上世纪60年代,Hubel等人通过对猫视觉皮层细胞的研究,提出了感受野这个概念,到80年代,Fukushima在感受野概念的基础之上提出了神经认知机的概念,可以看作是卷积神经网络的第一个实现网络,神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
卷积神经网络是多层感知机(MLP)的变种,由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来,视觉皮层的细胞存在一个复杂的构造,这些细胞对视觉输入空间的子区域非常敏感,称之为感受野。
CNN由纽约大学的Yann Lecun于1998年提出,其本质是一个多层感知机,成功的原因在于其所采用的局部连接和权值共享的方式:
- 一方面减少了权值的数量使得网络易于优化
- 另一方面降低了模型的复杂度,也就是减小了过拟合的风险
该优点在网络的输入是图像时表现的更为明显,使得图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建的过程,在二维图像的处理过程中有很大的优势,如网络能够自行抽取图像的特征包括颜色、纹理、形状及图像的拓扑结构,在处理二维图像的问题上,特别是识别位移、缩放及其他形式扭曲不变性的应用上具有良好的鲁棒性和运算效率等。
用随机的共享的卷积核得到像素点的加权和从而提取到某种特定的特征,然后用反向传播来优化卷积核参数就可以自动的提取特征,是CNN特征提取的基石。
AlexNet (ILSVRC 2012)
CNN的开山之作是LeCun提出的LeNet-5,而其真正的爆发阶段是2012年AlexNet取得ImageNet比赛的分类任务的冠军,并且分类准确率远远超过利用传统方法实现的分类结果,该模型能够取得成功的原因主要有三个:
- 海量的有标记的训练数据,也就是李飞飞团队提供的大规模有标记的数据集ImageNet
- 计算机硬件的支持,尤其是GPU的出现,为复杂的计算提供了强大的支持
- 算法的改进,包括网络结构加深、数据增强(数据扩充)、ReLU、Dropout等;
其实AlexNet的结构很简单,只是LeNet的放大版,输入是一个224x224的图像,经过5个卷积层,3个全连接层(包含一个分类层),达到了最后的标签空间。
AlexNet学习出来的特征是什么样子的?
- 第一层:都是一些填充的块状物和边界等特征
- 中间层:学习一些纹理特征
- 更高层:接近于分类器的层级,可以明显的看到物体的形状特征
- 最后一层:分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
即无论对什么物体,学习过程都是:边缘→部分→整体
Dropout
训练阶段使用了Dropout技巧随机忽略一部分神经元,缓解了神经网络的过拟合现象,和防止对网络参数优化时陷入局部最优的问题,Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
该网络是利用Dropout在训练过程中将输入层和中间层的一些神经元随机置零,使得训练过程收敛的更慢,但得到的网络模型更加具有鲁棒性。
数据增强:防止过拟合
通过图像平移、水平翻转、调整图像灰度等方法扩充样本训练集,扩充样本训练集,使得训练得到的网络对局部平移、旋转、光照变化具有一定的不变性,数据经过扩充以后可以达到减轻过拟合并提升泛化能力。
池化:
AlexNet全部使用最大池化的方式,避免了平均池化所带来的模糊化的效果,并且步长<池化核的大小,这样一来池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
激活函数Relu:
采用非饱和线性单元——ReLU代替传统的经常使用的tanh和sigmoid函数,加速了网络训练的速度,降低了计算的复杂度,对各种干扰更加具有鲁棒性,并且在一定程度上避免了梯度消失问题。
优势:
-
ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作;
-
ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作;
-
ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0;
-
ReLU关闭了左边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。
缺点:
当然,ReLU也是有缺点的,比如左边全部关了很容易导致某些隐藏节点永无翻身之日,所以后来又出现pReLU、random ReLU等改进,而且ReLU会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。
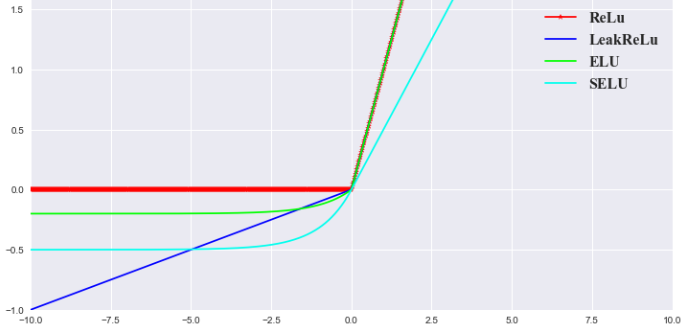
提出了LRN层(Local Response Normalization):
LRN即Local Response Normalization,局部响应归一化处理,实际就是利用临近的数据做归一化,该策略贡献了1.2%的准确率,该技术是深度学习训练时的一种提高准确度的技术方法,LRN一般是在激活、池化后进行的一种处理方法。
LRN是对局部神经元的活动创建竞争机制,使得其中响应较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
为什么输入数据需要归一化(Normalized Data)
归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
有多少层需要训练
整个AlexNet有8个需要训练参数的层,不包括池化层和LRN层,前5层为卷积层,后3层为全连接层,AlexNet的最后一层是由1000类输出的Softmax层用作分类,LRN层出现在第一个和第二个卷积层之后,最大池化层出现在两个LRN之后和最后一个卷积层之后。
ZFNet (ILSVRC 2013)
ZF Net模型更像是AlexNet架构的微调优化版,但还是提出了有关优化性能的一些关键想法。在这篇题为“Visualizing and Understanding Convolutional Neural Networks”的论文中,Zeiler和Fergus从大数据和GPU计算力让人们重拾对CNN的兴趣讲起,讨论了研究人员对模型内在机制知之甚少,一针见血地指出“发展更好的模型实际上是不断试错的过程”。这篇论文的主要贡献在于提出了一个比AlexNet稍微好一些的模型并给出了细节,还提供了一些制作可视化特征图值得借鉴的方法。
该论文是在AlexNet基础上进行了一些细节的改动,网络结构上并没有太大的突破。该论文最大的贡献在于通过使用可视化技术揭示了神经网络各层到底在干什么,起到了什么作用。
从科学的观点出发,如果不知道神经网络为什么取得了如此好的效果,那么只能靠不停的实验来寻找更好的模型。使用一个多层的反卷积网络来可视化训练过程中特征的演化及发现潜在的问题;同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。
VGGNet (ILSVRC 2014)
VGGNet是牛津大学计算机视觉组和Google DeepMind公司的研究员一起研发的的深度卷积神经网络。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3*3的小型卷积核和2*2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降,并取得了ILSVRC 2014比赛分类项目的第2名和定位项目的第1名。
VGGNet论文中全部使用了3*3的卷积核和2*2的池化核,通过不断加深网络结构来提升性能。下图所示为VGGNet各级别的网络结构图,和每一级别的参数量,从11层的网络一直到19层的网络都有详尽的性能测试。很适合做迁移学习,提到了一系列,VGG-16、VGG-19,不同层,参数也不同,最后选择了D的参数,结果最好。
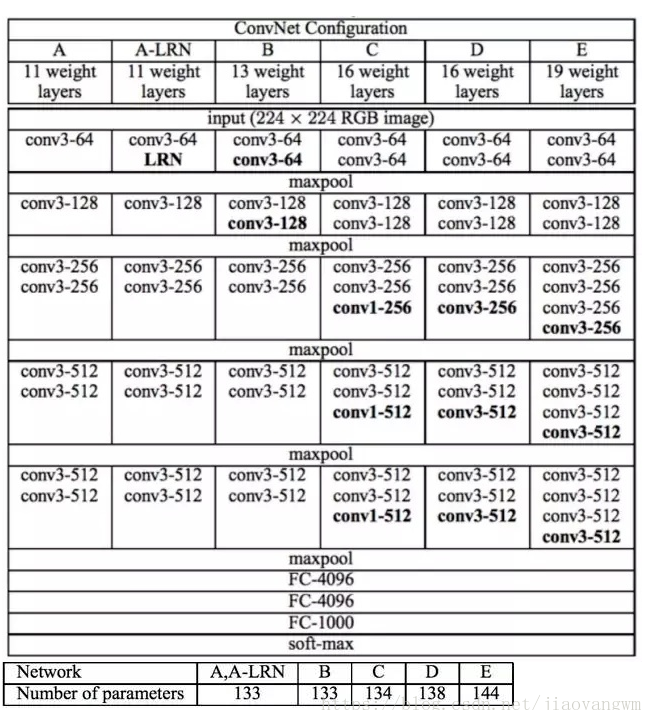
A网络(11层)有8个卷积层和3个全连接层,E网络(19层)有16个卷积层和3个全连接层,卷积层宽度(通道数)从64到512,每经过一次池化操作,扩大一倍。
相比AlexNet的变化:
- LRN层作用不大,这种标准化并不能带来很大的提升,反而会导致更多的内存消耗和计算时间,抛弃
- 网络越深,效果越好
- 卷积核使用更小的卷积核,比如3x3
VGG虽然比AlexNet模型层数多,且每轮训练时间会比AlexNet更长,但是因为更深的网络和更小的卷积核带来的隐式正则化结果,需要的收敛的迭代次数减小了许多。
这里使用3x3的滤波器和AlexNet在第一层使用11x11的滤波器和ZF Net 7x7的滤波器作用完全不同。作者认为两个3x3的卷积层组合可以实现5x5的有效感受野。这就在保持滤波器尺寸较小的同时模拟了大型滤波器,减少了参数。此外,有两个卷积层就能够使用两层ReLU。
VGG Net是最重要的模型之一,因为它再次强调CNN必须够深,视觉数据的层次化表示才有用。深的同时结构简单。
GoogLeNet (ImageNet 2014)
ImageNet 2014比赛分类任务的冠军,将错误率降低到了6.656%,突出的特点是大大增加了卷积神经网络的深度。
GoogLeNet Incepetion V1《Going deeper with convolutions》。之所以名为“GoogLeNet”而非“GoogleNet”,文章说是为了向早期的LeNet致敬。
深度学习以及神经网络快速发展,人们不再只关注更给力的硬件、更大的数据集、更大的模型,而是更在意新的idea、新的算法以及模型的改进。一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合也会大大增加计算量。
文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献1表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。
Inception
2012年AlexNet做出历史突破以来,直到GoogLeNet出来之前,主流的网络结构突破大致是网络更深(层数),网络更宽(神经元数)。所以大家调侃深度学习为“深度调参”,但是纯粹的增大网络的缺点:
- 参数太多,容易过拟合,若训练数据集有限;
- 网络越大计算复杂度越大,难以应用;
- 网络越深,梯度越往后穿越容易消失(梯度弥散),难以优化模型
那么解决上述问题的方法当然就是增加网络深度和宽度的同时减少参数,Inception就是在这样的情况下应运而生。
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构,基本结构如下:
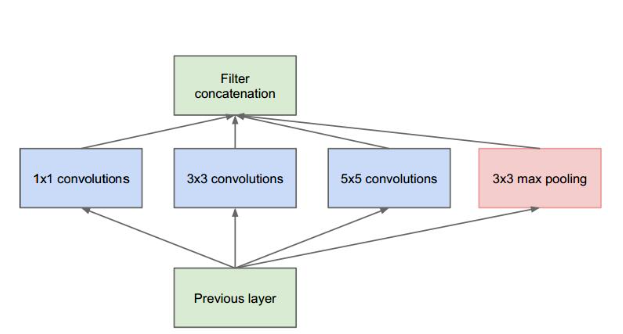
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合
- 之所以卷积核采用1x1,3x3和5x5,主要是为了方便对齐,设定卷积步长stride=1,只要分别设定padding=0,1,2,那么卷积之后便可以得到相同维度的特征,然后将这些特征就可以直接拼接在一起了。
- 文章中说pooling被证明很有效,所以网络结构中也加入了
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也变大了,因此随着层数的增加,3x3和5x5的比例也要增加。
GoogleNet Inception V1
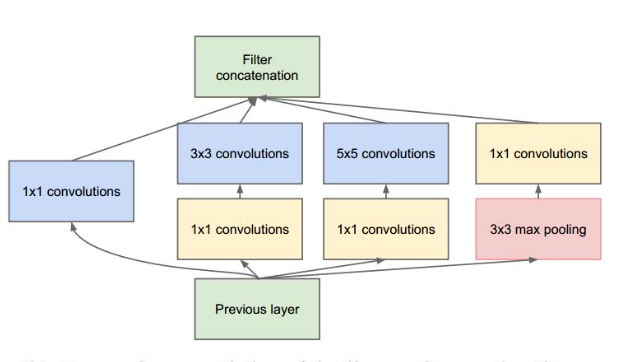
GoogLeNet Incepetion V1比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率,可以说是非常优秀并且非常实用的模型。
Inception V1降低参数量的目的有两点:
- 第一,参数越多模型越庞大,需要供模型学习的数据量就越大,而目前高质量的数据非常昂贵;
- 第二,参数越多,耗费的计算资源也会更大。
Inception V1参数少但效果好的原因除了模型层数更深、表达能力更强外,还有两点:
- 其一,去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。全连接层几乎占据了AlexNet或VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。
- 其二,Inception V1中精心设计的Inception Module提高了参数的利用效率,其结构如上图所示。这一部分也借鉴了Network In Network的思想,形象的解释就是Inception Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。
Inception Module的基本结构:
其中有4个分支:
- 第一个分支对输入进行11的卷积,这其实也是NIN中提出的一个重要结构。11的卷积是一个非常优秀的结构,它可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。
Inception Module的4个分支都用到了1x1的卷积,来进行低成本(计算量比3x3小很多)的跨通道的特征变换 - 第二个分支,先使用了1x1卷积,然后连接3x3卷积,相当于进行了两次特征变换
- 第三个分支,先使用1x1卷积,然后连接5x5卷积
- 第四个分支,3x3最大池化后直接使用1x1卷积
四个分支在最后通过一个聚合操作合并,在输出通道这个维度上聚合。
我们立刻注意到,并不是所有的事情都是按照顺序进行的,这与此前看到的架构不一样。我们有一些网络,能同时并行发生反应,这个盒子被称为 Inception 模型。
GoogleNet Inception V2
V2和V1的最大的不同就是,V2增加了Batch Normalization。[《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》](https://blog.csdn.net/jiaoyangwm/article/details/《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》)
Inception V2学习了VGGNet,用两个3x3的卷积代替5x5的卷积,用以降低参数量并减轻过拟合,还提出了著名的Batch Normalization方法,该方法是一个很有效的正则化的方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅度的提高。
BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化(normalization)处理,使输出规范化到N(0,1)的正态分布,减少了Internal Covariate Shift(内部神经元分布的改变)。
BN的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有1/14,训练时间大大缩短。
而达到之前的准确率后,可以继续训练,并最终取得远超于Inception V1模型的性能——top-5错误率4.8%,已经优于人眼水平。因为BN某种意义上还起到了正则化的作用,所以可以减少或者取消Dropout,简化网络结构。
ResNet(ILSVRC 2015)
ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域都纷纷使用ResNet,Alpha zero也使用了ResNet,所以可见ResNet确实很好用。
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图是带有跳跃结构的:
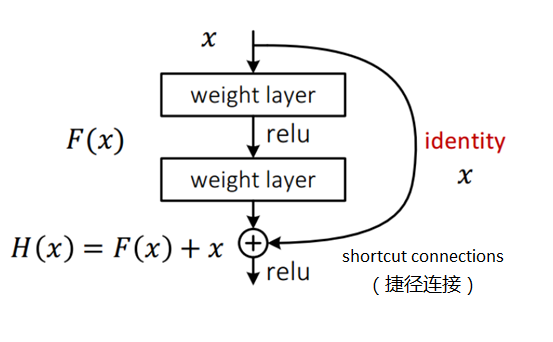
残差网络借鉴了高速网络的跨层连接的思想,但是对其进行了改进,残差项原本是带权值的,但ResNet用恒等映射代替了它。
假设:
神经网络输入:x
期望输出:H(x),即H(x)是期望的复杂映射,如果要学习这样的模型,训练的难度会比较大。
此时,如果已经学习到较为饱和的准确率,或者发现下层的误差变大时,接下来的目标就转化为恒等映射的学习,也就是使得输入x近似于输出H(x),以保持在后面的层次中不会造成精度下降。
上图的残差网络中,通过捷径连接的方式直接将输入x传到输出作为初始结果,输出结果为H(x)=F(x)+x,当F(x)=0时,H(x)=x,也就是恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的残差F(x) := H(x)-x,因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。
学习的目标:目标值H(x)和输入x的差值,即F(x):=H(x)-x,将残差逼近于0,使得随着网络加深,准确率不下降。
R-CNN(2013年)
一些人可能会认为,R-CNN的出现比此前任何关于新的网络架构的论文都有影响力。第一篇关于R-CNN的论文被引用了超过1600次。Ross Girshick 和他在UC Berkeley 的团队在机器视觉上取得了最有影响力的进步。正如他们的文章所写, Fast R-CNN 和 Faster R-CNN能够让模型变得更快,更好地适应现代的物体识别任务。
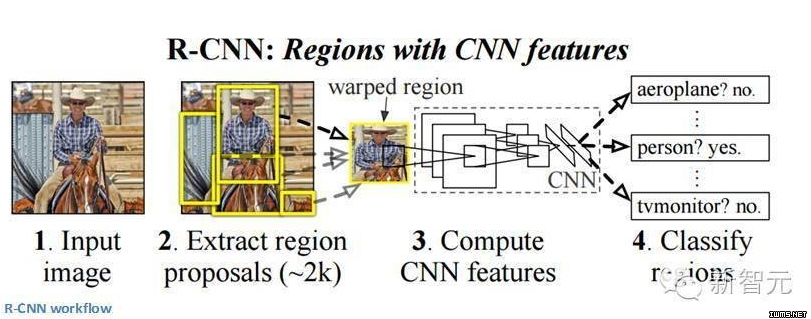
R-CNN的目标是解决物体识别的难题。在获得特定的一张图像后, 我们希望能够绘制图像中所有物体的边缘。这一过程可以分为两个组成部分,一个是区域建议,另一个是分类。
论文的作者强调,任何分类不可知区域的建议方法都应该适用。Selective Search专用于RCNN。Selective Search 的作用是聚合2000个不同的区域,这些区域有最高的可能性会包含一个物体。在我们设计出一系列的区域建议之后,这些建议被汇合到一个图像大小的区域,能被填入到经过训练的CNN(论文中的例子是AlexNet),能为每一个区域提取出一个对应的特征。这个向量随后被用于作为一个线性SVM的输入,SVM经过了每一种类型和输出分类训练。向量还可以被填入到一个有边界的回归区域,获得最精准的一致性。非极值压抑后被用于压制边界区域,这些区域相互之间有很大的重复。
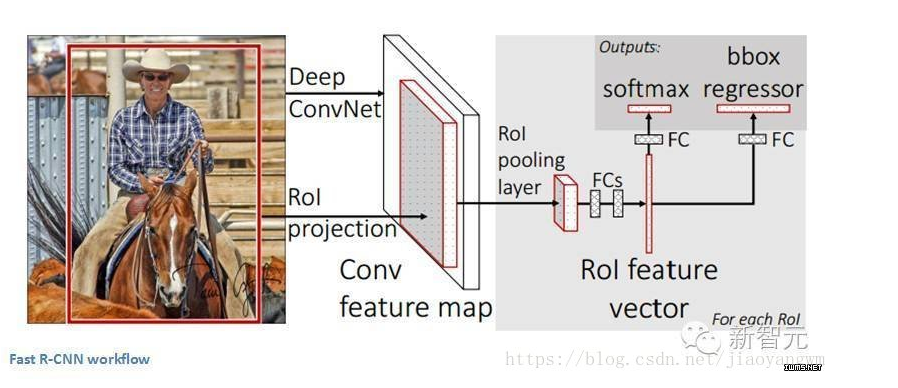
Fast R-CNN(2015年)
原始模型得到了改进,主要有三个原因:训练需要多个步骤,这在计算上成本过高,而且速度很慢。Fast R-CNN通过从根本上在不同的建议中分析卷积层的计算,同时打乱生成区域建议的顺利以及运行CNN,能够快速地解决问题。
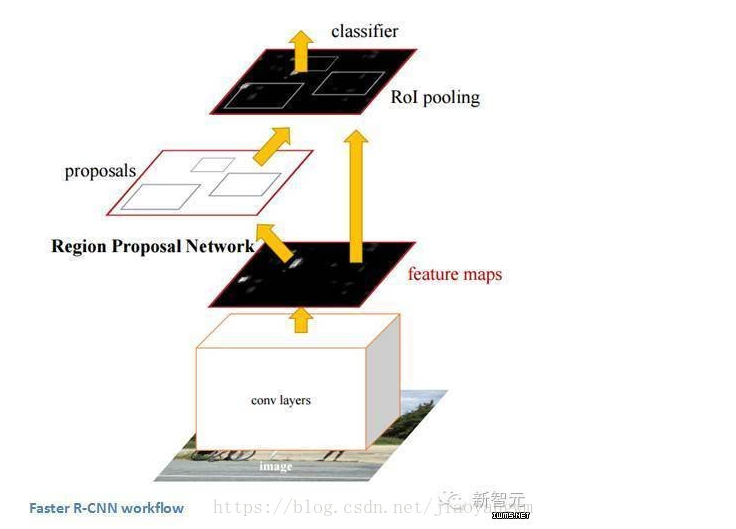
Faster R-CNN(2015年)
Faster R-CNN的工作是克服R-CNN和 Fast R-CNN所展示出来的,在训练管道上的复杂性。作者 在最后一个卷积层上引入了一个区域建议网络(RPN)。这一网络能够只看最后一层的特征就产出区域建议。从这一层面上来说,相同的R-CNN管道可用。
2017 年 7 月 26 日,将标志着一个时代的终结。那一天,与计算机视觉顶会 CVPR 2017 同期举行的 Workshop——“超越 ILSVRC”(Beyond ImageNet Large Scale Visual Recogition Challenge),将宣布计算机视觉乃至整个人工智能发展史上的里程碑——IamgeNet 大规模视觉识别挑战赛将于 2017 年正式结束,此后将专注于目前尚未解决的问题及以后发展方向。
参考资料