再写 HDFS Federation机制的时候,发现基础不扎实,需要将之前的hadoop再详细记录一下原理(重点只说Hadoop2.0版本):
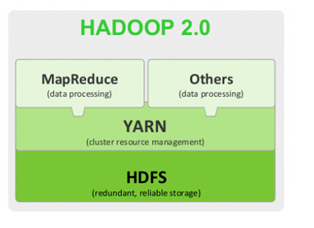
Hadoop2.0版本,引入了Yarn。核心:HDFS+Yarn+Mapreduce
Yarn是资源调度框架。能够细粒度的管理和调度任务。此外,还能够支持其他的计算框架,比如spark等。
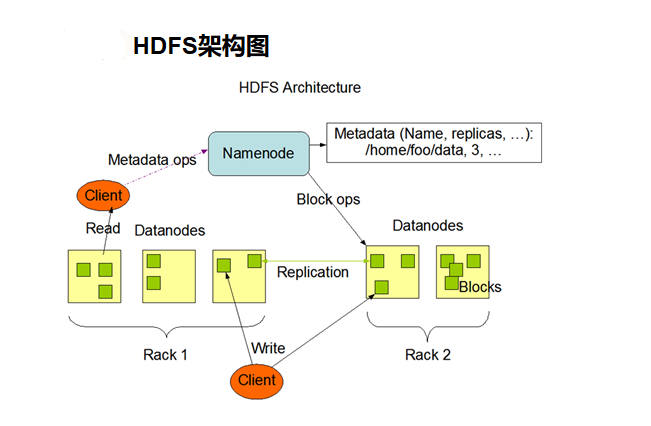
存储的基础知识以及原理:
元数据信息和具体数据,分别对应namenode和datenode:
namenode工作职责:
1.要知道管理有哪些机器节点,即有哪些datanode。比如ip信息等。
2.要管理文件信息,文件名、文件多大、文件被切成几块、以及每一块的存贮位置信息(存在哪个datanode节点上了),即管理元数据信息。
3.要有一个机制要知道集群里datanode节点的状态变化。可以rpc心跳机制来做到。
4.namenode存在单点故障问题,可以再引入一台管理者节点。
5.datanode挂掉后,可能数据就丢失,文件就不完整了,要有一个备份机制,一般来说,一个文件块,有3个备份,本机一份,同一机架的其他datanode有一份,另外一机器的机器上有一份。
管理元数据信息,文件名,文件大小,文件块信息等。
namdenode把元数据信息存到内存里,为了快速查询,此外为了应对服务宕机而引起的元数据丢失,也要持久化到本地文件里。
namdenode不存储具体块数据,只存储元数据信息;datanode用于负责存储块数据。
fsimage、edits
fsimage 文件,记录元数据信息的文件
edits文件,记录元数据信息改动的文件。只要元数据发生变化,这个edits文件就会有对应记录。
fsimage和edits文件会定期做合并,这个周期默认是3600s。fsimage根据edits里改动记录进行元数据更新。
元数据信息如果丢失,HDFS就不能正常工作了。
hadoop namenode -format 这个指令实际的作用时,创建了初始的fsimage文件和edits文件。
namenode对于元数据信息的管理,放在内存一份,供访问查询,也会通过fsimage和edits文件,将元数据信息持久化到磁盘上。
Secondarynamenode
负责将fsimage文件定期和edits文件做合并,合并之后,将合并后的元数据文件fsimage传给namenode。这个SN相当于namenode辅助节点。
Hadoop集群最开始启动的时候,创建Fsimage和edits文件,这个namenode做的,此外,namenode会做一次文件合并工作,这么做的目的是确保元数据信息是最新的,以为上次停集群的时候,可能还没来的及做合并。但以后的合并工作,就交给SN去做了。这种SN机制是Hadoop1.0的机制。
结论:Hadoop1.0的SN达不到热备效果,达不到元数据的实时更新,也就意味着了当namenode挂了的时候,元数据信息可能还会丢失,所以,Hadoop1.0版本的namenode还是单点故障问题。
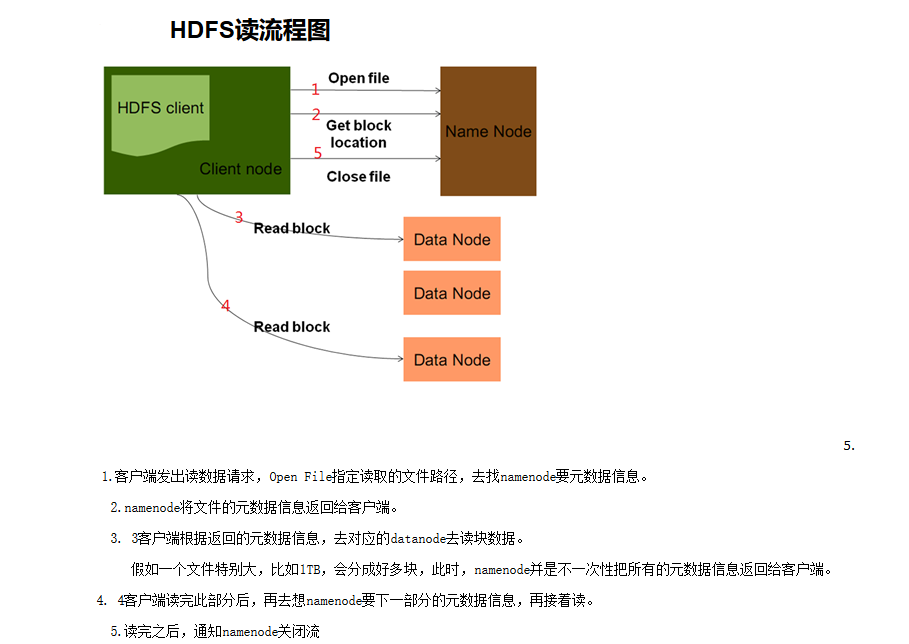
datanode:
数据节点。用于存储文件块。为了防止datanode挂掉造成的数据丢失,对于文件块要有备份,一个文件块有三个副本。

参考:https://www.cnblogs.com/tieandxiao/p/8799287.html