Redis是什么,就不多说了,在追求性能的道路上,redis能帮很大的忙,但是很多后端的码农,会对redis有一些误解,甚至滥用,写这文章,希望新手有些帮助,也是对自己的知识巩固,如有错误的地方,请指正,谢谢!
本文参考黄健宏大神的《Redis设计与实现》,并加入自己的理解。那么,废话不多说,开始Redis之旅吧。
用过Redis的小伙伴都知道,Redis有5大类型,string、list、hash、set、sort set
但是,在开始这些类型之前,先了解下支持这5大类型底层的数据结构,这也是本文要讲的重点。
注:文中源码使用redis 3.2 https://github.com/antirez/redis
1. SDS字符串类型(简单动态字符串)
为什么需要sds的这种结构呢,redis是用c语言开发的,但redis并没有直接使用c语言的字符串表示。原因,不够高效(当然对redis而言),不够安全,为什么呢,接下来会一一讲解。
首先看下sds的结构体,redis3.2中,sds的结构体分为6中,sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64,以下只列出sdshdr32的结构,区别只是申明类型uint32_t长度不一样而已,所以不一一列出。
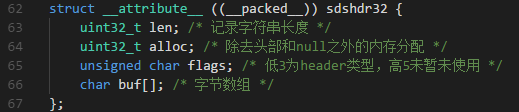
在redis3.2中,sds的结构有所变化,去掉了free,而计算free=alloc - len
- len,表示字符串长度
- alloc,内存分配空间长度,但不包括3字节header和末尾的'�'的空字符
- flags,低3位分别为len,alloc,flags,占用3位,后面5位暂时未使用,便于redis后期的扩展
flags的types

下面是sds结构示例
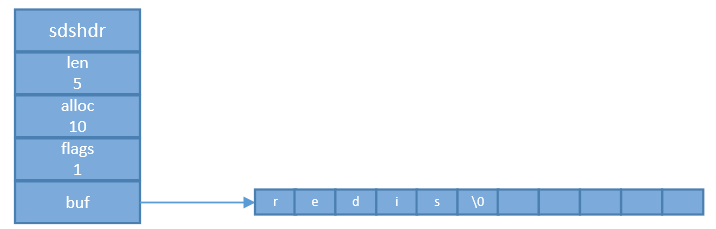
上图sds保存了一个"redis"的字符串,alloc申明了长度为8的内存空间,len为5的字符串。
flags为状态标识,先看下redis源码
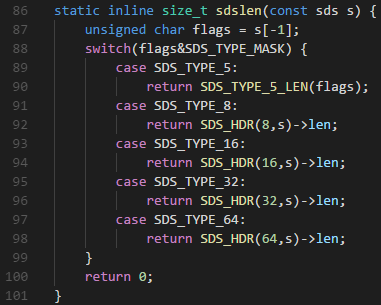
例如:
char s = 'a';
字符a的asc码为97,转换为二进制是01100001,而SDS_TYPE_MASK=7,7的二进制是00000111,01100001&00000111 = 00000001 即1,也就是SDS_TYPE_8这个类型,
为什么要区分那么多类型,redis在内存分配的时候,各个类型采用不同的数据类型,这样可以节省内存占用,更高效使用内存,在后面要讲的数据结构当中,也会体现。
以上只是一些开胃菜,正餐马上开始。
上面说到,c语言字符串对redis来说不够高效不够安全呢,为什么呢?
其一,C语言字符串不记录本身长度,当需要获取长度的时候,遍历整个数组,复杂度为N(O),而SDS,从上图sds结构中可以看出,只要取len就行,复杂度N(1)。
其二,预分配内存,减少修改字符串时带来的可能重新分配内存次数
例如:
set test redis
set test redis cluster
set test redis
这是redis对同一个key进行了两次set操作,并且进行了两次内存分配,第一次初始化分配,第二次,按默认分配策略,内存不够,重新分配内存,第三次不需要进行分配内存
看图说话
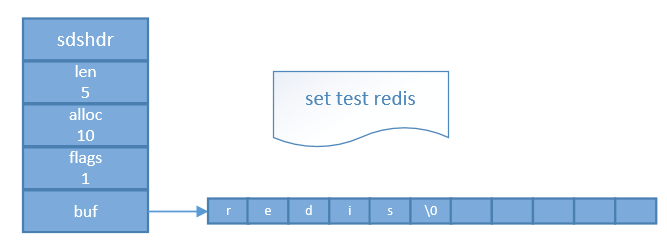 初始化时的value长度(实际空间是11,�占位符占1字节)
初始化时的value长度(实际空间是11,�占位符占1字节)
 这是重新分配内存,字符串总长度为13,但分配了26长度的空间(实际空间是27,�占位符占1字节),预先分配了跟字符串长度
这是重新分配内存,字符串总长度为13,但分配了26长度的空间(实际空间是27,�占位符占1字节),预先分配了跟字符串长度
一样的内存空间,即预分配13字节。
 再一次修改字符串,虽热len长度是5,但alloc长度还是26
再一次修改字符串,虽热len长度是5,但alloc长度还是26
从上面三次set可以看出,只要修改的字符串小于预分配长度,redis都不会重新分配内存,而是直接使用已分配内存,只有当修改字符串大于预分配长度,也就是alloc的长度时,redis才会重新分配内存,并且将预分配内存长度等于修改的字符串长度,这个是redis
默认内存分配策略。好吧,现在小伙伴们可能好奇,默认内存分配策略究竟是怎样的策略呢,下面我也讲讲这个策略,满足下小伙伴们的好奇心。
先看源码
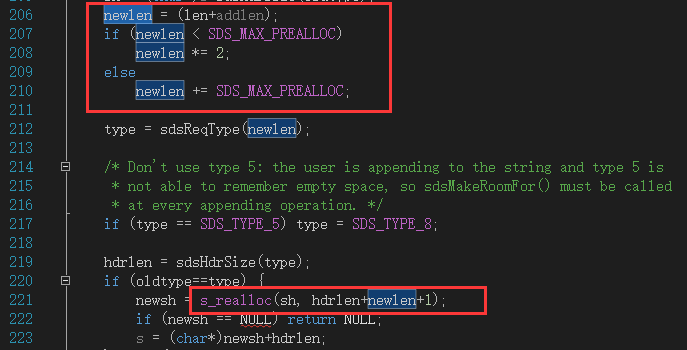

这个是源码中sdsMakeRoomFor() 扩容方法,newlen = 已存在的字符串长度 + 还需要增加的长度,SDS_MAX_PREALLOC=1024*1024=1k,在《Redis设计与实现》中,是1M的空间,不知道是否是我理解问题,不管在2.8还是3.2的源码中,SDS_MAX_PREALLOC的值都是1024*1024,有小伙伴知道请告知,非常感谢!
redis 2.8 https://github.com/antirez/redis/blob/2.8/src/sds.c https://github.com/antirez/redis/blob/2.8/src/sds.h
redis 3.2 https://github.com/antirez/redis/blob/3.2/src/sds.c https://github.com/antirez/redis/blob/3.2/src/sds.h
回到源码中,newlen为实际字符数组长度,如果newlen 小于1k,则分配newlen=newlen*2的空间,否则大于1k,则newlen = newlen+1k的空间。最后,实际分配的内存空间为 sds结构体长度+newlen+1,1为占位符�
以下红灯区:
重要的事情说三遍!
重要的事情说三遍!
重要的事情说三遍!
由于redis的这个预分配机制,导致存对于比较大的字符串,会占用更多的内存,有方法解决,后面的数据结构中会有讲到怎么优化。
其三,杜绝缓冲区溢出
不多说,上图
c语言字符串溢出,例如
有两个字符串s1和s2,在内存中刚好在一起,如下图

有一天,需要对s1字符串进行修改,修改后为redis cluster,可是,有个笨蛋在修改字符串之前,忘记申请了内存,结果就悲剧了,如下:

s2就被覆盖了。但sds却不会这样,上述第二点中,就有说明,sds会预先分配内存,如果不够了会向系统申请内存,再修改字符串。
以上就是关于sds的相关介绍,sds在redis中是最基础的数据结构,也是最重要的,也比较简单,虽然文章有点乱,因为我语文是体育老师教的,不足之处,请多多指教!
接下来有时间,我会陆续跟上其他的数据结构,只有理解这些数据结构,redis的五大类型就迎刃而解,其实重点是对redis有个了解,不至于滥用!