简单描述
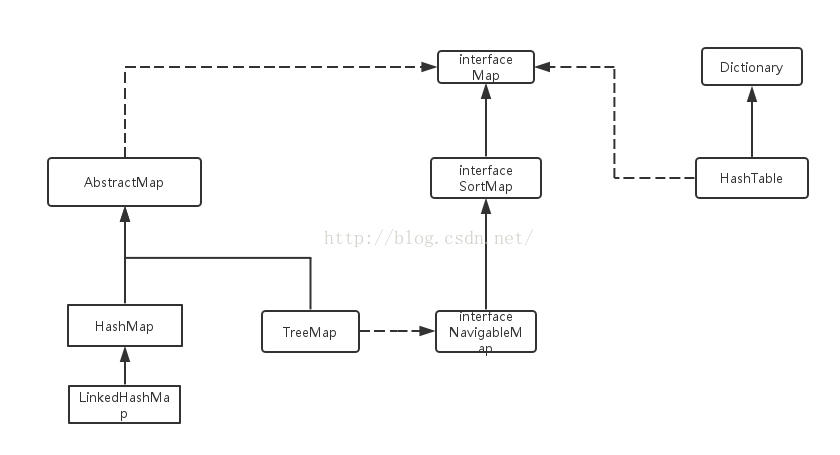
Map是键值对的集合接口,它的实现类主要包括:HashMap,TreeMap,HashTable以及LinkedHashMap等。
TreeMap:能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
HashMap的值是没有顺序的,它是按照key的HashCode来实现的,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为Null(多条会覆盖);允许多条记录的值为 Null。非同步的。
Map.Entry返回Collections视图。
注:map简单的UML
HashMap
按照插入key的hashcode值进行数组排序的,插入排序,不保证稳定性。
TreeMap
接收的comparator的接口默认是key值的排序,源代码如下:
/**
* Constructs a new, empty tree map, ordered according to the given
* comparator. All keys inserted into the map must be <em>mutually
* comparable</em> by the given comparator: {@code comparator.compare(k1,
* k2)} must not throw a {@code ClassCastException} for any keys
* {@code k1} and {@code k2} in the map. If the user attempts to put
* a key into the map that violates this constraint, the {@code put(Object
* key, Object value)} call will throw a
* {@code ClassCastException}.
*
* @param comparator the comparator that will be used to order this map.
* If {@code null}, the {@linkplain Comparable natural
* ordering} of the keys will be used.
*/
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
注:java8 在Map接口中的Entry接口中实现了根据key、value排序的接口,源代码如下:
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
LinkedHashMap
重写了Entry实现类,实现成双向链表的类型结构,会存取borfer和after的元素,插入的时候把当前元素插入到链表头部,
继承自HashMap,一个有序的Map接口实现,这里的有序指的是元素可以按插入顺序或访问顺序排列;
与HashMap的异同:同样是基于散列表实现,区别是,LinkedHashMap内部多了一个双向循环链表的维护,该链表是有序的,可以按元素插入顺序或元素最近访问顺序(LRU)排列,
简单地说:LinkedHashMap=散列表+循环双向链表
package java.util;
import java.io.*;
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
private static final long serialVersionUID = 3801124242820219131L;
/**
* 双向循环链表, 头结点(空节点)
*/
private transient Entry<K,V> header;
/**
* accessOrder为true时,按访问顺序排序,false时,按插入顺序排序
*/
private final boolean accessOrder;
/**
* 生成一个空的LinkedHashMap,并指定其容量大小和负载因子,
* 默认将accessOrder设为false,按插入顺序排序
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
/**
* 生成一个空的LinkedHashMap,并指定其容量大小,负载因子使用默认的0.75,
* 默认将accessOrder设为false,按插入顺序排序
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
/**
* 生成一个空的HashMap,容量大小使用默认值16,负载因子使用默认值0.75
* 默认将accessOrder设为false,按插入顺序排序.
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
/**
* 根据指定的map生成一个新的HashMap,负载因子使用默认值,初始容量大小为Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,DEFAULT_INITIAL_CAPACITY)
* 默认将accessOrder设为false,按插入顺序排序.
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
/**
* 生成一个空的LinkedHashMap,并指定其容量大小和负载因子,
* 默认将accessOrder设为true,按访问顺序排序
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
/**
* 覆盖HashMap的init方法,在构造方法、Clone、readObject方法里会调用该方法
* 作用是生成一个双向链表头节点,初始化其前后节点引用
*/
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
/**
* 覆盖HashMap的transfer方法,性能优化,这里遍历方式不采用HashMap的双重循环方式
* 而是直接通过双向链表遍历Map中的所有key-value映射
*/
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍历旧Map中的所有key-value
for (Entry<K,V> e = header.after; e != header; e = e.after) {
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
//根据新的数组长度,重新计算索引,
int index = indexFor(e.hash, newCapacity);
//插入到链表表头
e.next = newTable[index];
//将e放到索引为i的数组处
newTable[index] = e;
}
}
/**
* 覆盖HashMap的transfer方法,性能优化,这里遍历方式不采用HashMap的双重循环方式
* 而是直接通过双向链表遍历Map中的所有key-value映射,
*/
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}
/**
* 通过key获取value,与HashMap的区别是:当LinkedHashMap按访问顺序排序的时候,会将访问的当前节点移到链表尾部(头结点的前一个节点)
*/
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
/**
* 调用HashMap的clear方法,并将LinkedHashMap的头结点前后引用指向自己
*/
public void clear() {
super.clear();
header.before = header.after = header;
}
/**
* LinkedHashMap节点对象
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// 节点前后引用
Entry<K,V> before, after;
//构造函数与HashMap一致
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
/**
* 移除节点,并修改前后引用
*/
private void remove() {
before.after = after;
after.before = before;
}
/**
* 将当前节点插入到existingEntry的前面
*/
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
/**
* 在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
* 在LinkedHashMap中,当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),否则不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//当LinkedHashMap按访问排序时
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
//迭代器
private abstract class LinkedHashIterator<T> implements Iterator<T> {
//初始化下个节点引用
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* 用于迭代期间快速失败行为
*/
int expectedModCount = modCount;
//链表遍历结束标志,当下个节点为头节点的时候
public boolean hasNext() {
return nextEntry != header;
}
//移除当前访问的节点
public void remove() {
//lastReturned会在nextEntry方法中赋值
if (lastReturned == null)
throw new IllegalStateException();
//快速失败机制
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
//迭代器自身删除节点,并不是其他线程修改Map结构,所以这里要修改expectedModCount
expectedModCount = modCount;
}
//返回链表下个节点的引用
Entry<K,V> nextEntry() {
//快速失败机制
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
//链表为空情况
if (nextEntry == header)
throw new NoSuchElementException();
//给lastReturned赋值,最近一个从迭代器返回的节点对象
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
//key迭代器
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
//value迭代器
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
//key-value迭代器
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}
// 返回不同的迭代器对象
Iterator<K> newKeyIterator() { return new KeyIterator(); }
Iterator<V> newValueIterator() { return new ValueIterator(); }
Iterator<Map.Entry<K,V>> newEntryIterator() { return new EntryIterator(); }
/**
* 创建节点,插入到LinkedHashMap中,该方法覆盖HashMap的addEntry方法
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// 注意头结点的下个节点即header.after,存放于链表头部,是最不经常访问或第一个插入的节点,
//有必要的情况下(如容量不够,具体看removeEldestEntry方法的实现,这里默认为false,不删除),可以先删除
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
/**
* 创建节点,并将该节点插入到链表尾部
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//将该节点插入到链表尾部
e.addBefore(header);
size++;
}
/**
* 该方法在创建新节点的时候调用,
* 判断是否有必要删除链表头部的第一个节点(最不经常访问或最先插入的节点,由accessOrder决定)
*/
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
重写了Iterator的实现LinkedHashIterator,遍历的时候按照双向链表的顺序进行遍历,不是按照桶里数组的顺序进行遍历(HashMap).
AbstractMap中的toString方法即调用的entrySet()方法,进行的遍历打印的值。
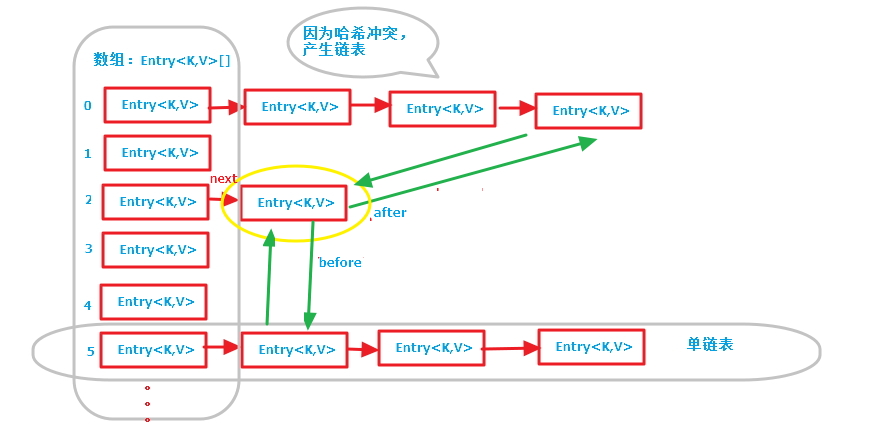
图解:
第一张图是LinkedHashMap的全部数据结构,包含散列表和循环双向链表,由于循环双向链表线条太多了,不好画,简单的画了一个节点(黄色圈出来的)示意一下,注意左边的红色箭头引用为Entry节点对象的next引用(散列表中的单链表),绿色线条为Entry节点对象的before, after引用(循环双向链表的前后引用);