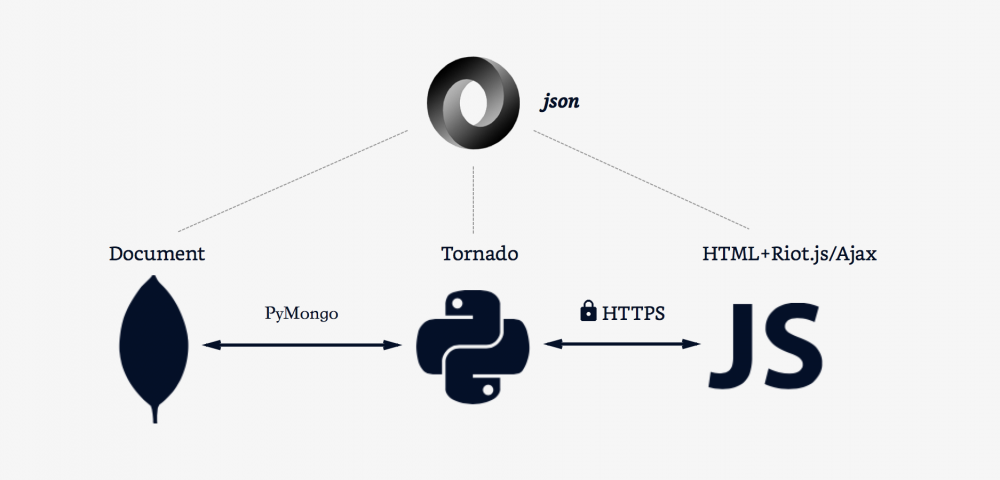
本文主要总结网站编写以来在传递 JSON 数据方面遇到的一些问题以及目前采用的解决方案。网站数据库采用 MongoDB,后端是 Python,前端采用“半分离”形式的 Riot.js,所谓半分离,是说第一页数据是通过服务器端的模板引擎直接渲染到 HTML 中,从而避免首页两次加载的问题,而其它动态内容则采用 Ajax 加载。整个流程中数据都是通过 JSON 格式传递的,但是在不同的环节中需要采用不同的方式并遇到一些不同的问题,本文主要做记录、总结。
1. What is JSON?
JSON(JavaScript Object Notation) 是一种由道格拉斯·克罗克福特构想设计、轻量级的数据交换语言,它的前辈 XML 可能更早被人们所熟知。当然 JSON 并不是为了取代 XML 而存在的,只是相比于 XML 它更小巧、更适合在网页开发中用作数据传递(JSON 之于 JavaScript 就像 XML 之于 Lisp)。从名字上可以看出,JSON 的格式符合 JavaScript 语言中“对象”的语法格式,除了 JavaScript 之外,很多其他语言中也具有类似的类型,例如 Python 中的字典(dict),除了编程语言之外,一些基于文档存储的 NoSQL 非关系型数据库也选择 JSON 作为其数据存储格式,例如 MongoDB。
总的来说,JSON 定义一种标记格式,可以非常方便地在编程语言中的变量数据与字符串文本数据之间相互转换。JSON 描述的数据结构包括以下这几种形式:
- 对象:
{key: value} - 列表:
[obj, obj,...] - 字符串:
"string" - 数字:数字
- 布尔值:
true/false
了解了 JSON 的基本概念之后,下面分别针对上图中的几个数据交互环节进行总结。
2. Python <=> MongoDB
Python 与 MongoDB 之间的交互主要由现有的驱动库提供支持,包括 PyMongo、Motor 等,而这些驱动所提供的接口都是非常友好的,我们不需要了解任何底层的实现,只要对 Python 原生的字典类型进行操作即可:
import motor
client = motor.motor_tornado.MotorClient()
db = client['test']
user_col = db['user']
user_col.insert(dict(
name = 'Yu',
is_admin = True,
))
唯一需要注意的是 MongoDB 中的索引项 _id 是通过 ObjectId("572df0b78a83851d5f24e2c1")存储的,而对应的 Python 对象为 bson.objectid.ObjectId,因此在查询时需要以此对象的实例进行:
from bson.objectid import ObjectId
user = db.user.find_one(dict(
_id = ObjectId("572df0b78a83851d5f24e2c1")
))
3. Python <=> Ajax
前端与后端之间的数据交流比较常用的是通过 Ajax 完成,这时遇到了第一个不大不小的坑。在之前的一篇文章中,我总结了一次 Python 编码的坑,我们知道 HTTP 传递过程中肯定不存在 JSON/XML ,一切都是二进制数据,但是我们可以选择让前端用什么样的方式解读这些数据,即通过设定 Header 中的 Content-Type,一般传递 JSON 数据时将其设定为 Content-Type: application/json,在 Tornado 最新版本中,只需要直接写入字典类型即可:
# Handler
async def post(self):
user = await self.db.user.find_one({})
self.write(user)
于是迎来了第一个错误:TypeError: ObjectId('572df0b58a83851d5f24e2b1') is not JSON serializable。追溯原因,虽然 Tornado 帮我们简化了操作,但在像 HTTP 中写入字典类型时仍然需要经历一次 json.dumps(user) 操作,而对于 json.dumps 来说,ObjectId 类型是非法的。于是我选择了最直观的解决方案:
import json
from bson.objectid import ObjectId
class JSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, ObjectId):
return str(obj)
return super().default(self, obj)
# Handler
async def post(self):
user = await self.db.user.find_one({})
self.write(JSONEncoder.encode(user))
这次不会再出错了,我们自己的 JSONEncoder 可以应对 ObjectId 了,但另一个问题也出现了:
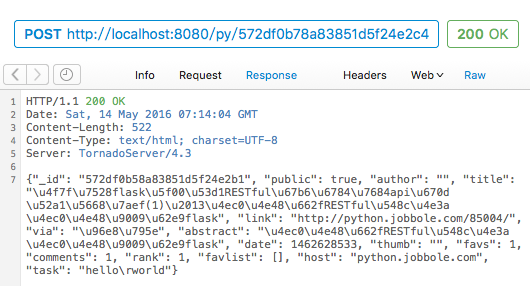
JSONEncoder.encode 之后字典类型被转换成字符串,写入 HTTP 之后 Content-Type 变为text/html,这时前端将认为接收的数据为字符串而不是可用的 JavaScript Object。当然还有进一步的弥补方案,那就是前端再进行一次转换:
$.post(API, {}, function(res){
data = JSON.parse(res);
console.log(data._id);
})
问题暂时解决了,在整个过程中 JSON 的变换是这样的:
Python ==> json.dumps ==> HTTP ==> JavaScript ==> JSON.parse
dict ==> str ==> binary ==> string ==> Object
结果第二个问题来了,当数据中存在一些特殊字符时,JSON.parse 将出现错误:
JSON.parse("{'abs': '
'}");
// VM536:1 Uncaught SyntaxError: Unexpected token ' in JSON at position 1(…)
这就是在遇到问题是只着眼解决眼前错误导致后续一连串改动所带来的弊病。我们沿着上面 JSON 变换的链条向上追溯,看有没有更好的解决方案。很简单,遵循传统规则,出现特例的时候,改变自身适应规则,而不是改变规则:
# Handler
async def post(self):
user = await self.db.user.find_one({})
user['_id'] = str(user['_id'])
self.write(user)
当然,如果是多条数据的列表形式,还需要进一步改造:
# DB
async def get_top_users(self, n = 20):
users = []
async for user in self.db.user.find({}).sort('rank', -1).limit(n):
user['_id'] = str(user['_id'])
users.append(user)
return users
4. Python <=> HTML+Riot.js
如果上面的问题可以通过遵守规则来解决,那么接下来这个问题就是一个挑战规则的故事。除去 Ajax 动态加载部分,网页上的其他数据是通过后端模板引擎渲染得来的,也就是说是 Hard-coding 为 HTML 的。在浏览器加载并解析这个 HTML 文件之前它们只是纯文本文件,而我们需要的是直接将数据塞仅 <script> 标签在浏览器运行 JavaScript 时直接可用。严格意义上来说这并不算是 JSON 的应用,而是 Python 的 dict 与 JavaScript 的 Object 之间的直接转换,常规的方法应该这样写:
# Handler
async def get(self):
users = self.db.get_top_users()
render_data = dict(
users = users
)
self.render('users.html', **render_data)
<!-- HTML + Riot.js -->
<app></app>
<script>
riot.mount('app', {
users: [
{% for user in users %}
{ name: "{{ user['name']}}", is_admin: "{{ user['is_admin']}}" },
{% end %}
],
})
</script>
这样写是对的,但是要解决上面提到的 ObjectId() 问题还是需要一些额外的处理(尤其是引号问题)。另外为了解决 ObjectId 的问题我还尝试了一种比较蠢的方法(在上面的 JSON.parse 遇到错误之前):
# Handler
async def get(self):
users = self.db.get_top_users()
render_data = dict(
users = JSONEncoder.encode(users)
)
self.render('users.html', **render_data)
<!-- HTML + Riot.js -->
<app></app>
<script>
riot.mount('app', {
users: JSON.parse('{{ users }}'),
})
</script>
其实跟第 3 小节的问题一样,模板引擎渲染过程与 HTTP 传输过程是类似的,不同的是在模板中字符串变量就是纯粹的值(没有引号),因此完全可以用生成 JavaScript 脚本文件的形式渲染变量而无需顾虑特殊字符(下面的 {% raw ... %} 是 Tornado 模板用于防止特殊符号被 HTML 编码的语法):
<!-- HTML + Riot.js -->
<app></app>
<script>
riot.mount('app', {
users: {% raw users %}),
})
</script>
总结
JSON 是很好用的数据格式,但是在不同语言环境之间切换还是有很多细节问题需要注意。此外,遵循传统规则,出现特例的时候,改变自身适应规则,而不是试图改变规则,这一条不一定适应所有问题,但对于那些已被公认的规则,请勿轻易挑战。