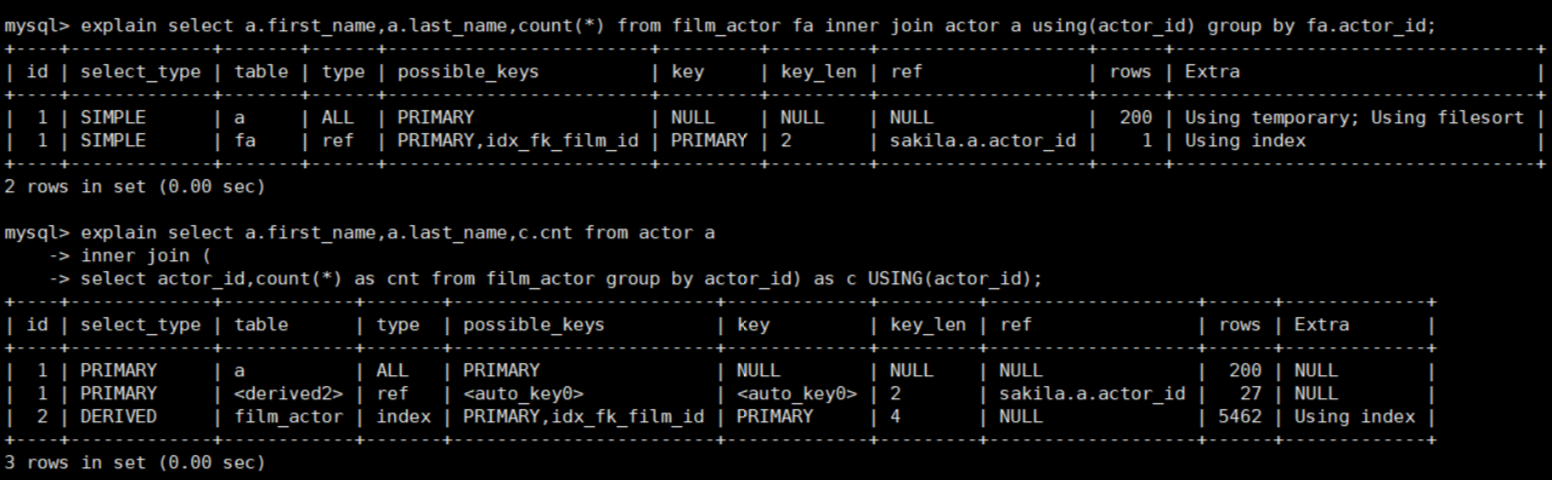
优化策略: 先给分组字段建索引;再对该表分组、分组后再和其他表关联查询
-- 每个演员参与影片的数量 explain select a.first_name,a.last_name,count(*) from film_actor fa inner join actor a using(actor_id) group by fa.actor_id; -- 优化后 子查询 索引 explain select a.first_name,a.last_name,c.cnt from actor a inner join ( select actor_id,count(*) as cnt from film_actor group by actor_id) as c USING(actor_id)
4、limit优化
limit常用于分页处理,时常会伴随order by 从句使用,因此大多时候会使用Filesorts这样会造成大量的IO问题。
避免数据量大时扫描过多的记录:
-- 分页查询影片描述信息 explain select film_id,description from film order by title limit 50,5; -- 优化1:使用有索引的列或主键进行order by操作(order by film_id) -- 页数越大,rows越大 explain select film_id,description from film order by film_id limit 50,5; -- 优化2:记录上次返回的主键,在下次查询的时候用主键过滤,避免了数据量大时扫描过多的记录 -- 注意要求有序主键 或者建立有序辅助索引列 explain select film_id,description from film where film_id>55 and film_id<=60 order by film_id limit 1,5;

5、in和exsits优化
原则:小表驱动大表,即小的数据集驱动大的数据集
- in:当B表的数据集必须小于A表的数据集时,in优于exists:select * from A where id in (select id from B);
explain select * from film where id in(select film_id from film_actor);

- exists:当A表的数据集小于B表的数据集时,exists优于in。将主查询A的数据,放到子查询B中做条件验证,根据验证结果(true或false)来决定主查询的数据是否保留:
select * from A where exists (select 1 from B where B.id = A.id) -- A表与B表的ID字段应建立索引
explain select * from film where exists (select 1 from film_actor where film_actor.film_id = film.id)

注意:
- EXISTS (subquery)只返回TRUE或FALSE,因此子查询中的SELECT * 也可以是SELECT 1或select X,官方说法是实际执行时会忽略SELECT清单,因此没有区别;
- EXISTS子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比;
- EXISTS子查询往往也可以用JOIN来代替,何种最优需要具体问题具体分析。
6、join
对连接属性进行排序时,应当选择驱动表的属性作为排序表中的条件
explain select * from film join film_actor on film_actor.film_id=film.id order by film.id;

explain select * from film join film_actor on film_actor.film_id=film.id order by film_actor.film_id;

explain select name from film join film_actor on film_actor.film_id=film.id order by film_actor.film_id;
