一、聚合函数
聚合函数。称为统计函数
常用的聚合函数
count()总量数
max()最大值
min()最小值
sum()和
avg()平均值
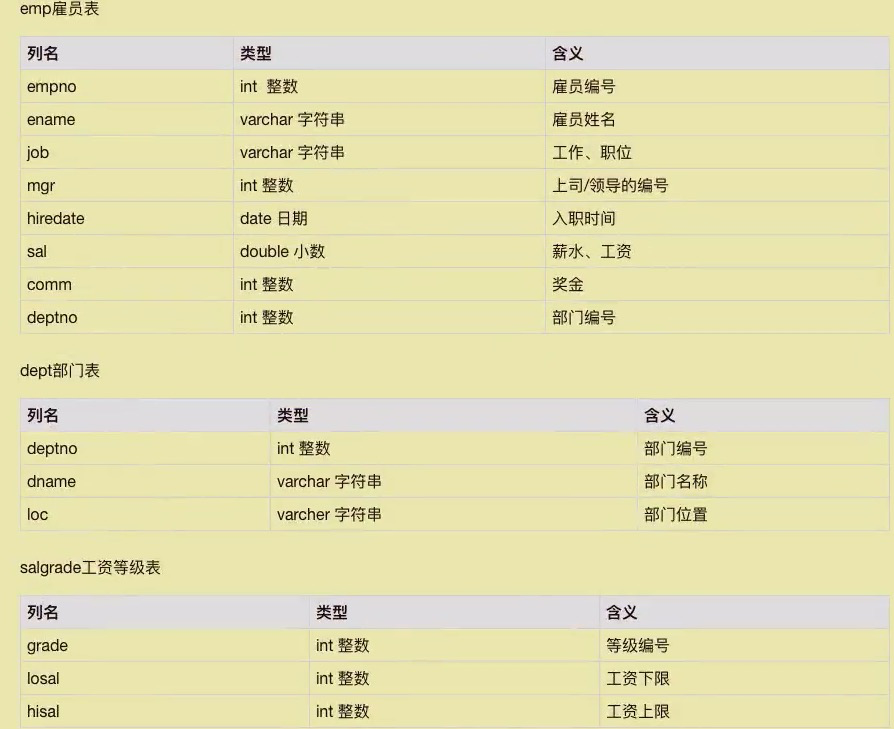
例:查询部门30的总人数(查询总人数,根据empno编号确定有多少编号,就有多个人)
select count(empno)from emp where deptno=30; count()括号是统计总数量,必须要传的
⚠️聚合函数在统计时会忽略null值。
select sum(sal)where emp where deptno=10;
select avg(sal) where emp where deptno=10;
例:查询部门30的最高工资、最低工资、平均工资
select max(sal),min(sal),avg(sal)from emp where deptno = 30;
二、分组统计
语法:
select 列名1 别名1,列名2 别名2...
from 表名1 别名1 inner join 表名2 别名2 on 多表间的关联关系
where 条件(分组之前的条件)
group by 分组列
having (分组之后的条件)
order by 排序1 asc|desc,排列2 asc|desc....;
举例:
查询每个部门的平均工资
select deptno,avg(sal)
from emp
group by deptno;
select dname ,avg(sal)
from emp e,dept d
where e.empno = d.depno
group by d.dname
⚠️:在mysql中分组统计时可以查出分组列的其他列,而在orcal中不行
建议将要查询出的列使用分组列
查询出部门的名称以及每个部门的员工数量
select d.dname,count(e.empno)
from dept d left join emp e on d.deptno = e.deptno
group by d.dname
查询平均工资大于2000的部门的编号或者平均工资
select deptno , avg(sal)from emp group by deptno having avg(sal)>2000;
查询出非销售人员的职位名称,以及从事同一工作的雇员的月工资综合,并且满足工资综合大于5000,查询结构按照月工资综合生序排序
解题思路:
1、先写出整体的关键字出来
2、思考需要查询几张表,把可能查询的表下载from 后。 只查询emp表
3、考虑有没有分组之前的条件, 非销售人员的职位。 job!=‘salesman’
4、思考需要按照什么分组。 按照job分组
5、思考分组后的条件。 满足工资综合大于5000. sum(sal)>5000
6、升序排序
select job ,sum(sal) sum
from emp
where job!='salesman'
group by job
having sum(sal)>5000
order by sum