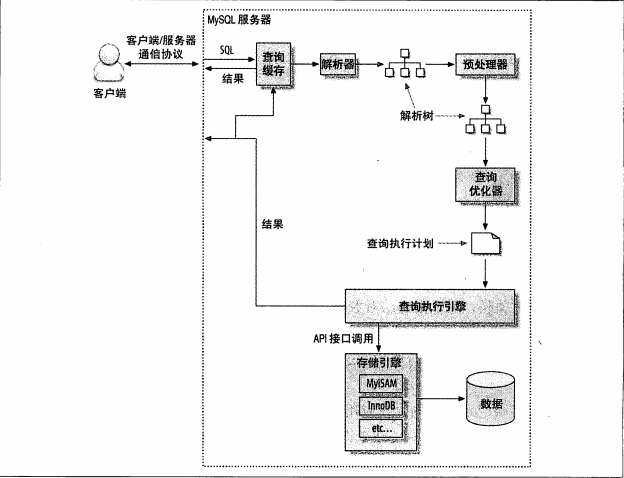
(1)查询生命周期:
从客户端到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回给客户端。
执行是整个生命周期中,最重要的阶段。
(2)慢查询基础:
优化数据访问,减少访问的数据行。
(3)查询不需要的记录:mysql有时不是仅仅去返回只需要的数据,而是现将所有的数据先返回
客户端再抛弃绝大部分数据。
总是取出全部的列:select *
重复查询相同的数据:反复调用同一个sql 可以先把结果缓存起来。
(4)衡量查询开销的指标
响应时间:服务时间+排队时间
扫描的行数:
返回的行数:通常下扫描和返回的行数相同,但是在关联查询的条件下
则不同。
(5)索引让Mysql以最高效、扫描行数最小的方式找到需要的记录。
(6)尽量选择一个大查询去替换多个实现同样效果的小查询。
(7)分解关联查询:
让缓存的效率更高;
将查询分解后,执行单个查询可以减少锁的竞争;
在应用层做关联,容易对数据库进行拆分;
可以减少冗余记录的查询;
相当于实现了哈希关联,而不是使用mysql的嵌套查询
(8)展示各个线程的查询状态:
show FULL PROCESSLIST
sleep:线程正在等待客户端发送的新请求
Query:线程正在执行查询或者正在将结果发送给客户端
Locked:线程正在等待表锁
Analyzing and statistics:收集存储引擎的统计信息,并生成查询的执行计划
copying to tmp table:将结果集返回到临时表
sorting result:排序结果
sending data:线程在多个状态间传送数据,在生成结果集、向客户端返回数据。
(9)显示线程的查询的成本
show STATUS like 'Last_query_cost'
(10)查询流程示意图: