1.Spark JVM参数优化设置
Spark JVM的参数优化设置适用于Spark的所有模块,包括SparkSQL、SparkStreaming、SparkRdd及SparkML,主要设置以下几个值:
spark.yarn.driver.memoryOverhead #driver端最大的堆内存,设置为driverMemory*0.1,不小于384m
spark.yarn.excutor.memoryOverhead #excutor端最大的堆内存,设置为executorMemory* 0.1, 不小于384m
spark.driver.extraJavaOptions #driver端一系列额外的JVM选项,这个可以自行设置
spark.executor.extraJavaOptions #executor端一系列额外的JVM选项,这个可以自行设置
现在假设基础的driver,excutor内存配置如下
driver_memory=10g
spark_executor_memory=30g
那么相对于的JVM优化参数配置如下
SparkConf conf = new SparkConf().setAppName("My-test");
conf.set("spark.yarn.driver.memoryOverhead","1g");
conf.set("spark.yarn.excutor.memoryOverhead","3g");
conf.set("spark.driver.extraJavaOptions","-XX:MaxPermSize=2g -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:ConcGCThreads=8 -XX:+CMSParallelRemarkEnabled");
conf.set("spark.executor.extraJavaOptions","-Xmn2g -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:ConcGCThreads=8 -XX:+CMSParallelRemarkEnabled -XX:-UseGCOverheadLimit");
说明:
a.如上spark.driver.extraJavaOptions设置的值的解释
-XX:MaxPermSize=2g #指非堆区最大内存分配上限为2g
-XX:+UseConcMarkSweepGC #并行并发CMS垃圾回收器
-XX:+CMSConcurrentMTEnabled #当该标志被启用时,并发的CMS阶段将以多线程执行
-XX:ConcGCThreads=8 #执行GC的线程数为8个
-XX:+CMSParallelRemarkEnabled #降低标记停顿
-XX:-UseGCOverheadLimit #限制GC的运行时间。如果GC耗时过长,就抛OOM
-Xmn2g #设置年轻代大小为2G
Spark JVM的基础优化平时开发中注意以上几个参数优化在一般的业务中够用了。但并不仅仅是这些参数的优化,详细的参数请参照官网(http://spark.apache.org/docs/latest/configuration.html), 当然这个也需要同时结合JDK JVM的优化
2.Sparkstreaming参数优化设置
Sparksql的一些优化在Spark基础参数和Spark JVM的基础上就差不多了,但还是需要一些特定的优化,之前有专门写过,可以参考之前的博客(https://www.cnblogs.com/jiashengmei/p/11678440.html), 而Sparkstreaming还需要如下几个参数的特定优化
spark.streaming.kafka.maxRatePerPartition #从kafka每个分区读取数据的最大纪录数
spark.streaming.blockInterval #spark流式接收器接收到的数据在存储到Spark中之前被分块到数据块中的时间间隔。建议最小值为50毫秒。
spark.streaming.duration #每个批次的间隔时间
现在假设基础的driver,excutor配置如下
driver_memory=10g
spark_executor_memory=30g
num_executors=6
executor_cores=1
配置sparkstreaming独有的配置如下:
streaming_kafka_maxRatePerPartition=1000
streaming_blockInterval=1000
streaming_duration=60
现在假设kafka的分区数是3,那么Spark在一个batch里面处理的条数一定不超6*3*1000*10=18000。如果不设置会怎样?现在假设要写入的topic在Sparkstreaming未启动就写入了1亿条数据,如果不进行这样的甚至会导致程序一启动,第一个batch直接拉取这一亿条数据,一个批次处理一亿条数据最终必然导致内存溢出等错误导致程序停止。下图展示的是sparkstreaming程序未启动已经写入几十万条数据batch的数据状态
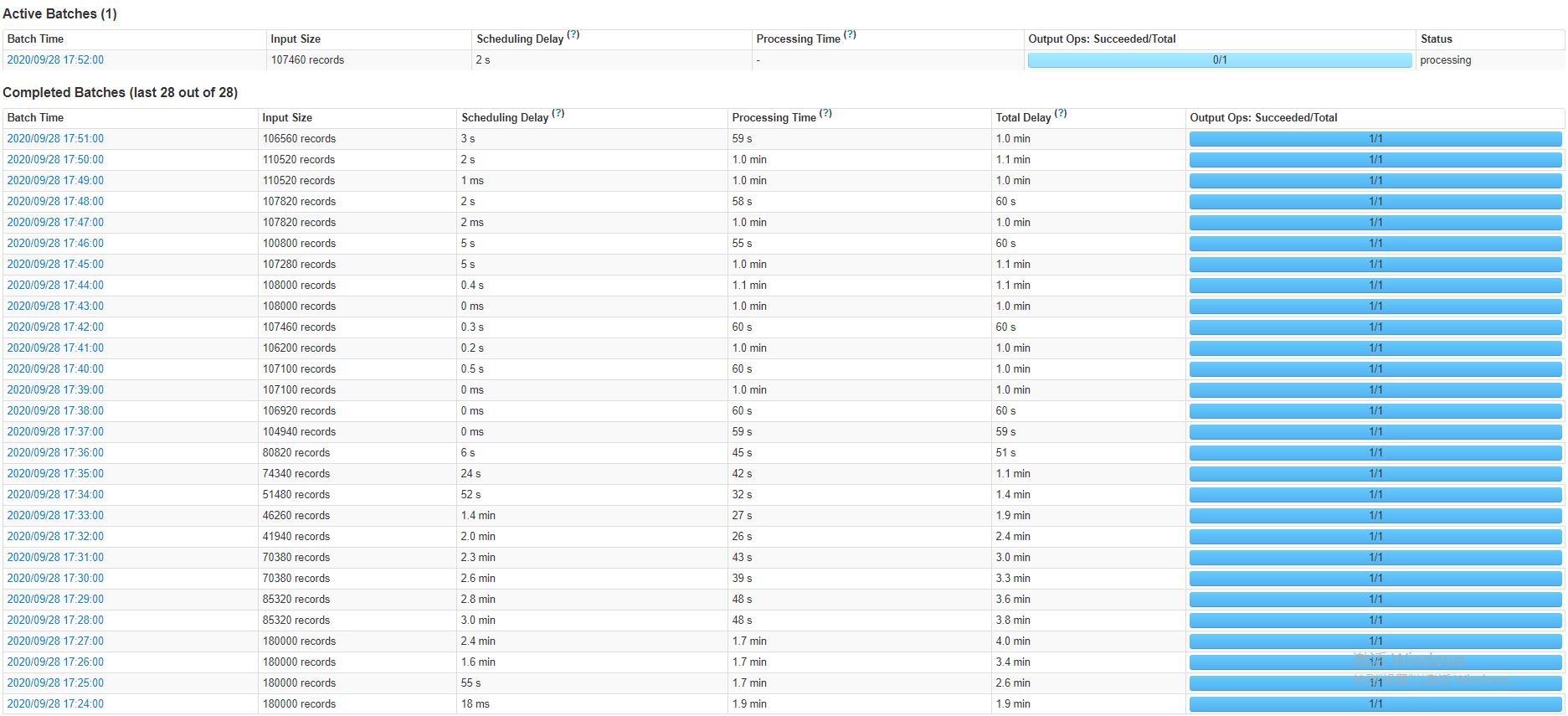
可以看出程序启动发现数据太多,按最大的拉取,等消费差不多后。根据实际数据量拉取,但是拉取的总不会超过最大值。
3.Spark反压机制
因特殊业务场景,如大促、秒杀活动与突发热点事情等业务流量在短时间内剧增,形成巨大的数据流入的速度远高于数据处理的速度,对流处理系统构成巨大的负载压力,如果不能正确处理,可能导致集群资源耗尽最终集群崩溃,因此有效的反压机制(backpressure)对保障流处理系统的稳定至关重要。可以简单总结为对于spark的反压机制是对于某些数据洪峰的应对策略,可以根据处理效率动态调整摄入速率。
反压机制可以根据参数设置开启,同时也可以自定呀反压策略,这里不举例自定义反压策略。值说明反压的作用和如何配置
SparkConf conf = new SparkConf().setAppName(parameterParse.getSpark_app_name());
//启用反压
conf.set("spark.streaming.backpressure.enabled","true")
//最小摄入条数控制
conf.set("spark.streaming.backpressure.pid.minRate","1")
//最大摄入条数控制
conf.set("spark.streaming.kafka.maxRatePerPartition","1000")
JavaSparkContext sc = new JavaSparkContext(conf);
//每个批次的间隔时间
JavaStreamingContext ssc = new JavaStreamingContext(sc, Seconds.apply(Long.parseLong(5000)));
关于反压机制的详细概念解释这边博客讲得比较全面(https://www.cnblogs.com/lenmom/p/12022277.html), 关于反压机制自定义策略后面有时间会结合Flink的反压机制统一给出
4.注意
在sparkstreaming里面不建议使用repartition,如下
JavaInputDStream<ConsumerRecord<String, String>> dStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent(), ConsumerStrategies.Subscribe(topicsSet, kafkaParamsConsumer));
dStream.repartition().foreachRDD(rdd -> {//逻辑处理})