- 通常机器学习,目的是,找到一个函数,针对任何输入:语音,图片,文字,都能够自动输出正确的结果。

- 而我们可以弄一个函数集合,这个集合针对同一个猫的图片的输入,可能有多种输出,比如猫,狗,猴子等,而我们通过提供大量的training data给这个函数集合,对集合里的各种函数组合的输出进行比对,最后选出一个能输出最佳结果(结果是猫)的组合,那么因为这个组合已经很能够很准确的识别猫,所以这个组合就能用来检测图片里是否是猫。

- 具体来说,下面第一张图,某一个点为一个函数,而整个网络机构为函数集合,一个集合里存在非常多的可能,任何函数都可以相互组合进行计算。
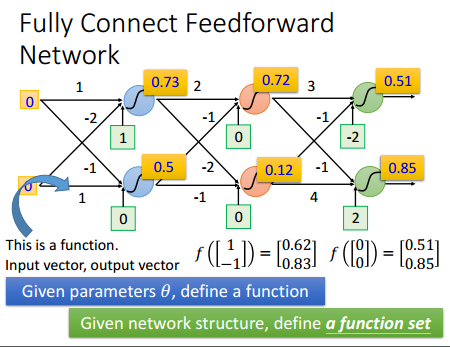
下面第2张图的第一列为输入,第二列为第1层,每个输入都作为layer1的输入,输出后又分别作为layer2的输入,这样用穷举法,遍历针对每一个输入的每一种计算可能而那么多layer就定义了一个函数集。

- 上面提到的大量的training data,是训练的素材,而如何判断针对这些输入的输出是否正确呢?我理解就是根据label来的


-. 函数集里的每种函数组合,针对每一个training data产生的结果与 target之间的差称为LOSS,针对所有training data产生的LOSS之和,就是考察某一个函数组合的goodness的数据指标。目标当然是LOSS越小越好,而关键就是找到那个network parameters(即下图中的b和w,因为这个函数里就这些参数是变化的)让LOSS最小。所以这个问题,最终成为,针对Loss=f(training data, w,b, 函数组合),找到合适的network parameters让LOSS最小的问题,通过对这个函数求导就能得到结论:
求导为负数,说明L在减小,就增加w,增加L减小的趋势。
求导为正,说明L在增加,则减小W,向L增加的方向走。
反复操作,直到求导为0
而每次计算求导时,w前进/后退多少,称之为learning rate



找到合适的network parameters,就找到了针对这些training data的正确的函数组合了!这样学习模型就建立成功,可以实现正确的识别同类型的输入了!