一、什么是YOLOV4
YOLOV4是基于原有YOLO目标检测架构,采用了近年来CNN领域最优秀的优化策略。
从数据处理,主干网络,模型训练,激活函数,损失函数等各个方面都有着不同程度的优化。
二、YOLOV4的改进总结
1、开发了一个简单高效的目标检测算法,降低了训练门槛:仅使用一块GPU:1080TI,就可以训练一个又快又准的检测器;
2、验证了最新的Bag-of-Freebies和Bag-of-Specials在训练过程中对YOLOV4的影响;
3、优化了一些最新提出的算法:CBN,PAN,SAM,使YOVOV4可在一块GPU上训练。
三、常用改进方法介绍
1、模型结构 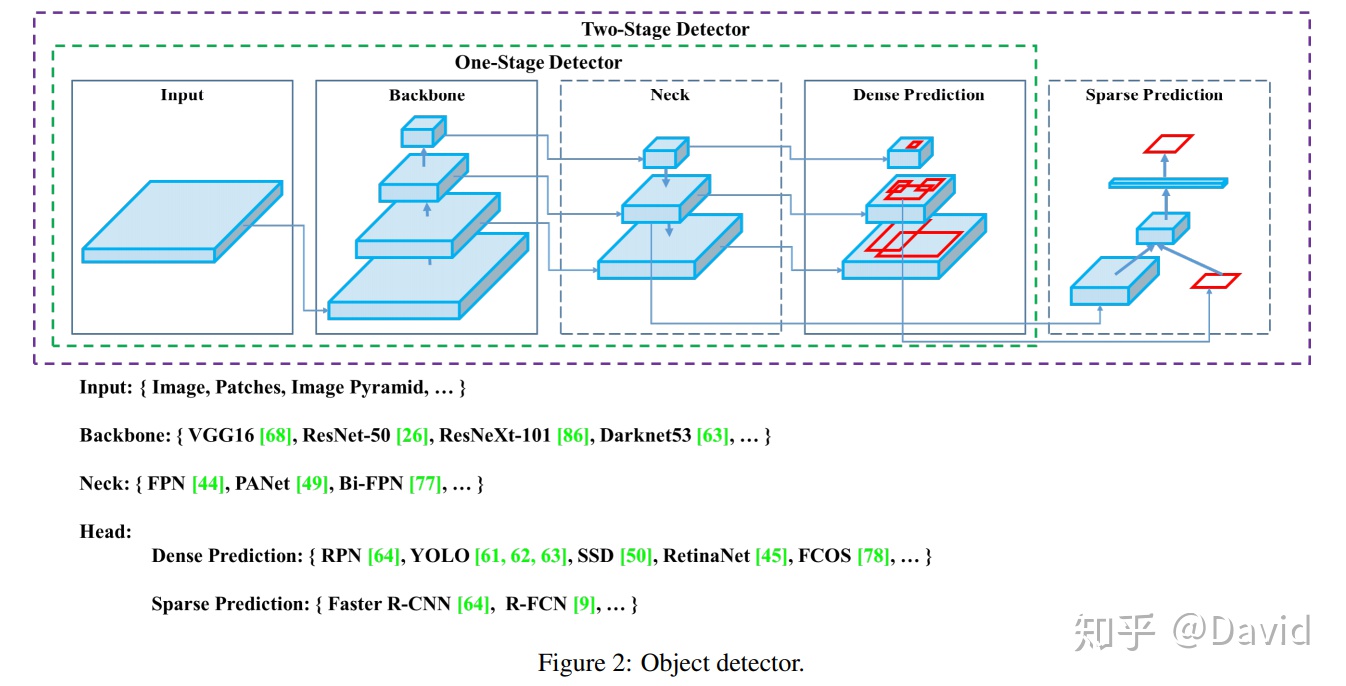
一个完整的网络模型一般包含四部分:
1)输入部分:算法的输入,整个图像,一个PATCH或图像金字塔
2)主干网络:提取图像的特征,浅层特征如:边缘,颜色,纹理等。可以使用设计好并训练好的网络:VGG16,19,RESNET50,RexNeXt101,Darknet53,当然,还有一些轻量级的网络:MobileNet1,2,3 ,ShuffleNet1,2
3)瓶颈部分:特征增强,对主干网提取到的特征进行加工,增强。典型的有:SPP,ASPP,RFB,SAM,还有FPN,PAN,NAS-FPN,BiFPN,ASFF,SFAM。
4)检测头:算法项的输出。
如想得到HeatMap(CenterNet),就增加一些反卷积;
如想得到BBOX,就接CONV来输出结果,如:YOLO,SSD;
如想输出多任务(MaskRCNN)那就输出三个Head:分类Classification ,回归Regression ,分割Segmentation
2、训练策略
2.1 Bag-of-freebies
在不增加模型复杂度的情况下,使用一些比较有用的训练策略来提升准确率,如:Data augmentation
2.1.1 数据增强
增加训练样本的多样性,使模型有更高的鲁棒性。
[1]逐像素pixel-wise
(1)几何增强:随机翻转,随机裁剪,拉伸,旋转
(2)色彩增强:对比度增强,亮度增强,HSV空间增强(较关键)
[2]逐块block-wise
(1) 在图像中随机裁剪矩形区域,用0填充(cutout)
(2) 随机裁剪多个矩形区域(grid mask)
(3)在Heatmap上裁剪并填充(dropout,dropconnect,dropblock)
[3] Mixup
将两个图像按不同比例相加,a*0.1+b*0.9=c。
2.1.2 解决数据不平衡
数据不平衡分两种:
一、背景和要识别物体之间的不均衡
如:在两阶段方法中,RPN阶段会生成很多ROI,里面有太多背景,有用的框很少;
二、类别不平衡
识别物体间不同类别间的不平衡,涉及到一个长尾分布。需要使用OHEM(困难样本挖掘)或Focal loss,或Label smooth
2.1.3 修改Loss函数
最早是MSE,现在是NMS(IOU),然后是GIOU Loss。
2.2 Bag-of=Specials
通过增加少量的计算,能有效增加物体检测的准确率。
2.2.1 增大感受野
SPP:解决输入尺寸不一致,按比例1,2,4或1,2,3三个尺度划分Pooling,输出相同大小FeatureMap
ASPP:在SPP前加了Atrous或Dilated
RFB:在同一个FeatureMap下,引入不同dilated ratio的空洞卷积,提取到不同的感受野,最后进行融合
2.2.2 注意力机制
channel attention:SENet,在FeatureMap层中同时引入一个1x1xC的weights,可以对每个channel上的特征加入不同权重,提高特征学习能力。
Spatial attention:在HW维度上加入attention。
Channel+Spatial:channel attention和spatial attention融合。
2.2.3 特征融合或特征集成
skip connection:在Encoder-decoder中比较多,如:UNet,融合底层和高层的特征信息;
hyper-column:就像InceptionV4结构,使用不同的kernel-size的卷积来集成特征;
FPN,ASFF,BiFPN:将不同阶段的不同尺度的特征进行融合。EfficientDet中BiFPN连接最密集;
2.2.4 激活函数
一个好的激活函数既能使得梯度传播更高效,同时不会占用额外的计算资源。
ReLU
LReLU、PreLU、 SELU、ReLU6、Swish、Hard-Swish、Mish
2.2.5后处理
NMS,SoftNMS,DIoU NMS
四、本文改进方法
1、 数据增强:Mosaic

将4张训练图片混合成一张的新的数据增强方法,可以丰富图像的上下文信息,增强模型的鲁棒性,另外也减少了对Mini-batch处理size的需求。
2、自对抗训练 Adversarial training
一种新的数据扩充技术,分两阶段:第一阶段,神经网络先改变原始图像而不是网络权值,对自身执行对抗性攻击,改变原始图像,从而造成图像上没有目标的假象;第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
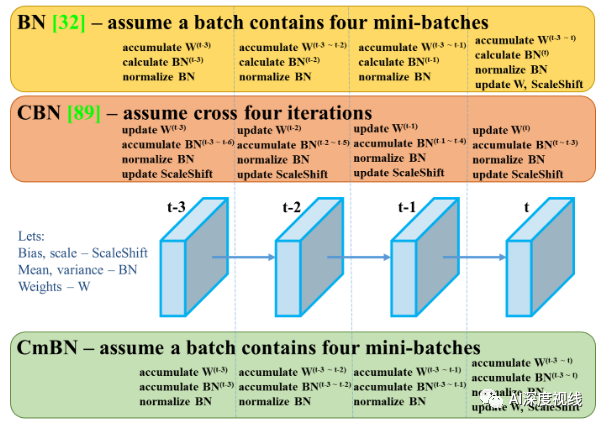
3、CmBN
是CBN的修改版本,定义为跨微批量标准化,仅收集单个批次中的小批之间的统计信息
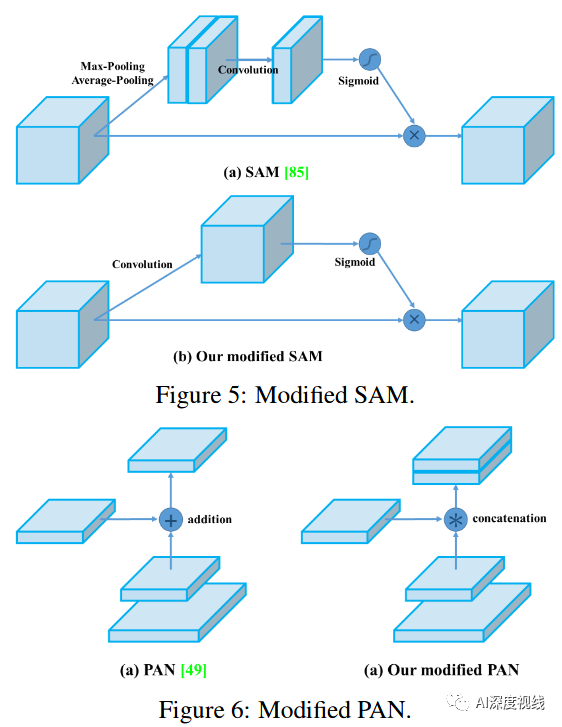
4、SAM(Spatial Attention Module)改进
将SAM从空间上的attention修改为点上的attention,并将PAN的short-cut连接改为拼接,如下图:
五、YOLOV4的架构
Backbone:CSPDarknet53
Neck:SPP,PAN
Head:YOLOV3
YOLOV4的调试Trick:
BoF:
Bakbone:CutMix和Mosaic数据增强,DropBlock正则化,类标签平滑;
Detector:CIoU Loss,DropBlock正则化,自对抗训练,最优超参数;
BoS:
Bakbone:Mish,CSP(跨级部分连接),MiWRC(多输入加权残差连接)
Detector:SPPBlock,SAMBlock,PAN(路径聚合网络),DIOU-NMS
六、实验与超参数
1、分类
ImageNet图像分类,超参数如下:
训练步骤:8,000,000
批量尺寸:128,小批量尺寸:32
采用多项式衰减学习速率调整策略,初始学习率为:0.1
warmup:1000
momentum:0.9,weight decay:0.005
2、检测
训练步骤:500500
初始学习率:0.01,4,000,000步后和4,500,000步后分别乘以0.1
momentum:0.9,weight:0.0005
批量大小:64,小批量大小:8或4
七、原作信息
论文链接:
https://arxiv.org/pdf/2004.10934.pdf
代码链接:
https://github.com/AlexeyAB/darknet
已训练好的模型文件:
https://pan.baidu.com/s/189L8HHBIUpQ5tzleKw1BvA 提取码: kd6b
上一篇:
下一篇:
YOLOV5,待更新。。。