引言
深度学习背后的主要原理是从大脑中汲取灵感。,这种观点产生了“神经网络”术语,大脑包含数十亿个神经元,它们之间有数万个连接。 在许多情况下,深度学习算法类似于大脑,因为大脑和深度学习模型都涉及大量的计算单元(神经元),这些单元在未激活时并不是活跃的,它们彼此交互时会变得智能化。
神经元
神经网络的基本构建模块是人工神经元--模仿人类大脑神经元。 这些是强大的计算单元,具有加权输入信号并使用激活功能产生输出信号。 这些神经元分布在神经网络的几个层中。

什么网络是如何工作的?
深度学习由人工神经网络组成,这些网络以人脑中存在的类似网络为模型。 当数据通过这个人工网格时,每个层处理数据的一个方面,过滤异常值,找到合适的实体,并产生最终输出。

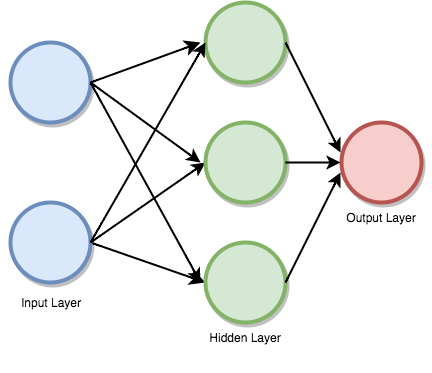
- 输入层(Input Layer):该层由神经元组成,它们不接收输入并将其传递给其他层。 输入层中的元素应等于数据集中的属性(即变量个数)。
- 输出图层(Output Layer):输出图层是预测的特征,它主要取决于模型的类型。
- 隐藏层(Hidden Layer):在输入和输出层之间,将存在基于模型类型的隐藏层。 隐藏层包含大量神经元。 隐藏层中的神经元将变换应用于输入。 随着网络的训练,权重得到更新,更具预测性。
神经元的权重
权重是指两个神经元之间连接的强度或幅度,如果您熟悉线性回归,则可以比较输入的权重,例如我们在回归方程中使用的系数。权重通常被初始化为较小的随机值,例如 在0到1之间。
前馈深度网络
前馈监督神经网络是第一个也是最成功的学习算法。 它们也被称为深度网络,多层感知器(MLP)或简单的神经网络,并且显示出了具有单个隐藏层的连接体系结构。
网络处理输入变量,并向后传递,激活神经元,最终产生输出值。这被称为网络上的前向传递。
激活函数
激活函数是加权输入与神经元输出的加和的映射。 它被称为激活或者传递函数,因为它控制激活神经元的初始值和输出信号的强度。
表达式:
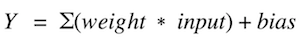
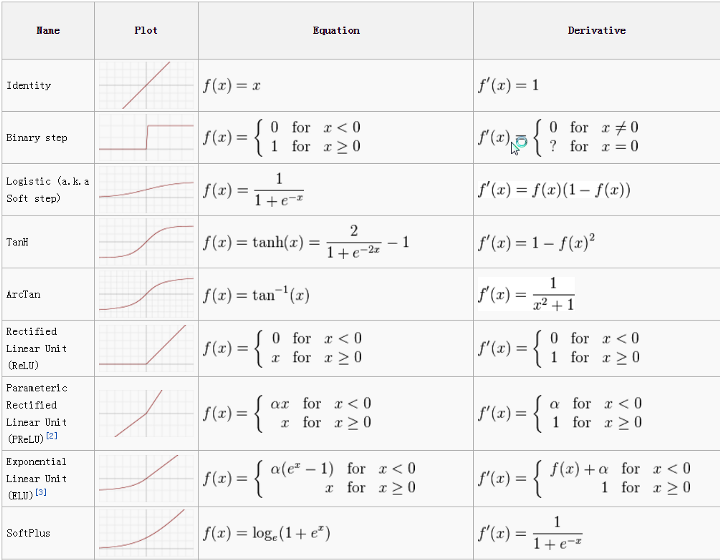
常用的有:
反向传播
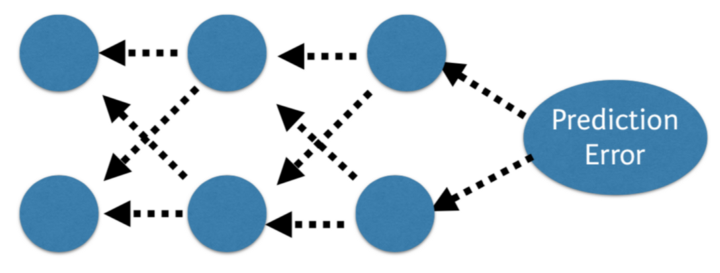
将网络的预测值与预期输出进行比较,并使用函数计算误差, 然后,该错误在整个网络内传播回来,一次一层,并根据它们对错误的贡献值更新权重。 这个聪明的数学运算称为反向传播算法。 对训练数据中的所有示例重复该过程。 为整个训练数据集更新网络的一轮称为纪元。 可以训练网络数十,数百或数千个时期。
成本函数和梯度下降
成本函数是神经网络对其给定的训练输入和预期输出所做的“有多好”的度量。 它还可能取决于权重和偏差等属性。
成本函数是单值的,而不是向量,因为它评估神经网络作为一个整体执行得有多好。 使用梯度下降优化算法,在每个时期之后递增地更新权重。
成本函数:
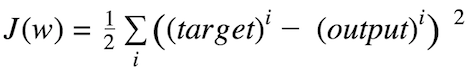
通过在成本梯度的相反方向上采取步骤来计算权重更新的大小和方向。

其中Δw是包含每个权重系数w的权重更新的向量,其计算如下:
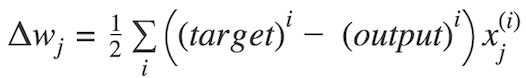
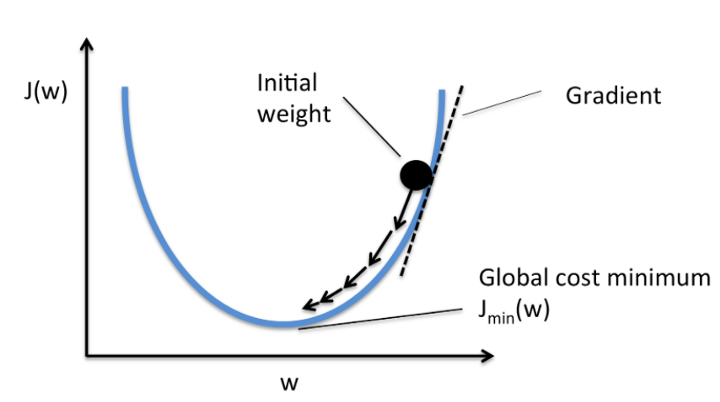
我们计算梯度下降直到导数达到最小误差,并且每个步骤由斜率(梯度)的陡度确定。
多层感知器(前向传播)
这类网络由多层神经元组成,通常以前馈方式互连(向前移动)。一层中的每个神经元具有与后续层的神经元的直接连接。在许多应用中,这些网络的单元应用sigmoid或ReLU作为激活功能。
现在考虑一个问题,找出交易数量,给定帐户和家庭成员作为输入。
首先要解决这个问题,我们需要从创建前向传播神经网络开始。我们的输入图层将是家庭成员和帐户的数量,隐藏图层的数量是一个,输出图层将是交易数量。
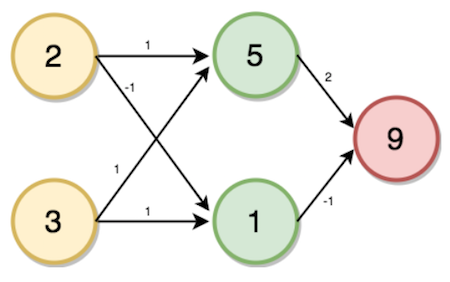
给定权重,如图所示,从输入层到隐藏层,其中家庭成员2的数量和账户数量3作为输入。
现在,将通过以下步骤使用前向传播来计算隐藏层(i,j)和输出层(k)的值。
处理过程
- 乘法 - 添加过程。
- 点积(输入*权重)。
- 一次一个数据点的前向传播。
- 输出是该数据点的预测。
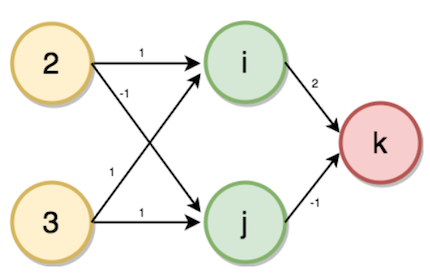
$i$的值将根据输入值和与所连接的神经元相对应的权重来计算。
$i = (2 * 1) + (3 * 1)$
→ i = 5
类似的,
$j = (2 * -1) + (3 * 1)$
→ j = 1
$K = (5 * 2) + (1 * -1)$
→ k = 9
python 实现
为了使神经网络达到最大预测能力,我们需要为隐藏层应用激活函数。它用于捕获非线性。 我们将它们应用于输入层,隐藏层以及值上的某些方程式。
这里我们使用ReLU激活函数。
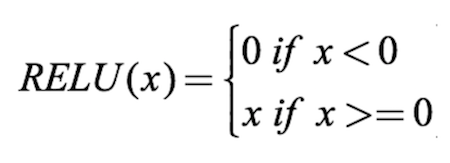
import numpy as np def relu(input): # Rectified Linear Activation output = max(input, 0) return(output) print("Enter the two values for input layers") a = int(input()) b = int(input()) input_data = np.array([a, b]) weights = { 'node_0': np.array([1, 1]), 'node_1': np.array([-1, 1]), 'output_node': np.array([2, -1]) } node_0_input = (input_data * weights['node_0']).sum() node_0_output = relu(node_0_input) node_1_input = (input_data * weights['node_1']).sum() node_1_output = relu(node_1_input) hidden_layer_outputs = np.array([node_0_output, node_1_output]) model_output = (hidden_layer_outputs * weights['output_node']).sum() print(model_output)
输出:
Enter the two values for input layers 2 3 9