开源TSDB简介--Druid
Druid是一个以Java编写的开源分布式列式数据存储。 Druid的目标是快速提取大量事件数据,并提供低延迟的查询。
德鲁伊的名字来源于许多角色扮演游戏中的变形德鲁伊角色,以表示其系统结构可以为解决不同类型数据问题而灵活改变。 Druid通常用于OLAP(Online analytical processing)应用程序来分析大量的实时和历史数据。
Architecture
为了方便使用以及cloud-friendly,Druid拥有一个多进程、分布式架构。 Druid按功能分为多种node,每个类型node都可以独立配置和扩展,为Druid群集提供最大的灵活性。 该设计还提供增强的容错能力:一个组件的中断不会立即影响其他组件。
Druid的node类型包括:
- Historical - 处理存储和查询历史数据的进程,其从deep storage中下载segments并响应有关这些数据的查询,Historical不接受数据写入操作。
- MiddleManager - 处理新的数据写入的进程,其负责从外部数据源获取数据生成Druid segments并写入集群。
- Broker - 代理查询请求的进程,其从客户端接受查询请求,并转发给Historicals和MiddleManagers,并在收到查询结果后进行合并后返回给客户端。
- Coordinator - 观察和协调Historical集群的进程,其负责分配segments到指定的servers,并保证segments在Historicals上的数据均衡。
- Overlord - 观察和协调MiddleManager集群的进程,其负责分配数据写入任务给MiddleManagers并协调segments的发布。
- Router - 可选进程,用于在Brokers、Overlords和Coordinators之前提供一个统一的API网关。如果没有部署Router,则直接和Brokers、Overlords和Coordinators进行通讯。
如下图所示为Druid的架构图:
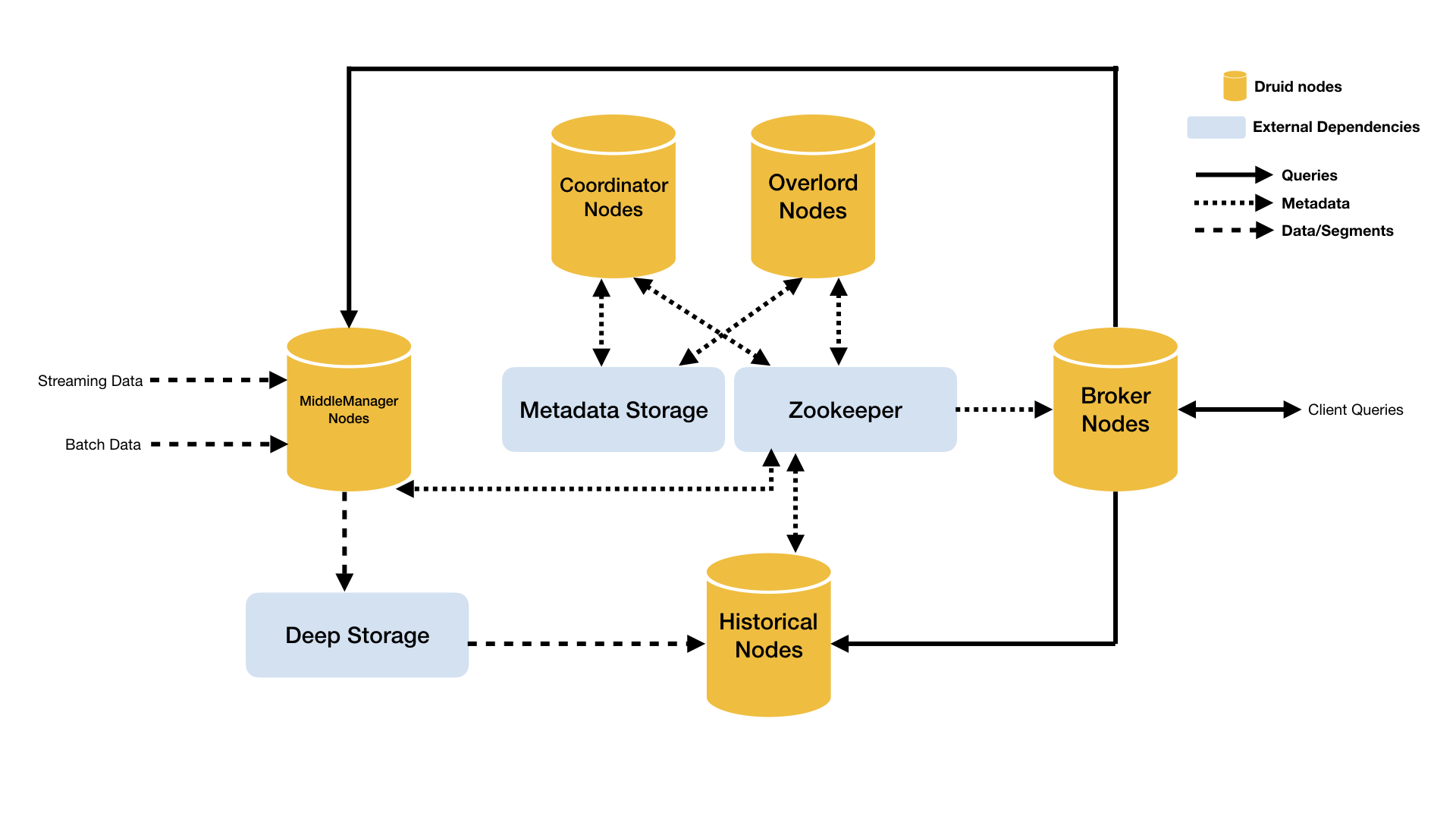
Druid的架构将服务划分的比较细,有利于动态扩展和在云上部署。但个人觉得略显复杂的架构,并不是很方便部署和运维,尤其是其依赖了过多的外部组件。
Deployment
Druid各个node进程可以单独部署或者合设到同一台机器上,一个常用的部署方式:
- "Data" servers - Historical + MiddleManager
- "Query" servers - Broker + (optionally) Router
- "Master" servers - Coordinator + Overlord + ZooKeeper
此外,Druid还依赖3个外部组件:
- Deep storage - 在不同的Druid server共享数据文件的存储,通常使用分布式存储如S3或者HDFS。Druid使用Deep storage来存储所有写入的数据。
- Metadata store - 在不同的Druid server共享metadata的存储,通常使用传统的RDBMS,如PostgreSQL或者MySQL。
- ZooKeeper - 用于服务发现、协调和leader选举。
Datasources and Segments
Druid将数据存储在"datasources"里,相当于传统RDBMS的表格。每个datasource用时间进行分区(可选其他属性进行进一步分区)。每个时间范围(如按天分区,则时间范围为一天)称为一个"chunk" 。在一个chunk里,数据进一步分区为一个或多个"segments"。每个segment是一个单独文件,存储大约几百万行数据。
一个datasource可能包含从几个segments到几百万几个segments。每个segment由MiddleManager创建,然后经过如下步骤的处理以生成紧凑的文件并支持快速查询:
- 转换成columnar列式格式
- 使用位图索引进行索引查询
- 使用各种算法进行压缩
- 进行字符串编码,使用UID代替string字符串进行存储,节约存储空间
- 将位图索引进行压缩
- 所有列进行类型感知的压缩
Segments周期性的提交和发布,此时他们写入Deep storage,并不允许再修改,并从MiddleManager转移到Historical。该Segment对应的一条记录写入到metadata store。该记录用一些bits来描述segment的属性,如segment的schema、大小以及其所在deep storage位置。这些信息都是Coordinator需要用到的。
Query
收到查询请求后,Broker根据请求先定位到哪些segments可能包含查询需要的数据,然后根据segments定位并发送请求到对应的Historicals和MiddleManagers。然后Historical/MiddleManager进程查询获取具体的数据并返回结果。Broker最后将查询结果汇聚后返回给调用者。
Broker pruning(裁剪)是Druid限制每个查询请求需要扫描的数据量的重要方式,但它不是唯一方法。过滤器提供了更细粒度的裁剪方法,每个Segment内的索引结构可以帮助Druid过滤出需要查询的行。这样Druid可以只读取匹配了查询过滤器的行,从而跳过不需要读取的行。
所以Druid通过如下3个方法提供查询的性能:
- 裁剪定位查询需要扫描的segments
- 在segment内,通过索引定位需要查询的行
- 在segment内,只读取查询相关的行和列