对于现在互联网企业来说,数据量越来越大,同时,程序的并发量也越来越大,传统的通过增加索引等优化数据库性能等方式已经不能满足数据高并发、大数据量的需求时,读写分离是一个不错的优化手段。
数据库读写分离的好处:
-
增加了硬件设备的处理能力;
-
对于读操作为主的应用来说,使用读写分离是一个不错的场景,因为可以确保写的服务器压力减小,读又可能接受时间上的延迟;
-
读写分离后,极大的缓解了写锁和读锁的竞争;
-
读写分离主要可以运用于读远大于写的场景。如果在未读写分离的场景下,当select很多时,update和delete操作将会堵塞。
目前,实现MySQL读写分离的方式较多,通常采用MyCat或sharding-jdbc来实现读写分离,MyCat是采用中间件的方式达到MySQL读写操作的效果,而sharding-jdbc是jar方式引入,需要在代码层引入配置。本文将介绍通过shardingsphere组件中的sharding-jdbc来实现MySQL读写分离。
一、首先将MySQL搭建成主从复制的数据库
-
服务器环境
两台服务器,操作系统是centos7
主服务器Master: 192.168.2.172
从服务器Slave: 192.168.2.173
-
分别在两台服务上安装Mysql数据库。(此步细节跳过,不会自行度娘)
-
配置主从复制
1) 打开主服务的my.cnf文件(Mysql数据同步是通过binlog来实现的,所以需要启用binlog才能实现同步)
[mysqld] server_id = 1 //ID不能相同 log_bin = mysql-bin binlog_format=MIXED max_binlog_size=512M expire_logs_day=3 binlog_do_db=test //需要同步的数据库 binlog_ignore_db=mysql,performance_schema,information_schema //忽略同步的数据库
2) 重启mysql服务
service mysqld restart
3) 在主数据库上建立一个用户,用于同步
grant replication slave on *.* 'slave@192.168.2.173' identified by '123456'
这个同步用户是slave,密码是123456
4) 查询主数据库信息:
show master status;

5) 配置从数据库信息,打开从数据的my.cnf文件
[mysqld] server_id = 2 log_bin=mysql-bin binlog_format=MIXED max_binlog_size=512M expire_logs_day=3 replicate_do_db=test replicate-ignore-db=mysql,performance_schema,information_schema relay_log_recovery=1 log_slave_updates=1
6)重启从数据库,进入mysql命令行执行下列语句
stop slave; change master to master_host='192.168.2.172', master_user='slave', master_password='123456', master_port=3306, master_log_file='mysql-bin.000001', master_log_pos=3438; start slave;
7) 从库执行 show slave status G;
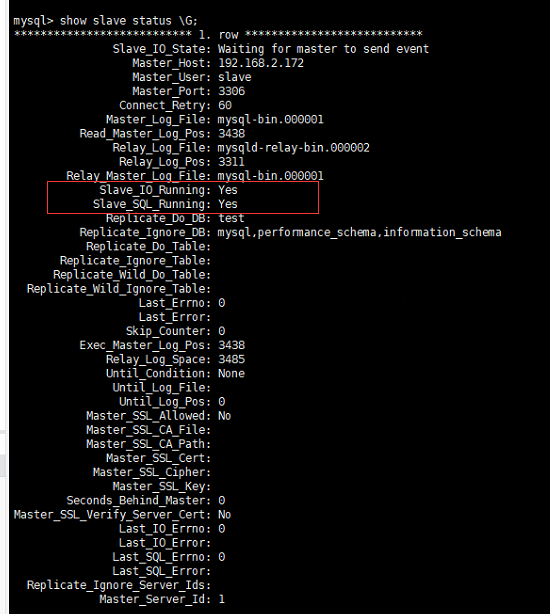
此时主从复制数据库就已经搭建完成
二、使用sharding-jdbc来实现数据库读写分离
1. 首先新建一个spring boot 项目
2. 项目pom.xml文件中导入相关文件
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.28</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.13</version>
</dependency>
3. 加载完后,需要对application.yml文件进行配置
shardingsphere:
datasource:
names: master,slave
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.2.172:3306/test?useUnicode=true&useSSL=false&characterEncoding=utf8&nullCatalogMeansCurrent=true&useTimezone=true&serverTimezone=Asia/Shanghai
username: root
password: root
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.2.173:3306/test?useUnicode=true&useSSL=false&characterEncoding=utf8&nullCatalogMeansCurrent=true&useTimezone=true&serverTimezone=Asia/Shanghai
username: root
password: root
sharding:
master-slave-rules:
ms_ds:
load-balance-algorithm-type: round_robin
master-data-source-name: master
slave-data-source-names: slave
4.效果:
插入数据后:
查询数据:
当在一个事务中,插入数据再做查询: