1.写在前面
Spark是专为大规模数据处理而设计的快速通用的计算引擎,在计算能力上优于MapReduce,被誉为第二代大数据计算框架引擎。Spark采用的是内存计算方式。Spark的四大核心是Spark RDD(Spark
core),SparkSQL,Spark Streaming,Spark ML。而SparkSQL在基于Hive数仓数据的分布式计算上尤为广泛。本编博客主要介绍基于Java API的SparkSQL的一些用法建议和利用Spark处理各种大数据计算的性能优化建议
2.SparkSQL的一些用法及建议
实例化SparkSSql的SparkSession,Spark2.0之后都是利用SparkSession来进行SparkSQL,2.0以前是利用SparkSQLContext
SparkConf conf = new SparkConf().setAppName("sql-app");
setSparkConf(parameterParse, conf);
JavaSparkContext jsc = new JavaSparkContext(conf);
SparkSession.clearDefaultSession();
SparkSession session = SparkSession.builder().appName(parameterParse.getSpark_app_name())
.config("hive.metastore.uris", parameterParse.getHive_metastore_uris())
.config("spark.sql.warehouse.dir", parameterParse.getHive_metastore_warehouse_dir())
.enableHiveSupport().getOrCreate();
实例化之后直接执行Hive查询语句
session.sql("select name,age,job from employee").foreachPartition(iterator -> {
while (iterator.hasNext()) {
Row row = iterator.next();
//逻辑处理
}
});
注意:
a.这里的查询语句只要在hive命令能正确执行的都可以
b.这里的foreachPartition相当于对数据的一个遍历,iterator得到对数据rdd集遍历的一个迭代器,Row就是hive的每行数据,例如['Tom','25','软件工程师'],遍历之后可以对数据做任何的逻辑操作,也可以写到其他组件如hbase,mysql中。
建议:
a.假设将hive数据利用SparkSQL查询出来写入mysql中,对于小部分数据不建议在遍历rdd遍历,创建连接写入mysql,类似如下写法
session.sql("select min(age),max(age)from employee").foreachPartition(iterator -> {
Connection conn = MysqlConnectionPool.getConnection(mysqlConnectBroadcast.getValue(), mysqlUserBroadcast.getValue(), mysqlPasswordBroadcast.getValue());
String maxRecordPositionValue = "";
while (iterator.hasNext()) {
Row row = iterator.next();
min = row.get(0).toString();
max = row.get(1).toString();
}
String sql = "update employee_age set max_age=? where min_age=?";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, Integer.parseInt(min));
ps.setString(2, Integer.parseInt(max));
ps.executeUpdate();
MysqlConnectionPool.release(ps, conn);
});
这样写法会导致每个task创建mysql连接,如果在session.sql("select min(age),max(age)from employee").foreachPartition()外部也有写入mysql的逻辑,这样会造成mysql连接过多,从而导致在PreparedStatement,ResultSet错乱甚至会出现Sql异常。建议利用collectAsList()这个方法来实现,类似如下写法
List<Row> minAndMaxAgeList = session.sql("select min(age),max(age)from employee").collectAsList()
min = minAndMaxAgeList.get(0).get(0).toString();
max = minAndMaxAgeList.row.get(1).toString();
这里得到的值只有两个,对于session.sql()查大数据,如查询几亿条数据,首先第一种方法更加不合适,会造成不断的建立连接,关闭连接,同时写入太过频繁导致mysql崩溃。其次大数据量应该避免这样写到mysql,不管是第一种还是第二种方法。因为第二种方法可能导致GC崩溃。
b.如果实在要在foreachPartition里写,建议mysql的链接方式应该通过广播遍历传入
final Broadcast<String> mysqlConnectBroadcast = jsc.broadcast(parameterParse.getMysql_conn());
final Broadcast<String> mysqlUserBroadcast = jsc.broadcast(parameterParse.getMysql_user());
final Broadcast<String> mysqlPasswordBroadcast = jsc.broadcast(parameterParse.getMysql_password());
c.对于Row这个SparkSQL特殊的对应,很多新手会直接row.toString()得到一个数组字符串,再对数组字符串做数组切割,这种用法在逻辑上不存在问题,但是在大数据中,数据可能是多种多样的,这样写法会造成数据错乱问题,应该用如下写法
min = row.get(0).toString();
max = row.get(1).toString();
row本质上是一个集合对象,所以提供类似集合操作的方法。
3.Spark的性能优化
关于这个网上很多配置参数的建议,让开发者看的很缭乱,以下是精简的,可以应用于常规开发中
a.参数级的优化
spark_driver_memory=4g
spark_num_executors=6
spark_executor_memory=4g
spark_executor_cores=1
spark_executor_memory_over_head=1024
spark_sql_shuffle_partitions=18
spark.default.parallelism=18
主要是这六个参数,这七个个参数的说明如下
spark_driver_memory设置driver的内存大小
spark_num_executors设置executors的个数
spark_executor_memory设置每个spark_executor_cores的内存大小
spark_executor_cores设置每个executor的cores数目
spark_executor_memory_over_head设置executor执行的时候,用的内存可能会超过executor-memoy,所以会为executor额外预留一部分内存。该参数代表了这部分内存
spark_sql_shuffle_partitions设置executor的partitions个数,注意这个参数只对SparkSQL有用
spark.default.parallelism设置executor的partitions个数,注意这个参数只对SparkRDD有用
对于这七个参数,需要充分理解Spark执行的逻辑才能明白并合适的配置,Spark的执行逻辑如下(这里不再细讲),可以参照这边博客https://www.cnblogs.com/cxxjohnson/p/8909578.html 或官方API
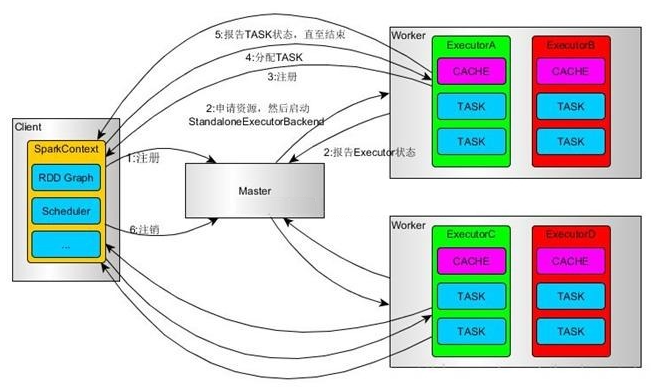
其中关于内存的配置要结合hadoop yarn的集群的资源情况而定,不是越大越好。而对于spark_num_executors,spark_executor_cores,spark_sql_shuffle_partitions这三个参数,根据实际的经验需满足spark_sql_shuffle_partitions=spark_num_executorsspark_executor_cores3,而spark_executor_cores一般保持在1
再提交任务时:
spark-submit
--master yarn
--deploy-mode cluster
--num-executors $spark_num_executors
--driver-memory $spark_driver_memory
--executor-memory $spark_executor_memory
--executor-cores $spark_executor_cores
--queue yarn_queue_test
--conf spark.app.name=spark_name_test
--conf spark.yarn.executor.memoryOverhead=$spark_executor_memory_over_head
--conf spark.core.connection.ack.wait.timeout=300
--conf spark.dynamicAllocation.enabled=false
--jars test.jar
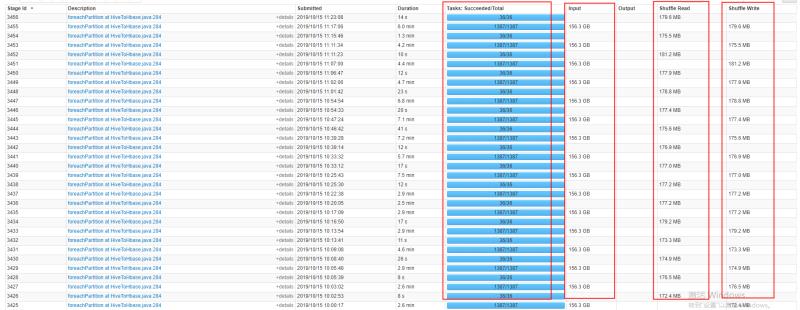
b.Task数据分布的优化
在一般情况下Task数据分配是随机默认的,这样会带来一个问题,如果多大的Task,而只是部分的Task数据处理量大,大部分很小,那么如果能做到将小部分的Task数据处理量优化到和大部分的大致相等,那么性能自然就提升上去了。这样优化分为两步:
a.在执行的Java代码中获取num_executors参数的值,上面的例子是spark_num_executors=6
int rddPartition = Integer.parseInt(parameterParse.getNum_executors()) * 3;
b.不管是rdd的遍历还是直接的session.sql("sql").foreachPartition()在遍历之前加上一个方法repartition(partition)
session.sql(sqlStr).repartition(partition).foreachPartition(iterator -> {
while (iterator.hasNext()) {
Row row = iterator.next();
//逻辑处理
}
});
这样做后,在任务的管理页面看到的executor数据分布式非常均匀的,从而提高性能
c.分而治之
分而治之是贯穿整个大数据计算的核心,不管是MapReduce,Spark,Flink等等,而这里要说的分而治之可以初略的物理流程上的分而治之,而不是对Spark的driver,executor,Task分而治之,因为本身就是分布式的分而治之。假设经过反复的性能压力测试,得出Spark在现有规定资源上只有1000000条/s的性能,而现在的数据有一亿条。现在不做任何处理提交session.sql("sql").foreachPartition()或rdd.foreachPartition(),虽然最终会处理完,但发现时间是比预定的100000000/1000000s多得多,这样会拖累整体性能,这个时候是可以对现有的一亿条数据做以1000000条为组的组合切割分配成100000000/1000000个集合,对集合数据依次执行,这样性能上会有所提升。当然这种优化方式还是需要跟实际业务逻辑来定