先来张图养养眼:
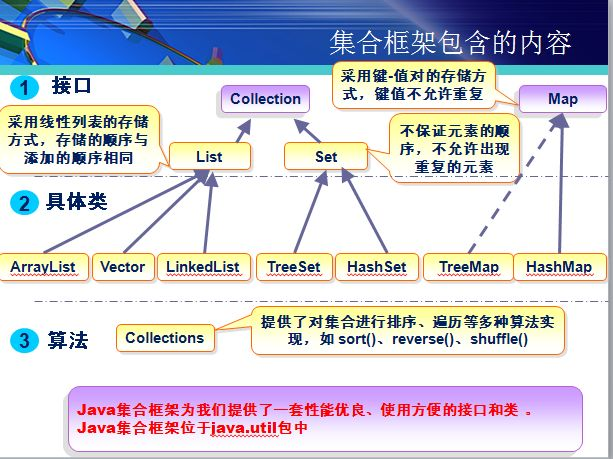
在开始集合框架总结之前,先得明确【集合】是什么?
集合是:1.用于存储对象的容器。2.该容器的长度是可变的。
一,数组容器和集合的区别
【数组容器和集合都可以用来存储数据,那么他们有啥区别呢?】
1. 集合长度是可变的;数组长度固定的;
2. 集合中只能存储对象;数组中既可以存储对象,又可以存储基本类型数据。
3. 集合中存储的对象可以是任意类型的;数组中只能存储同一类型的对象。
【重点注意:】
集合只能存储对象,经常犯的错误:集合可以存储整型之类的基本数据类型,其实那是通过自动装箱,拆箱机制,转为了Integer对象。
【Collection中的共性方法】——【掌握程度:不用查API文档就可以写出来】
作为容器应该具备的方法:添加,删除,判断,获取。
1. 添加方法:
boolean add(Object e)—— 一次只能添加一个元素;
boolean addAll(Collection<? extends E> c)—— 将一个参数容器中的所有元素添加到当前容器中。
2. 删除方法:
boolean remove(Object e) 删除一个指定对象,
boolean removeAll(Collection<?> c) 删除指定Collection中和本Collection中相同的元素。
void clear ():直接将集合中的元素清空。
3. 判断方法:
Boolean contains (Object)是否包含指定元素
boolean containsAll(Collection<?> c) 是否包含指定容器中的元素。
boolean isEmpty(): 是否有元素。
4. 获取元素个数:
int size (),获取元素的个数;
5.取交集
boolean retainAll(Collection<?> c)
保留和指定collection集合中相同的元素,不相同的元素会被删除。
6 将集合转成数组;
Object[] toArray()
【7】取出元素的方法——【重点】
Iterator<E> iterator()
迭代器使用:
1 package api.iterator.demo; 2 import java.util.ArrayList; 3 import java.util.Collection; 4 import java.util.Iterator; 5 6 public class IteratorDemo { 7 8 public static void main(String[] args) { 9 10 //创建集合。 11 Collection coll = new ArrayList(); 12 //添加元素。 13 coll.add("abc1"); 14 coll.add("abc2"); 15 coll.add("abc3"); 16 17 /* 18 //获取该集合的迭代器对象。 19 Iterator it = coll.iterator(); //这个对象不用new ,本身内置于该接口中。 20 21 //使用迭代器对象中的方法完成元素的获取。 22 while(it.hasNext()){ 23 System.out.println(it.next()); 24 } 25 */ 26 27 //将while改成for结构。开发的时候建议写for。 28 for(Iterator it = coll.iterator(); it.hasNext(); ){ 29 System.out.println(it.next());//next()可以取出元素。而且自动往下取 30 } 31 } 32 }
【集合小细节1】
1.存储时,add可以接收任意类型的对象因为参数类型为 Object。
所以对象元素存入时都被提升为Object。
2.其实在集合中真正存储的都是对象的引用。
【用迭代器取出时,其实取出的也是引用。】
coll.add(5),不能存储基本数据类型,
jdk1.5以后,有了自动装箱机制,相当于new Integer(5),装箱Integer.valueOf(5);
等同于coll.add(Integer.valueOf(5));
【集合小细节2】——在集合中存储自定义对象;
1. 对自定义对象的描述。
存储时,都被提升为了Object;取出时,如果要使用自定义对象的特有方法,一定要进行向下转型。
注意事项:在迭代时,循环中只要有一个next()即可。
System.out.println(((Person)it.next()).getName()+ ":" + ((Person)it.next()).getAge( ));
否则将会抛出:NoSuchElementException!
java.util.NoSuchElementException
集合的技巧性掌握;
1. 明确具体集合对象名称的后缀:
如果后缀是List,都所属于List体系,通常都是非同步的。
如果后缀是Set,都所属于Set体系通常都是非同步的。
这些体系中的其他子类对象,后缀不是所属接口名的,一般都是同步的。
这在常用子类对象中通用。
2. 明确数据结构:
对于jdk1.2版本的子类对象。后缀名是所属的体系。
前缀名就是数据结构的名称。
比如:
ArrayList:看到Array,就要明确是数组结构;查询快
LinkedList:看到Link,就要明确链表结构,就要想到add get remove和 first last结合的方法。增删快
HashSet:看到hash ,就要明确是哈希表,查询快,而且所存储的对象具有唯一性。
就要想到元素必须覆盖hashCode方法和 equals方法。
TreeSet:就看到Tree,就要明确是二叉树,可以对元素排序;
就要想到两种排序方式:
自然排序:Comparable接口(内部比较器),覆盖compareTo(一个参数)java.lang
比器排序:Comparator接口(外部比较器),覆盖compare(两个参数):java.util
判断元素唯一性的依据就是比较方法的返回结果 return 0;
Collection接口
Collection是最基本的集合接口,一个Collection代表一组Object的集合,这些Object被称作Collection的元素。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个 Collection参数的构造函数用于创建一个新的Collection,这 个新的Collection与传入的Collection有相同的元素。后一个构造函数允许用户复制一个Collection。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
Iterator it = collection.iterator(); // 获得一个迭代子 while(it.hasNext()) { Object obj = it.next(); // 得到下一个元素 }
根据用途的不同,Collection又划分为List与Set。
List接口:
List继承自Collection接口。List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
跟Set集合不同的是,List允许有重复元素。对于满足e1.equals(e2)条件的e1与e2对象元素,可以同时存在于List集合中。当然,也有List的实现类不允许重复元素的存在。除了具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法,返回一个 ListIterator接口,和标准的Iterator接口相比,ListIterator多了一些add()之类的方法,允许添加,删除,设定元素, 还能向前或向后遍历。
实现List接口的常用类有LinkedList,ArrayList,Vector和Stack。
LinkedList类
LinkedList实现了List接口,允许null元素。此外LinkedList提供额外的get,remove,insert方法在 LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack), 队列(queue)或双向队列(deque)。
注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
ArrayList类
ArrayList实现了可变大小的数组。它允许所有元素,包括null。ArrayList没有同步。
size,isEmpty,get,set方法运行时间为常数。但是add方法开销为分摊的常数,添加n个元素需要O(n)的时间。其他的方法运行时间为线性。
每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并 没有定义。当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
和LinkedList一样,ArrayList也是非同步的(unsynchronized)。
Vector类
Vector非常类似ArrayList,但是Vector是同步的。由Vector创建的Iterator,虽然和ArrayList创建的 Iterator是同一接口,但是,因为Vector是同步的,当一个Iterator被创 建而且正在被使用,另一个线程改变了Vector的状态(例如,添加或删除了一些元素),这时调用Iterator的方法时将抛出ConcurrentModificationException,因此必须捕获该异常。
Stack 类
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop方 法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
Set接口
Set继承自Collection接口。Set是一种不能包含有重复元素的集合,即对于满足e1.equals(e2)条件的e1与e2对象元素,不能同时存在于同一个Set集合里,换句话说,Set集合里任意两个元素e1和e2都满足e1.equals(e2)==false条件,Set最多有一个 null元素。
因为Set的这个制约,在使用Set集合的时候,应该注意:
1,为Set集合里的元素的实现类实现一个有效的equals(Object)方法。
2,对Set的构造函数,传入的Collection参数不能包含重复的元素。
请注意:必须小心操作可变对象(Mutable Object)。如果一个Set中的可变元素改变了自身状态导致Object.equals(Object)=true将导致一些问题。
Map接口
Map没有继承Collection接口。也就是说Map和Collection是2种不同的集合。Collection可以看作是(value)的集合,而Map可以看作是(key,value)的集合。
Map接口由Map的内容提供3种类型的集合视图,一组key集合,一组value集合,或者一组key-value映射关系的集合。
Hashtable类
Hashtable继承Map接口,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。
添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。
Hashtable 通过initial capacity和load factor两个参数调整性能。通常缺省的load factor 0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大,这会影响像get和put这样的操作。
使用Hashtable的简单示例如下,将1,2,3放到Hashtable中,他们的key分别是”one”,”two”,”three”:
Hashtable numbers = new Hashtable(); numbers.put("one", new Integer(1)); numbers.put("two", new Integer(2)); numbers.put("three", new Integer(3));
要取出一个数,比如2,用相应的key:
Integer n = (Integer)numbers.get("two"); System.out.println("two =" + n);
由于作为key的对象将通过计算其散列函数来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方 法。hashCode和equals方法继承自根类Object,如果你用自定义的类当作key的话,要相当小心,按照散列函数的定义,如果两个对象相 同,即obj1.equals(obj2)=true,则它们的hashCode必须相同,但如果两个对象不同,则它们的hashCode不一定不同,如果两个不同对象的hashCode相同,这种现象称为冲突,冲突会导致操作哈希表的时间开销增大,所以尽量定义好的hashCode()方法,能加快哈希 表的操作。如果相同的对象有不同的hashCode,对哈希表的操作会出现意想不到的结果(期待的get方法返回null),要避免这种问题,只需要牢记一条:要同时复写equals方法和hashCode方法,而不要只写其中一个。
Hashtable是同步的。
HashMap类
HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。,但是将HashMap视为Collection时(values()方法可返回Collection),其迭代子操作时间开销和HashMap 的容量成比例。因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低。
WeakHashMap类
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
对集合操作的工具类
Java提供了java.util.Collections,以及java.util.Arrays类简化对集合的操作
java.util.Collections主要提供一些static方法用来操作或创建Collection,Map等集合。
java.util.Arrays主要提供static方法对数组进行操作。。
总结
如果涉及到堆栈,队列等操作,应该考虑用List,对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。
如果程序在单线程环境中,或者访问仅仅在一个线程中进行,考虑非同步的类,其效率较高,如果多个线程可能同时操作一个类,应该使用同步的类。
在除需要排序时使用TreeSet,TreeMap外,都应使用HashSet,HashMap,因为他们 的效率更高。
要特别注意对哈希表的操作,作为key的对象要正确复写equals和hashCode方法。
容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。一旦将对象置入容器内,便损失了该对象的型别信息。
尽量返回接口而非实际的类型,如返回List而非ArrayList,这样如果以后需要将ArrayList换成LinkedList时,客户端代码不用改变。这就是针对抽象编程。
注意:
1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。
2、Set和Collection拥有一模一样的接口。
3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get)
4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。
5、Map用 put(k,v) / get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。
HashMap会利用对象的hashCode来快速找到key。
6、Map中元素,可以将key序列、value序列单独抽取出来。
使用keySet()抽取key序列,将map中的所有keys生成一个Set。
使用values()抽取value序列,将map中的所有values生成一个Collection。
为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。