事物
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> exec
1) (integer) 2
2) (integer) 3
3) (integer) 4
multi指示事物的开始,exec指示事物的执行,discard指示事物的丢弃
特殊原子性
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set notes iamastring
QUEUED
127.0.0.1:6379> incr notes
QUEUED
127.0.0.1:6379> set poorman iamdesperate
QUEUED
127.0.0.1:6379> exec
1) OK
2) (error) ERR value is not an integer or out of range
3) OK
127.0.0.1:6379> get notes
"iamastring"
127.0.0.1:6379> get poorman
"iamdesperate"
如上示例,虽然在执行中报错了,但是后面的指令还继续执行,redis的事物不能算原子性,仅仅满足了事物的隔离性,隔离型中的串行化——当前执行的事物有着不被其他事物打断的权利。
discard
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> incr books
(integer) 1
127.0.0.1:6379> get books
"1"
可以丢弃之前所有指令。
watch
redis的watch是一种乐观锁,使用方式 伪代码 如下:
while True:
do_watch()
commands()
multi()
send_commands()
try:
exec()
break
except WatchError:
continue
watch会在事物开始前,盯住1个活多个关键变量,当事物执行时,也就是服务器收到了exec指令要顺序执行缓存的事物队列,redis会检查关键变量自watch之后,是否被修改了,如果被人动过了,exec就会返回null告诉客户端执行失败。
127.0.0.1:6379> watch books
OK
127.0.0.1:6379> incr books
(integer) 2
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> exec // 从watch到exec这期间,books被修改,所以exec失败
(nil)
127.0.0.1:6379> get books
"2"
- 注意:redis禁止在multi和exec之间执行watch命令,否则会报错。
发布订阅
订阅
> subscribe codehole.image codehole.text codehole.blog
1) "subscribe"
2) "codehole.image" 3) (integer) 1
1) "subscribe"
2) "codehole.text" 3) (integer) 2
1) "subscribe"
2) "codehole.blog" 3) (integer) 3
发布
publish codehole.blog '{"content": "hello, everyone", "title": "welcome"}'
消息结构
{'pattern': None, 'type': 'subscribe', 'channel': 'codehole', 'data': 1L}
- data:信息的内容,一个字符串
- channel:当前订阅的主题
- type:消息的类型,普通的消息就是message,如果是控制消息,比如订阅指令的反馈就是subscribe,如果是模式订阅反馈,就是psubscribe
- patter:表示当前消息是那种模式订阅得到的,如果是subscribe指令订阅的,这个字段就为空。
内存
内存回收机制
Redis 并不总是可以将空闲内存立即归还给操作系统。
如果当前 Redis 内存有 10G,当你删除了 1GB 的 key 后,再去观察内存,你会发现 内存变化不会太大。原因是操作系统回收内存是以页为单位,如果这个页上只要有一个 key 还在使用,那么它就不能被回收。Redis 虽然删除了 1GB 的 key,但是这些 key 分散到了 很多页面中,每个页面都还有其它 key 存在,这就导致了内存不会立即被回收。
不过,如果你执行 flushdb,然后再观察内存会发现内存确实被回收了。原因是所有的 key 都干掉了,大部分之前使用的页面都完全干净了,会立即被操作系统回收。
Redis 虽然无法保证立即回收已经删除的 key 的内存,但是它会重用那些尚未回收的空 闲内存。这就好比电影院里虽然人走了,但是座位还在,下一波观众来了,直接坐就行。而 操作系统回收内存就好比把座位都给搬走了。
主从同步
CAP(Consistent一致性,Avalability可用性,Partition Tolerance分区一致性)
网络分区时,一致性和可用性不能同时完好。
增量同步
Redis 同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本 地的内存 buffer 中,然后异步将 buffer 中的指令同步到从节点,从节点一边执行同步的指 令流来达到和主节点一样的状态,一遍向主节点反馈自己同步到哪里了 (偏移量)。
因为内存的 buffer 是有限的,所以 Redis 主库不能将所有的指令都记录在内存 buffer 中。Redis 的复制内存 buffer 是一个定长的环形数组,如果数组内容满了,就会从头开始覆 盖前面的内容。
如果因为网络状况不好,从节点在短时间内无法和主节点进行同步,那么当网络状况恢 复时,Redis 的主节点中那些没有同步的指令在 buffer 中有可能已经被后续的指令覆盖掉 了,从节点将无法直接通过指令流来进行同步,这个时候就需要用到更加复杂的同步机制 — — 快照同步。
快照同步
是一个非常耗资源的操作,首先需要在主库上进行一次内存数据的全量快照到磁盘,再将快照文件的全部内容传送到从节点。从节点快照文件接受完毕后,进行一次全量加载,加载之前要将当前内存的数据清空,再进行增量同步。
在整个快照同步进行的过程中,主节点的复制 buffer 还在不停的往前移动,如果快照同 步的时间过长或者复制 buffer 太小,都会导致同步期间的增量指令在复制 buffer 中被覆 盖,这样就会导致快照同步完成后无法进行增量复制,然后会再次发起快照同步,如此极有 可能会陷入快照同步的死循环。
所以务必配置一个合适的复制 buffer 大小参数,避免快照复制的死循环。
增加从节点
增加从节点,必须要进行一次快照同步,完成后继续进行增量同步。
无盘复制
所谓无盘复制是指主服务器直接通过套接字 将快照内容发送到从节点,生成快照是一个遍历的过程,主节点会一边遍历内存,一遍将序 列化的内容发送到从节点,从节点还是跟之前一样,先将接收到的内容存储到磁盘文件中, 再进行一次性加载。
wait指令
redis的复制是异步进行的,wait可以让异步编程同步,确保系统的强一致性。
> set key value
OK
> wait 1 0
(integer) 1
wait 提供两个参数,第一个参数是从库的数量 N,第二个参数是时间 t,以毫秒为单 位。它表示等待 wait 指令之前的所有写操作同步到 N 个从库 (也就是确保 N 个从库的同 步没有滞后),最多等待时间 t。如果时间 t=0,表示无限等待直到 N 个从库同步完成达成 一致。
假设此时出现了网络分区,wait 指令第二个参数时间 t=0,主从同步无法继续进行, wait 指令会永远阻塞,Redis 服务器将丧失可用性。
Stream
stream有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的id对应,消息是持久化的,redis重启后,内容还在。
每个Stream有唯一的名称,他就是redis的key,在xadd指令追加消息时自动创建,每个Stream都可以挂多个消费组,每个消费组会有last_delivered_id在Stream数组之上往前移动,并表示当前消费组消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,不会自动创建,需要单独的xgroup create创建,制定Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组 (Consumer Group) 的状态都是独立的,相互不受影响。也就是说同一份 Stream 内部的消息会被每个消费组都消费到。
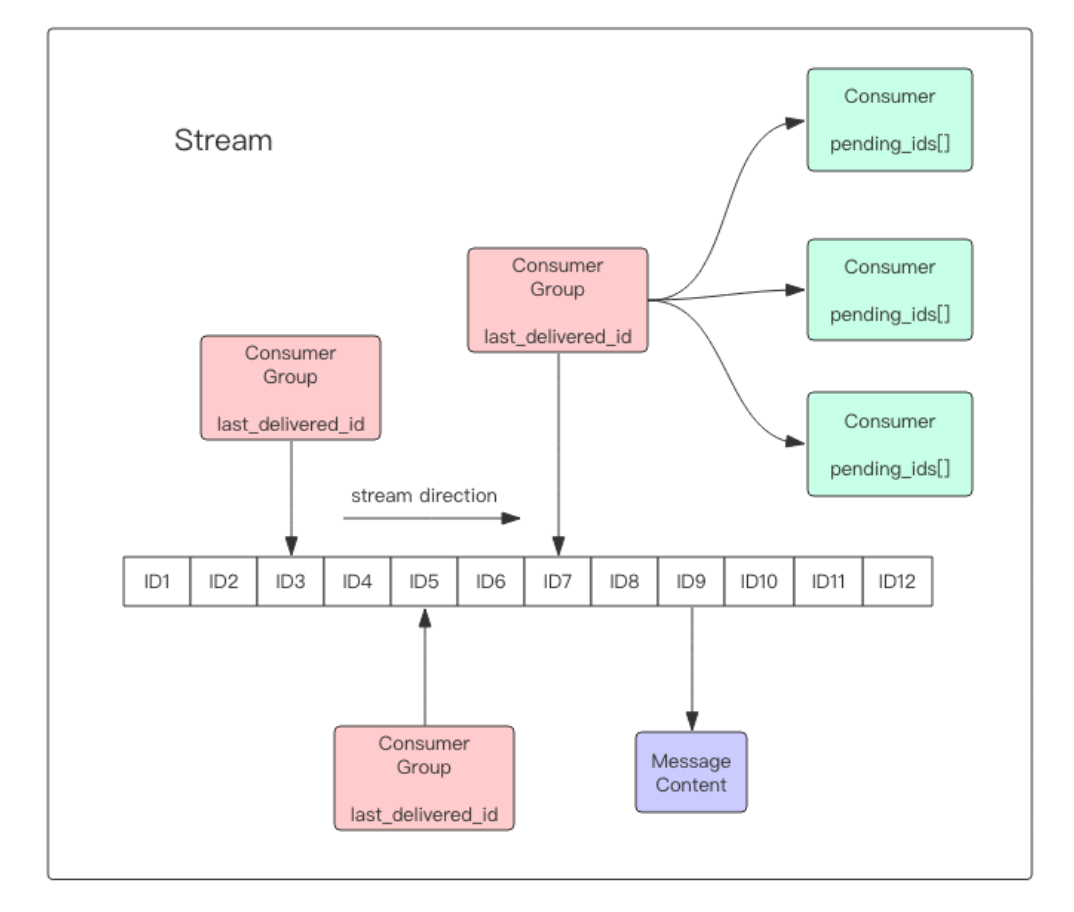
同一个消费组 (Consumer Group) 可以挂接多个消费者 (Consumer),这些消费者之间是 竞争关系,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。每个消费者有 一个组内唯一名称。
消费者 (Consumer) 内部会有个状态变量 pending_ids,它记录了当前已经被客户端读取 的消息,但是还没有 ack。如果客户端没有 ack,这个变量里面的消息 ID 会越来越多,一 旦某个消息被 ack,它就开始减少。这个 pending_ids 变量在 Redis 官方被称之为 PEL,也 就是 Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一 次,而不会在网络传输的中途丢失了没处理。
消息ID
消息 ID 的形式是 timestampInMillis-sequence,例如 1527846880572-5,它表示当前的消 息在毫米时间戳 1527846880572 时产生,并且是该毫秒内产生的第 5 条消息。消息 ID 可以 由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面 加入的消息的 ID 要大于前面的消息 ID。
CURD
127.0.0.1:6379> xadd person * name mike age 20
# * 号表示服务器自动生成 ID,后面顺序跟着一堆 key/value
"1605269145942-0"
127.0.0.1:6379> xadd person * name jack age 24
"1605269166153-0"
# -表示最小值 , + 表示最大值 按id来取
127.0.0.1:6379> xrange person - +
1) 1) "1605269145942-0"
2) 1) "name"
2) "mike"
3) "age"
4) "20"
2) 1) "1605269166153-0"
2) 1) "name"
2) "jack"
3) "age"
4) "24"
127.0.0.1:6379> xdel person 1605269166153-0
(integer) 1
127.0.0.1:6379> xlen person
(integer) 1
127.0.0.1:6379> xrange person - +
1) 1) "1605269145942-0"
2) 1) "name"
2) "mike"
3) "age"
4) "20"
127.0.0.1:6379> del person
(integer) 1
127.0.0.1:6379> xrange person - +
(empty array)
独立消费
可以在不定义消费组的情况下进行独立消费,当stream没有新消息时,可以阻塞等待。redis设置了一个单独的消费指令xread,可以将Stream当成普通消息队列使用。
xread count 2 streams codehole 0-0 //从头部读取2条
xread count 1 streams codehole $ // 从尾部读取一条,不会返回任何消息
xread block 0 count 1 streams codehole $ 从尾部阻塞等待新消息到来,下面的指令会堵住,直到新消息到来
客户端如果想要使用 xread 进行顺序消费,那么一定要记住当前消费到哪里了 , 也就是返回的消息 lD 下次继续调用 xread 时,将上次返回的最后一个消息 ID 作为 参数传递进去 , 就可以继续消费后续的消息。
block 0 表示永远阻塞,直到消息到来: block1000表示阻塞1s, 如果1s内没有 任何消息到来,就返回 nil。
创建消费组
Stream 通过xgroup create创建消费组,需要提供起始消息ID参数来初始化last_delivered_id变量。
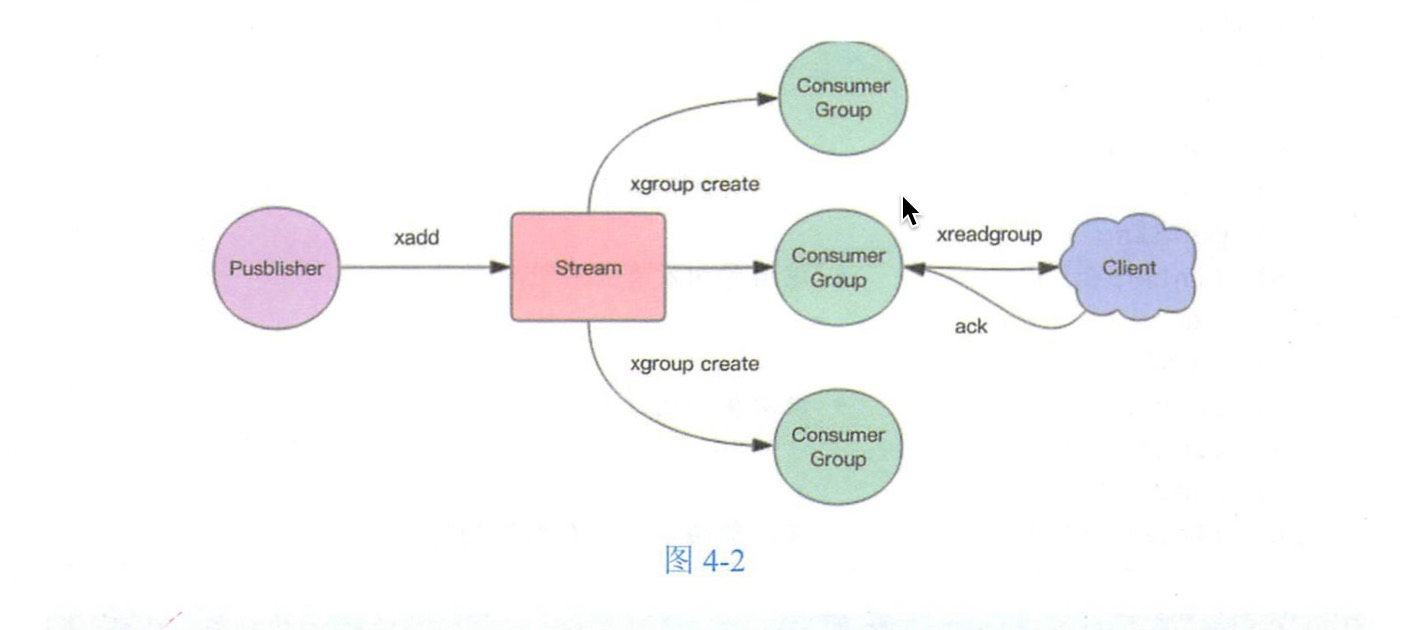
xgroup create mike cg1 0-0 表示从投开始消费
xgroup create mike cg2 $ 表示从尾部开始,只接受新消息,当前消息忽略
xinfo stream mike 获取当前stream消息
xinfo groups mkke 获取stream的消费组信息
消费
xreadgroup可以进行消费组的组内消费,需要提供消费组名称,消费者名称和起始消息id,也可以阻塞等待新消息。读取新消息后,对应的消息id会进入消费者PEL结构里,客户端处理完毕使用xack通知服务器,该消息就会从PEL移除。
xreadgroup GROUP cg1 c1 count 1 streams mike >
> 表示从当前消费组的last_delivered_id 后面开始读,每消费1条就会前进
stream消息太多怎么办
redis提供了一个定长Stream功能,在xadd指令中提供了一个定长长度maxlen,可以将老的消息干掉,确保链表不超过指定长度。
xlen mike
5
xadd mike maxlen 3 * name he age 1
xlen mike
3
PEL如何避免消息丢失
PEL里保存了发出去的消息ID,待客户端重新连接上后,可以在此收到PEL中的消息ID列表,此时 xreadgroup 的起始消息 D 必须是任意有效的消 息 ID,一般将参数设为 0-0, 表示读取所有的 PEL 消息以及自 last delivered id 之后 的新消息。