这两个算法都可以解决线性分类问题和非线性分类问题(都使用kernel trick)。
如果是非线性分类,那么我们就首选SVM。
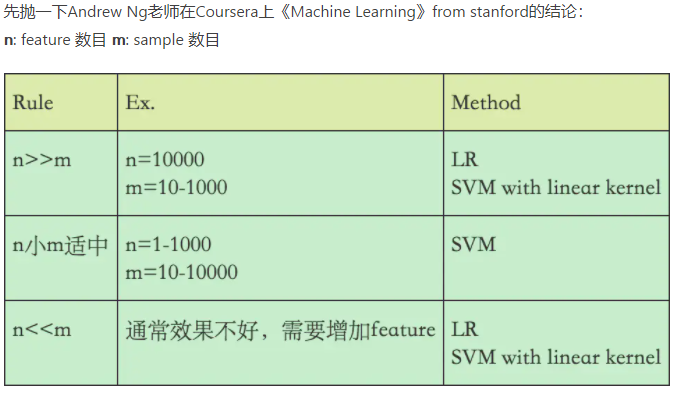
- SVM不是概率输出,Logistic Regression是概率输出。
也就是说,当一个新样本来了,SVM只会告诉你它的分类,而Logistic Regression会告诉你它属于某类的概率!
什么意思呢?当你想要知道某个样本属于一个类的概率时,SVM就不适用了。此时,应该使用Logistic Regression。
那么问题来了,点到SVM分类面的距离,是否可以转化为“概率输出”呢,即离分类面越远,其属于该类的概率越大,反之越小呢?《PRML》里确实提过类似的做法,也有一些其他的办法让SVM输出概率,但作者说这些方法都不太实用。
-
异常点的鲁棒性问题
当训练样本中存在异常点时,由于Logistic Regression的lost function中有每一个点的贡献,所以某种程度上“削弱了”异常点的贡献。而SVM只需要考虑支持向量,此时支持向量本来就不是很多的情况下,几个异常点就很有可能极大影响SVM的表现。 -
目标函数 lost function
Logistic Regression使用entropy loss,极大化似然函数。
而SVM使用hinge loss, 最大化间隔。两个loss差别不是很大,所以算是一个相同点了。 -
实际问题:
实际问题中,如果数据量非常大,特征维度很高,使用SVM搞不定时,还是用Logistic Regression吧,速度更快一些。