1. 了解各个组件的作用
Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读)
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据
Logstash是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景
ElasticSearch它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
Kibana是ElasticSearch的用户界面
在实际应用场景下,为了满足大数据实时检索的场景,利用Filebeat去监控日志文件,将Kafka作为Filebeat的输出端,Kafka实时接收到Filebeat后以Logstash作为输出端输出,到Logstash的数据也许还不是我们想要的格式化或者特定业务的数据,这时可以通过Logstash的一些过了插件对数据进行过滤最后达到想要的数据格式以ElasticSearch作为输出端输出,数据到ElasticSearch就可以进行丰富的分布式检索了
2. 安装各个组件并部署,并配置各个组件的关联配置文件
下载各个组件的安装包并解压(这些组件在Apache官网都可以下载得到)




Filebeat安装
解压后Filebeat的目录
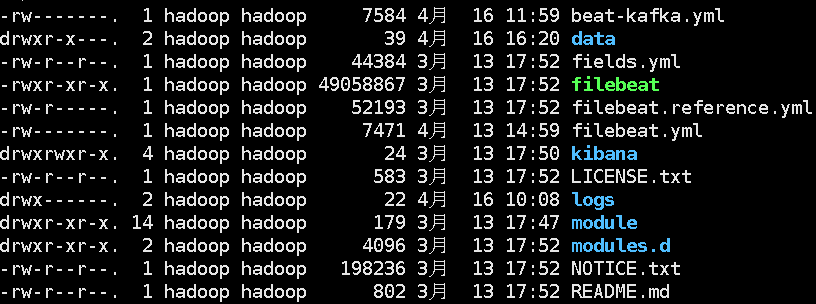
Filebeat的配置很简单,只需要配置监控的日志文件的全路径和输出端的IP,一般默认(默认配置文件filebeat.yml)是输出到ElasticSearch,输出配置如下
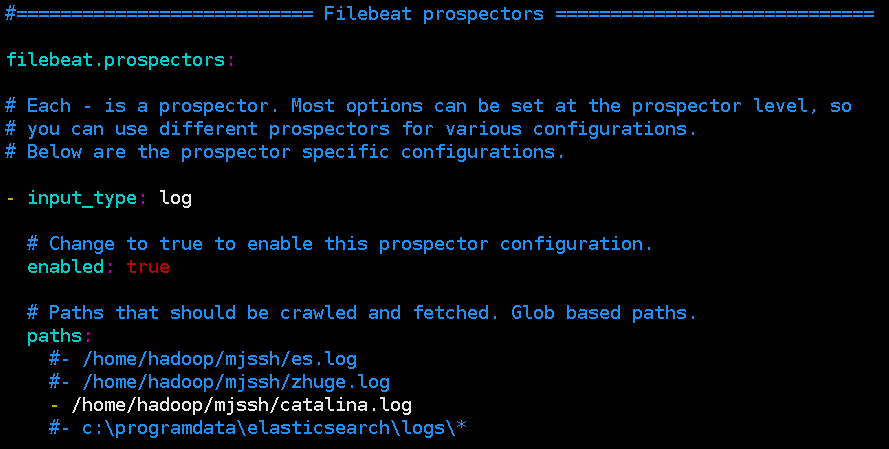
输出端配置
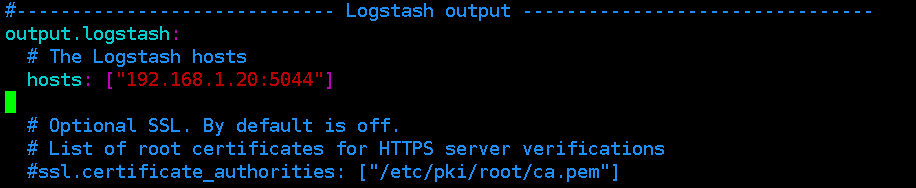
这里我们不直接输出到ElasticSearch,而是kafka,所以需要配置 beat-kafka.yml,输入端配置如下
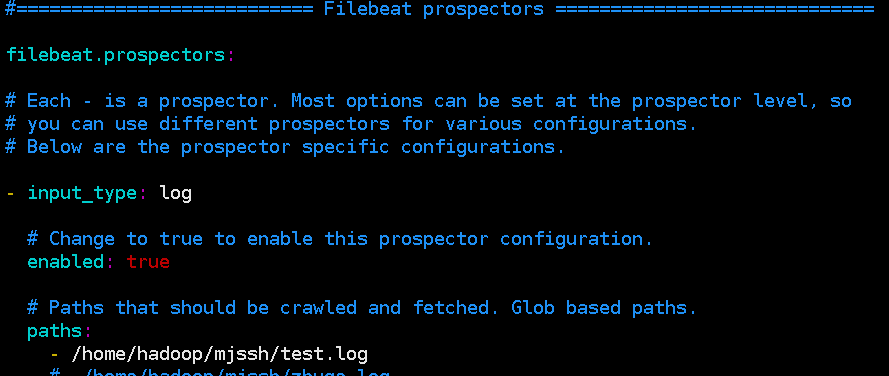
输出端配置

因为是输出到kafka,所以需要制定kafka的topic
Kafka的安装
在Filebeat已经配置输出端为kafka的配置,这里kafaka不需要配置任何东西,解压直接用,以下是kafka初用的几个必须的命令,具体查看kafka的官方API
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
现在启动Filebeat:
./filebeat -e -c beat-kafka.yml -d "publish"
这里需要说明一点,不同的输出端可以配置不同的.yml文件,所以这里的 beat-kafka.yml文件是kafka对应的配置
以上命令输出没有报错并有如下信息

且可以看到你的监控文件的log的信息字段证明不存在问题
这是kafka的consumer会有如下信息

message就是文件的具体信息
Logstash的安装
Logstash也不要做太多的配置,从搭建Filebeat和Kafka时,已经实现了数据的流通,现在要完成的事是然流到kafka的数据流到logstash,logtash也需要输出,将ElasticSearch作为输出端
对于kafka不同的数据建议logstash用不同的通道去接
一下是配置的两个不同的通道

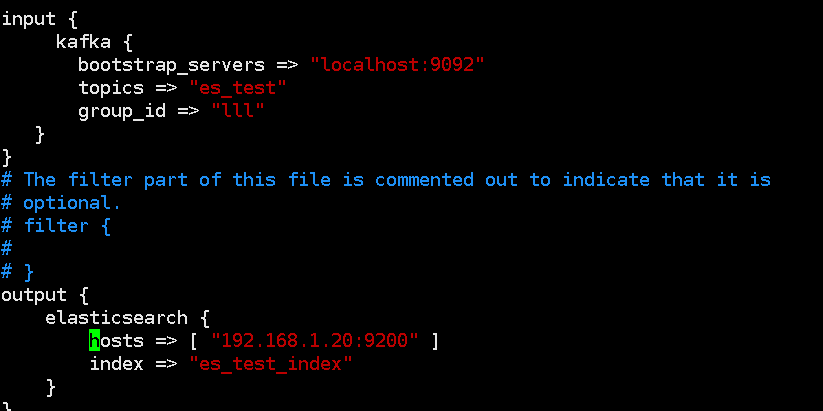
启动logstash
bin/logstash -f first-pipeline.conf --config.reload.automatic --path.data=/home/hadoop/logstash
--path.data=/home/hadoop/logstash是指存放数据的路径
ElasticSearch配置和安装
如果你不要更改ip的话那就不需要任何配置,直接启动
sh bin/elasticsearch
通过elasticsearch查询看整个架构是否完整数据是否正确流通
查看索引
curl '192.168.1.20:9200/_cat/indices?v'

根据索引查询数据
curl -XGET '192.168.1.20:9200/test_index/_search?pretty'

这就证明我们整个架构是正确的且数据流通无误
Kibana的配置和安装
Kibana只是ElasticSearch的图形化界面,启动即用