背景:
pytorch从1.6版本开始,已经内置了torch.cuda.amp,采用自动混合精度训练就不需要加载第三方NVIDIA的apex库了。本文主要从三个方面来介绍AMP:
一.什么是AMP?
二.为什么要使用AMP?
三.如何使用AMP?
四. 注意事项
正文:
一.什么是AMP?
默认情况下,大多数深度学习框架都采用32位浮点算法进行训练。2017年,NVIDIA研究了一种用于混合精度训练的方法,该方法在训练网络时将单精度(FP32)与半精度(FP16)结合在一起,并使用相同的超参数实现了与FP32几乎相同的精度。
在介绍AMP之前,先来理解下FP16与FP32,FP16也即半精度是一种计算机使用的二进制浮点数据类型,使用2字节存储。而FLOAT就是FP32。
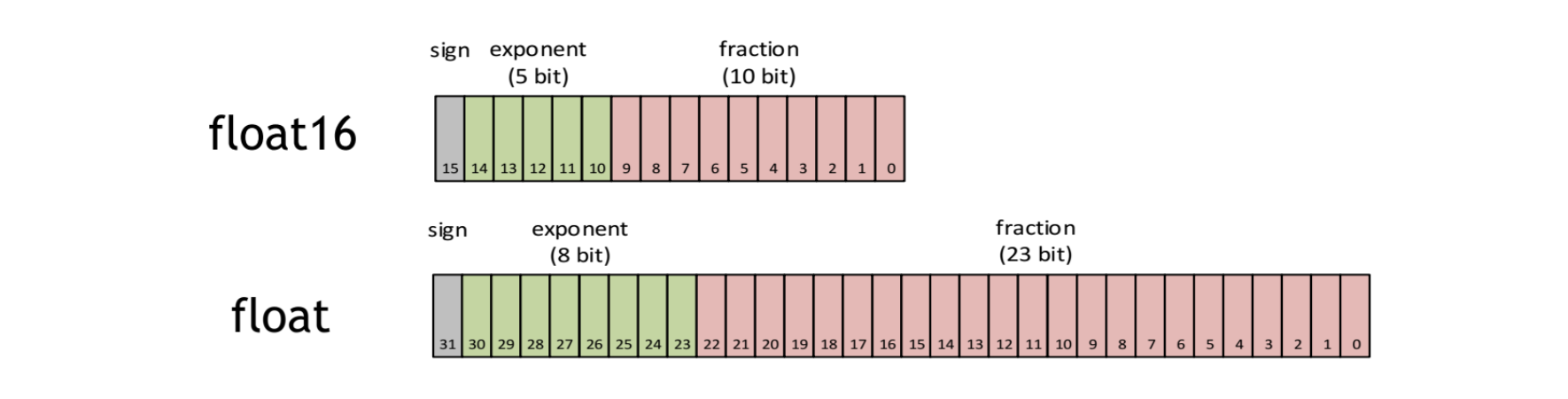
其中,sign位表示正负,exponent位表示指数2^(n-15+1(n=0)),fraction位表示分数(m/1024)。

一般情况下,我们在pytorch中创建一个Tensor:
>>import torch
>>tensor1=torch.zeros(30,20)
>>tensor1.type()
'torch.FloatTensor'
>>tensor2=torch.Tensor([1,2])
>>tensor2.type()
'torch.FlatTensor'
可以看到,默认创建的tensor都是FloatTensor类型。而在Pytorch中,一共有10种类型的tensor:
torch.FloatTensor(32bit floating point)
torch.DoubleTensor(64bit floating point)
torch.HalfTensor(16bit floating piont1)
torch.BFloat16Tensor(16bit floating piont2)
torch.ByteTensor(8bit integer(unsigned)
torch.CharTensor(8bit integer(signed))
torch.ShortTensor(16bit integer(signed))
torch.IntTensor(32bit integer(signed))
torch.LongTensor(64bit integer(signed))
torch.BoolTensor(Boolean)
默认Tensor是32bit floating point,这就是32位浮点型精度的tensor。
AMP(自动混合精度)的关键词有两个:自动,混合精度。
自动:Tensor的dtype类型会自动变化,框架按需自动调整tensor的dtype,当然有些地方还需手动干预。
混合精度:采用不止一种精度的Tensor,torch.FloatTensor和torch.HalfTensor
pytorch1.6的新包:torch.cuda.amp,是NVIDIA开发人员贡献到pytorch里的。只有支持tensor core的CUDA硬件才能享受到AMP带来的优势。Tensor core是一种矩阵乘累加的计算单元,每个tensor core时针执行64个浮点混合精度操作(FP16矩阵相乘和FP32累加)。
二、为什么要使用AMP?
前面已介绍,AMP其实就是Float32与Float16的混合,那为什么不单独使用Float32或Float16,而是两种类型混合呢?原因是:在某些情况下Float32有优势,而在另外一些情况下Float16有优势。这里先介绍下FP16:
优势有三个:
1.减少显存占用;
2.加快训练和推断的计算,能带来多一倍速的体验;
3.张量核心的普及(NVIDIA Tensor Core),低精度计算是未来深度学习的一个重要趋势。
但凡事都有两面性,FP16也带来了些问题:1.溢出错误;2.舍入误差;
1.溢出错误:由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出和下溢出,溢出之后就会出现"NaN"的问题。在深度学习中,由于激活函数的梯度往往要比权重梯度小,更易出现下溢出的情况
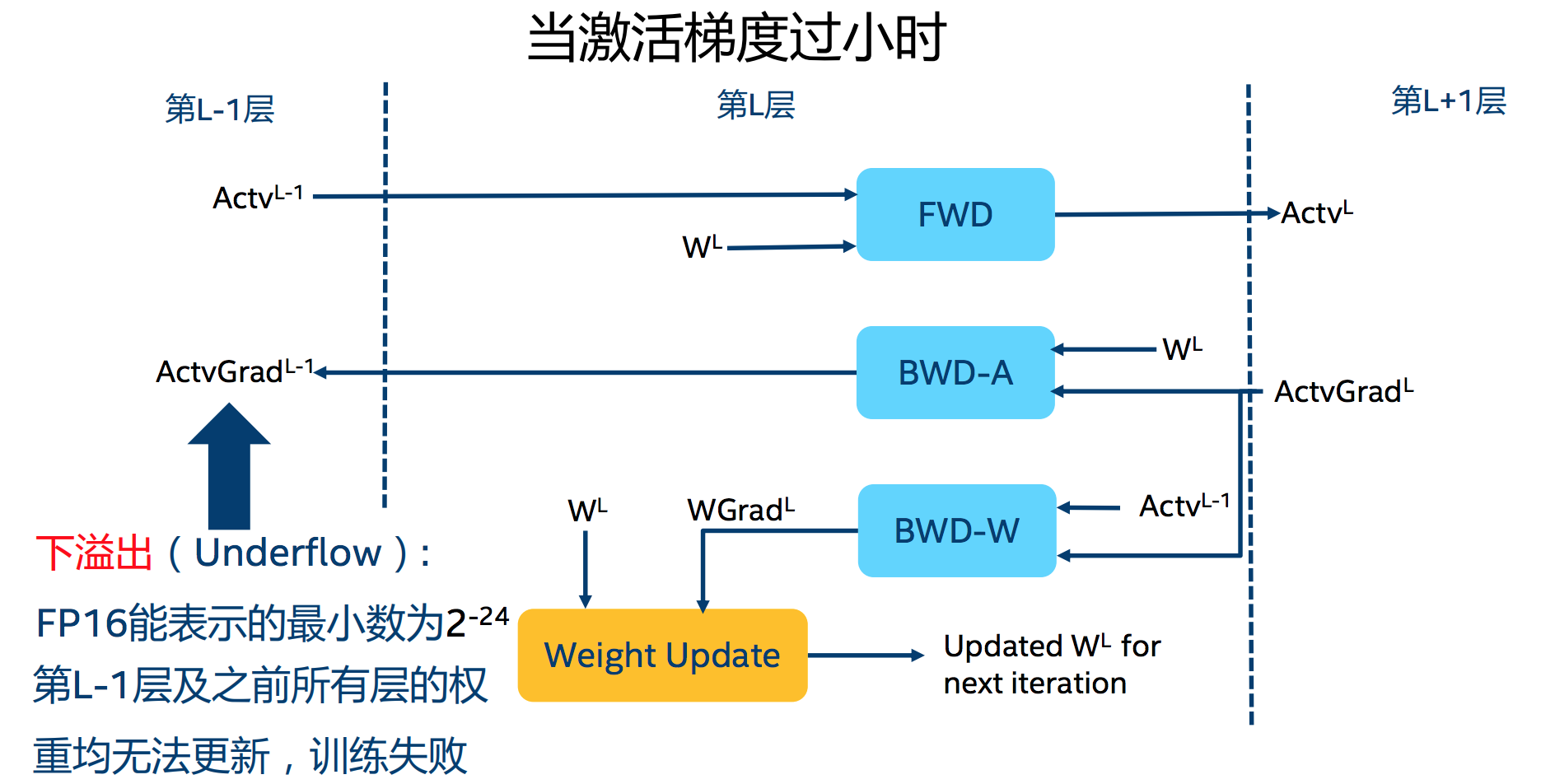
2.舍入误差
舍入误差指的是当梯度过小时,小于当前区间内的最小间隔时,该次梯度更新可能会失败:

为了消除torch.HalfTensor也就是FP16的问题,需要使用以下两种方法:
1)混合精度训练
在内存中用FP16做储存和乘法从而加速计算,而用FP32做累加避免舍入误差。混合精度训练的策略有效地缓解了舍入误差的问题。
什么时候用torch.FloatTensor,什么时候用torch.HalfTensor呢?这是由pytorch框架决定的,在pytorch1.6的AMP上下文中,以下操作中Tensor会被自动转化为半精度浮点型torch.HalfTensor:
__matmul__ addbmm addmm addmv addr baddbmm bmm chain_matmul conv1d conv2d conv3d conv_transpose1d conv_transpose2d conv_transpose3d linear matmul mm mv prelu
2)损失放大(Loss scaling)
即使了混合精度训练,还是存在无法收敛的情况,原因是激活梯度的值太小,造成了溢出。可以通过使用torch.cuda.amp.GradScaler,通过放大loss的值来防止梯度的underflow(只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去);
反向传播前,将损失变化手动增大2^k倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出;
反向传播后,将权重梯度缩小2^k倍,恢复正常值。
三.如何使用AMP?
目前有两种版本:pytorch1.5之前使用的NVIDIA的三方包apex.amp和pytorch1.6自带的torch.cuda.amp
1.pytorch1.5之前的版本(包括1.5)
使用方法如下:
from apex import amp model,optimizer = amp.initial(model,optimizer,opt_level="O1") #注意是O,不是0 with amp.scale_loss(loss,optimizer) as scaled_loss: scaled_loss.backward()
取代
loss.backward()
其中,opt_level配置如下:
O0:纯FP32训练,可作为accuracy的baseline;
O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM,卷积)还是FP32(softmax)进行计算。
O2:几乎FP16,混合精度训练,不存在黑白名单 ,除了bacthnorm,几乎都是用FP16计算;
O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;
动态损失放大(dynamic loss scaling)部分,为了充分利用FP16的范围,缓解舍入误差,尽量使用最高的放大倍数2^24,如果产生上溢出,则跳出参数更新,缩小放大倍数使其不溢出。在一定步数后再尝试使用大的scale来充分利用FP16的范围。
分布式训练:
import argparse import apex import amp import apex.parallel import convert_syncbn_model import apex.parallel import DistributedDataParallel as DDP 定义超参数: def parse(): parser=argparse.ArgumentParser() parser.add_argument('--local_rank',type=int, default=0) #local_rank指定了输出设备,默认为GPU可用列表中的第一个GPU,必须加上。 ... args = parser.parser.parse_args() return args 主函数写: def main(): args = parse() torch.cuda.set_device(args.local_rank) #必须写在下一句的前面 torch.distributed.init_process_group( 'nccl', init_method='env://') 导入数据接口,需要用DistributedSampler dataset = ... num_workers = 4 if cuda else 0 train_sampler=torch.utils.data.distributed.DistributedSampler(dataset) loader = DataLoader(dataset, batch_size=batchsize, shuflle=False, num_worker=num_workers,pin_memory=cuda, drop_last=True, sampler=train_sampler) 定义模型: net = XXXNet(using_amp=True) net.train() net= convert_syncbn_model(net) device=torch.device('cuda:{}'.format(args.local_rank)) net=net.to(device) 定义优化器,损失函数,定义优化器一定要把模型搬运到GPU之上 apt = Adam([{'params':params_low_lr,'lr':4e-5}, {'params':params_high_lr,'lr':1e-4}],weight_decay=settings.WEIGHT_DECAY) crit = nn.BCELoss().to(device) 多GPU设置
import torch.nn.parallel.DistributedDataParallel as DDP net,opt = amp.initialize(net,opt,opt_level='o1') net=DDP(net,delay_allreduce=True)
loss使用方法:
opt.zero_grad()
with amp.scale_loss(loss, opt) as scaled_loss:
scaled_loss.backward()
opt.step()
加入主入口:
if __name__ == '__main__':
main()
无论是apex支持的DDP还是pytorch自身支持的DDP,都需使用torch.distributed.launch来使用,方法如下:
CUDA_VISIBLE_DIVECES=1,2,4 python -m torch.distributed.launch --nproc_per_node=3 train.py
1,2,4是GPU编号,nproc_per_node是指定用了哪些GPU,记得开头说的local_rank,是因为torch.distributed.launch会调用这个local_ran
分布式训练时保存模型注意点:
如果直接在代码中写torch.save来保存模型,则每个进程都会保存一次相同的模型,会存在写文件写到一半,会被个进程写覆盖的情况。如何避免呢?
可以用local_rank == 0来仅仅在第一个GPU上执行进程来保存模型文件。
虽然是多个进程,但每个进程上模型的参数值都是一样的,而默认代号为0的进程是主进程
if arg.local_rank == 0: torch.save(xxx)
2.pytorch1.6及以上版本
有两个接口:autocast和Gradscaler
1) autocast
导入pytorch中模块torch.cuda.amp的类autocast
from torch.cuda.amp import autocast as autocast model=Net().cuda() optimizer=optim.SGD(model.parameters(),...) for input,target in data: optimizer.zero_grad() with autocast(): output=model(input) loss = loss_fn(output,target) loss.backward() optimizer.step()
可以使用autocast的context managers语义(如上),也可以使用decorators语义。当进入autocast上下文后,在这之后的cuda ops会把tensor的数据类型转换为半精度浮点型,从而在不损失训练精度的情况下加快运算。而不需要手动调用.half(),框架会自动完成转换。
不过,autocast上下文只能包含网络的前向过程(包括loss的计算),不能包含反向传播,因为BP的op会使用和前向op相同的类型。
当然,有时在autocast中的代码会报错:
Traceback (most recent call last): ...... File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 722, in _call_impl result = self.forward(*input, ** kwargs) ...... RuntimeError: expected scalar type float but found c10::Half
对于RuntimeError:expected scaler type float but found c10:Half,应该是个bug,可在tensor上手动调用.float()来让type匹配。
2)GradScaler
使用前,需要在训练最开始前实例化一个GradScaler对象,例程如下:
from torch.cuda.amp import autocast as autocast model=Net().cuda() optimizer=optim.SGD(model.parameters(),...) scaler = GradScaler() #训练前实例化一个GradScaler对象 for epoch in epochs: for input,target in data: optimizer.zero_grad() with autocast(): #前后开启autocast output=model(input) loss = loss_fn(output,targt) scaler.scale(loss).backward() #为了梯度放大 #scaler.step() 首先把梯度值unscale回来,如果梯度值不是inf或NaN,则调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新。
scaler.step(optimizer) scaler.update() #准备着,看是否要增大scaler
scaler的大小在每次迭代中动态估计,为了尽可能减少梯度underflow,scaler应该更大;但太大,半精度浮点型又容易overflow(变成inf或NaN).所以,动态估计原理就是在不出现if或NaN梯度的情况下,尽可能的增大scaler值。在每次scaler.step(optimizer)中,都会检查是否有inf或NaN的梯度出现:
1.如果出现inf或NaN,scaler.step(optimizer)会忽略此次权重更新(optimizer.step()),并将scaler的大小缩小(乘上backoff_factor);
2.如果没有出现inf或NaN,那么权重正常更新,并且当连续多次(growth_interval指定)没有出现inf或NaN,则scaler.update()会将scaler的大小增加(乘上growth_factor)。
对于分布式训练,由于autocast是thread local的,要注意以下情形:
1)torch.nn.DataParallel:
以下代码分布式是不生效的
model = MyModel() dp_model = nn.DataParallel(model) with autocast(): output=dp_model(input) loss=loss_fn(output)
需使用autocast装饰model的forward函数
MyModel(nn.Module): @autocast() def forward(self, input): ... #alternatively MyModel(nn.Module): def forward(self, input): with autocast(): ... model = MyModel() dp_model=nn.DataParallel(model) with autocast(): output=dp_model(input) loss = loss_fn(output)
2)torch.nn.DistributedDataParallel:
同样,对于多GPU,也需要autocast装饰model的forward方法,保证autocast在进程内部生效。
四. 注意事例:
在使用AMP时,由于报错信息并不明显,给调试带来了一定的难度。但只要注意以下一些点,相信会少走很多弯路。
1.判断GPU是否支持FP16,支持Tensor core的GPU(2080Ti,Titan,Tesla等),不支持的(Pascal系列)不建议;
1080Ti与2080Ti对比
gtx 1080ti: 半精度浮点数:0.17TFLOPS 单精度浮点数:11.34TFLOPS 双精度浮点数:0.33TFLOPS rtx 2080ti: 半精度浮点数:20.14TFLOPS 单精度浮点数:10.07TFLOPS 双精度浮点数:0.31TFLOPS
半精度浮点数即FP16,单精度浮点数即FP32,双精度浮点数即FP64。
在不使用apex的pytorch训练过程中,一般默认均为单精度浮点数,从上面的数据可以看到1080ti和2080ti的单精度浮点数运算能力差不多,因此不使用apex时用1080ti和2080ti训练模型时间上差别很小。
使用apex时用1个2080ti训练时一个epoch是2h31min,两者时间几乎一样,但是却少用了一张2080ti。这是因为在pytorch训练中使用apex时,此时大多数运算均为半精度浮点数运算,而2080ti的半精度浮点数运算能力是其单精度浮点数运算能力的两倍
2.常数范围:为了保证计算不溢出,首先保证人工设定的常数不溢出。如epsilon,INF等;
3.Dimension最好是8的倍数:维度是8的倍数,性能最好;
4.涉及sum的操作要小心,容易溢出,softmax操作,建议用官方API,并定义成layer写在模型初始化里;
5.模型书写要规范:自定义的Layer写在模型初始化函数里,graph计算写在forward里;
6.一些不常用的函数,使用前要注册:amp.register_float_function(torch,'sogmoid')
7.某些函数不支持FP16加速,建议不要用;
8.需要操作梯度的模块必须在optimizer的step里,不然AMP不能判断grad是否为NaN