hbase-2.0.4集群部署
1. 集群节点规划:
rzx1 HMaster,HRegionServer
rzx2 HRegionServer
rzx3 HRegionServer
前提:搭建好hadoop集群
2. 在rzx1节点上配置执行环境的JAVA_HOME和是否利用自带Zookeeper
在hbase目录下:vim conf/hbase-env.sh
export JAVA_HOME=/home/bigdata/software/jdk1.8.0_201
export HBASE_MANAGES_ZK=false ##不使用自带Zookeeper
其他配置参数在配置开发测试集群使用默认,生产环境根据数据量而定配置
3. 在rzx1节点上配置hbase在HDFS上存储的路径和外部zookeeper地址
在hbase目录下:vim conf/ hdfs-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://rzx1:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>rzx1,rzx2,rzx3</value>
</property>
</configuration>
注意在配置zk的时候只配置域名或IP就可以了,不要配置端口如rzx1:2181这样配置虽然对zookeeper启动没有任何影响,但是之后如果搭建kylin集群会报错的
4. 将hadoop etc/hadoop下的core-site.xml,hdfs-site.xml复制到hbase conf/下
在hbase目录下(hbase和hadoop同级目录)
cp ../hadoop-2.7.7/etc/hadoop/core-site.xml conf/
cp ../hadoop-2.7.7/etc/hadoop/core-site.xml conf/
因为hbase的数据本质上存储在hdfs的,且hbase执行引擎是MapReduce
5. 配置HRegionServer,修改 regionservers文件
在hbase目录下:vim conf/regionservers
rzx1
rzx2
rzx3
如果想rzx1上只是HMaster,则配rzx2,rzx3即可
6. 在主节点rzx1上将配置好的hbase目录scp到rzx2,rzx3上
在hbase目录的上层目录下:
scp -r hbase-2.0.4 root@rzx1:/home/bigdata/software/
scp -r hbase-2.0.4 root@rzx2:/home/bigdata/software/
7. 在三个节点上都配置hbase环境变量
前提:已经配置好java, hadoop, hive,zookeeper环境变量
vim ~/.bashrc添加:
export HBASE_HOME=/home/bigdata/software/hbase-2.0.4
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZK_HOME/bin:$KAFKA_HOME/bin:$HBASE_HOME/bin:$HCAT_HOME/bin:$KYLIN_HOME/bin:$PATH
8. 在主节点上启动hbase
前提:已经正确启动zookeeper集群
start-hbase.sh
9. jps查看进程
rzx1节点上应该有: HMaster, HRegionServer这两个进程
rzx2,rzx3节点上只有HRegionServer一个进程
10. 启动无误后可以访问hbase web UI界面: http://rzx1:16010/master-status
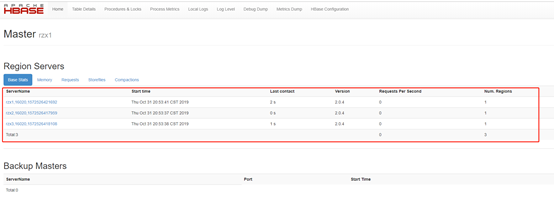
主要查看ServerName是否和预期一致,也就是配置的HRegionServer
说明:这里只是简易的开发测试集群搭建配置,实际数据量过大的生产环境配置可能相对复杂些