布隆过滤器,名字听起来有点奇怪,其实是根据一个人的名字来命名的。
布隆过滤器在wiki上的介绍:
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难
布隆过滤器使用场景:
1.网页黑名单系统、
2.垃圾邮件过滤系统、
3.爬虫的网址判重系统
4.解决缓存穿透问题
为啥要用这鬼东西?
数据量很大,数十亿甚至更多,内存装不下且数据库检索又极慢的情况,我们不妨考虑下布隆过滤器,因为它是一个空间效率占用极少和查询时间极快的算法。
布隆过滤器的自我介绍:
布隆过滤器。有一个长度为m的bit型数组,如我们所知,每个位置只占一个bit,每个位置只有0和1两种状态。假设一共有k个哈希函数相互独立,输入域都为s且都大于等于m,那么对同一个输入对象(可以想象为缓存中的一个key),经过k个哈希函数计算出来的结果也都是独立的。对算出来的每一个结果都对m取余,然后在bit数组上把相应的位置设置为1(描黑),如下图所示:
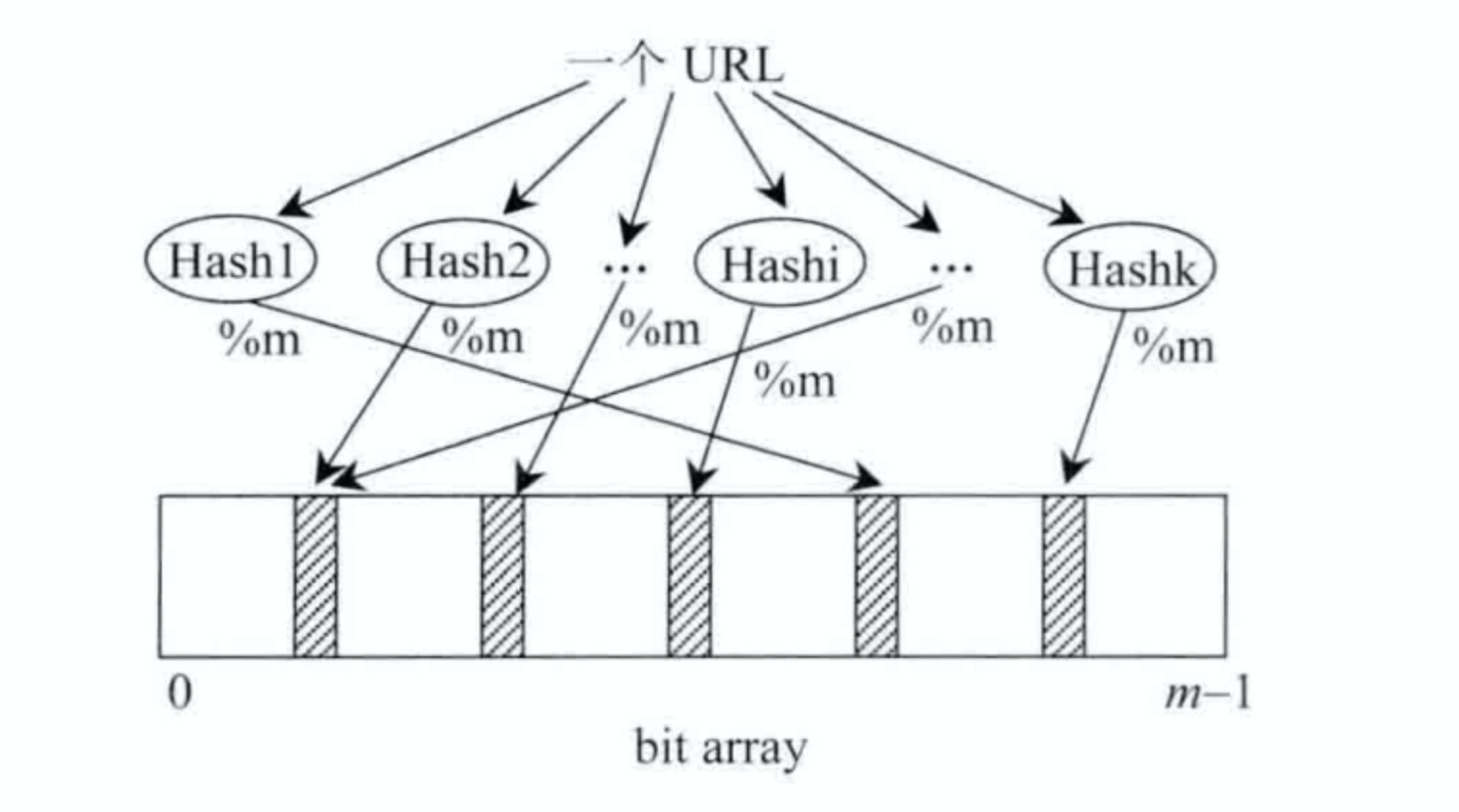
简而言之:输入对象-->哈希函数计算-->计算结果对M取余。
至此一个输入对象对bit array集合的影响过程就结束了,我们可以看到会有多个位置被描黑,也就是设置为1.
接下来所有的输入对象都按照这种方式去描黑数组,最终一个布隆过滤器就生成了,它代表了所有输入对象组成的集合。
那么如何判断一个对象是否在过滤器中呢?假设一个输入对象为hash1,我们需要通过看k个哈希函数算出k个值,然后把k个值取余(%m),就得到了k个[0,m-1]的值。然后我们判断bit array上这k个值是否都为黑,如果有一个不为黑,那么肯定hash1肯定不在这个集合里。如果都为黑,则说明hash1在集合里,但有可能误判。因为当输入对象过多,而集合过小,会导致集合中大多位置都会被描黑,那么在检查hash1时,有可能hash1对应的k个位置正好被描黑了,然后错误的认为hash1存在集合里。
控制布隆过滤器的误判率
如果bit array集合的大小m相比于输入对象的个数过小,失误率就会变高。这里直接引入一个已经得到证明的公式,根据输入对象数量n和我们想要达到的误判率为p计算出布隆过滤器的大小m和哈希函数的个数k.
布隆过滤器的大小m公式:
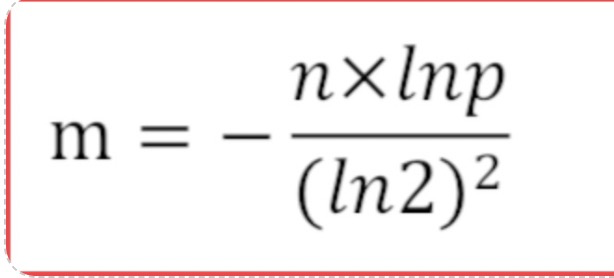
哈希函数的个数k公式:
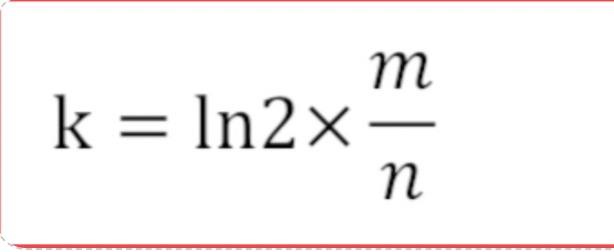
布隆过滤器真实失误率p公式:
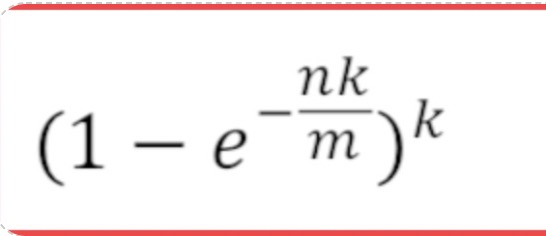
假设我们的缓存系统,key为userId,value为user。如果我们有10亿个用户,规定失误率不能超过0.01%,通过计算器计算可得m=19.17n,向上取整为20n,也就是需要200亿个bit,换算之后所需内存大小就是2.3G。通过第二个公式可计算出所需哈希函数k=14.因为在计算m的时候用了向上取整,所以真是的误判率绝对小于等于0.01%。
(科普下:1KB=1024bit,1M=1024KB,1G=1024M)
那么项目中如何使用布隆过滤器呢?
其实人家外国人已经实现过了,唉,难道我大中华就没有自己开发的吗,老是用人家的轮子。
不过用一下就用一下吧。
步骤:
1.引入pom依赖:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>25.1-jre</version> </dependency>
2.使用的代码例子:
public static void main(String... args){ /** * 创建一个插入对象为十亿,误报率为0.01%的布隆过滤器 */ BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 1000000000, 0.0001); bloomFilter.put("121"); bloomFilter.put("122"); bloomFilter.put("123"); System.out.println(bloomFilter.mightContain("121")); }
说到这个可能包含,mightContain,我想要是查询下全中国人有多少人没发年终奖,没发的发一个月工资,刚好我这个没发年终奖的人显示已经发了,那我就惨了。