统计学中的变量指的是研究对象的特征,我们有时也称为属性,例如人的身高、性别等。
每个变量都有变量的值和变量的类型。我们按照变量的类型对变量进行划分。
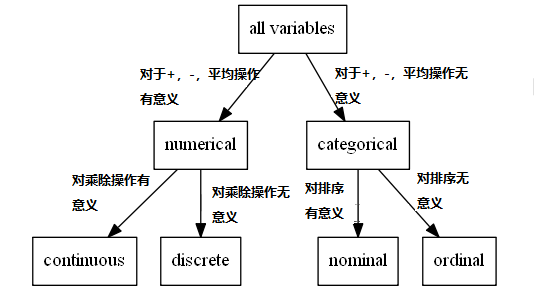
统计学中的变量(variables)大致可以分为数值变量(numrical)和分类变量(categorical)。
数值型变量是值可以取一些列的数,这些值对于 加法、减法、求平均值等操作是有意义的。而分类变量对于上述的操作是没有意义的。
数值变量又可以分为下面两类:
离散型变量(discrete):值只能用自然数或整数单位计算,其数值是间断的,相邻两个数值之间不再有其他数值,这种变量的取值一般使用计数方法取得。
连续型变量(continuous):在一定区间内可以任意取值,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。如身高、绳子的长度等。
和离散型变量相比,连续型变量有“真零点”的概念,所以可以进行乘除操作。
分类变量又可以分为下面两类:
有序分类变量(ordinal):描述事物等级或顺序,变量值可以是数值型或字符型,可以进而比较优劣,如喜欢的程度:很喜欢、一般、不喜欢 。
无序分类变量(nominal):取值之间没有顺序差别,仅做分类,又可分为二分类变量和多分类变量 二分类变量是指将全部数据分成两个类别,如男、女,对、错,阴、阳等,二分类变量是一种特殊的分类变量,有其特有的分析方法。 多分类变量是指两个以上类别,如血型分为A、B、AB、O。
有序分类变量和无需分类变量的区别是:前者对于“比较”操作是有意义的,而后者对于“比较”操作是没有意义的。
这四种数据的等级从低到高依次为:无序分类变量(nominal) <有序分类变量(ordinal)< 离散型数值变量(discrete)< 连续型数值变量(continuous)。
下面的一张图描述了它们之间的关系: