1,前言
语义相似度计算是信息检索,自动问答中常用的技术。语义相似度计算通常可以分为表示型和交互型两种类型,表示型模型如DSSM,孪生网络,这类模型可以离线计算doc的编码,在线上运行时只需要编码query,效率很高,但是精度不如交互型模型,而交互型模型需要在线编码query和doc,当需要比较的doc很多时,效率是非常低的。bert中的句子对任务其实就是一种交互式语义相似度计算模型,句子对任务需要拼接query和doc后一起编码,实际的应用中非常耗时,但仅仅使用bert来分别表示query和doc,然后通过点积或余弦相似度计算query和doc的分数的方法精度又不够,本文带来的几篇论文就是结果表征式的效率和交互式的精度来处理语义相似度计算的问题,可以看作是一种弱交互式的模型。
2,相关工作
论文一:DC-BERT: DECOUPLING QUESTION AND DOCUMENT FOR EFFICIENT CONTEXTUAL ENCODING
模型结构:本文提出了一种弱交互的方法 — DC-BERT来提升模型的效率。整个模型分为三层,Dual-BERT component;Transformer component;Classifier component。具体结构如下图

Dual-BERT component
Dual-BERT就是使用两个不同的bert分别对query和doc编码,可以采用预训练好的bert中前面的层(因为bert中前面的层可以提取文本中的词性,语法结构信息。而后面的层可以提取上下文交互的语义信息。),两个不同的bert不共享参数,可以在训练时被fine-tuning。
Transformer component
Transformer层用来对query和doc交互编码,不过为了效率一般层数都比较少(取一层都有不错的效果),transformer层也不是从零开始训练的,而是取bert中后面的层的参数初始化,另外为了引入更多的全局信息,在transformer层引入全局位置向量,也就是query和doc拼接后的位置向量,以及句子编码用来区分query和doc。
Classifier component
分类层将query和doc中的[CLS]位置上的向量拼接,然后经二分类层。优化函数采用二元交叉熵。
从模型结构看,整体思想还是比较简单的,接下来看下实验效果,作者和bert,int8-bert,distill-bert做了对比,对比结果如下
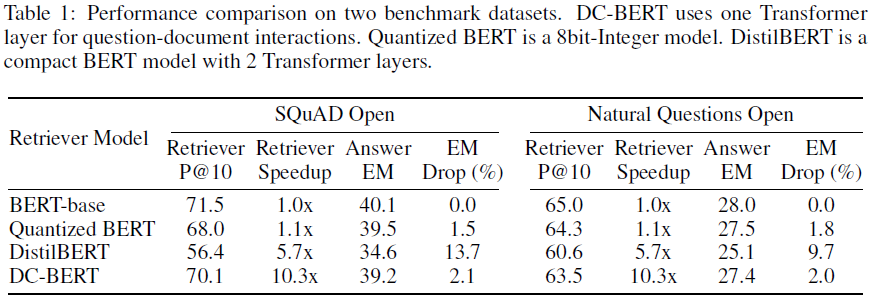
在SQuAD Open和Natural Questions Open的数据集上表明DC-BERT的推断速度提升明显,是bert-base的10倍,且同时能保持较好的精度。整体上来看是要优于distillBERT和int8-bert。但从结构上来看DC-BERT的参数量应该不少,毕竟使用了两个bert,在服务端模型大小倒不是问题,但是要在手机端上部署就成问题了,即使只使用了bert中的几层也会很大,所以这种方法基本只能在服务端上使用。
论文二:Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring
本篇论文同上面的一样,在最后时刻做交互,但是方法还是有蛮大差异。首先作者认为表征式的方法之所以不好是因为将query和doc映射到了一个固定的向量,而这个向量涵盖的信息可能只是部分重要的特征,导致在和doc计算分数时没那么准确,所以作者在这里的做法就是更加充分的提取query的特征信息,具体怎么做的呢?我们来看下面这张图:

上面的图a,图b分别是表征式和交互式语义相似度计算的范式,作者分别将其命名为bi-encoder,cross-encoder。图c是作者提出的poly-encoder的方法,为了充分提取query的信息,作者对一个query计算出m个encoder的向量,在transformer层的最后输出位置再接一层用来将最后的一层的输出做m次attention池化得到m个encoder 向量。具体表达式如下:
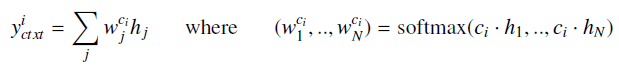
$y_{ctxt}^i$表示第i个encoder 向量,$c_i$是随机初始化出来,后来随着训练的过程被训练,所以这一步的操作和bilstm-attention中的attention一样,只不过执行了m次,这样就得到m个encoder 向量,那么又该怎么和doc交互呢?表达式如下:
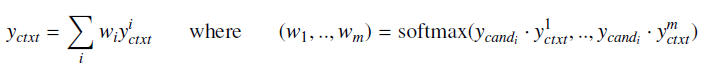
交互就是把doc作为attention中的q,然后对m个encoder 做attention,得到一个固定的向量$y_{ctxt}$。然后计算分数。
模型的表现结果还是可以的,而且速度和精度都收query的encoder向量的数量的影响,这也说明单个encoder向量的信息确实有限
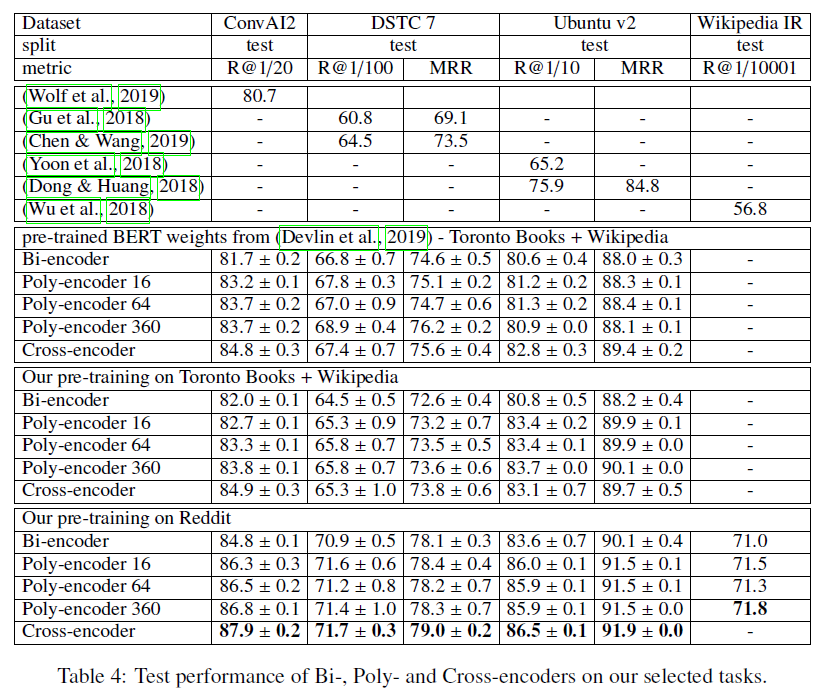
如上,当encoder 向量的数据为360时,模型的结果相比交互式模型的差距是非常小的,然后看推断速度:
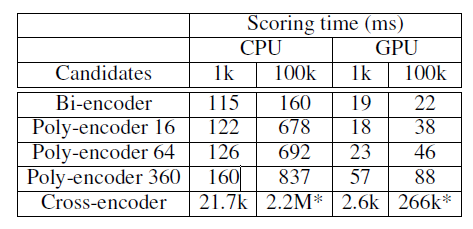
query的encoder向量的数量影响其实也没那么大,总的来说还是不错的工作。
论文三:ColBERT: Eicient and Eective Passage Search via Contextualized Late Interaction over BERT
本篇论文提出了一种细粒度的基于token级的交互模式,被称为MaxSim。在这里query和doc是共享同一个transformer encoder的,在最后再做交互取代直接计算dot求解query和doc的分数,模型结构如下:
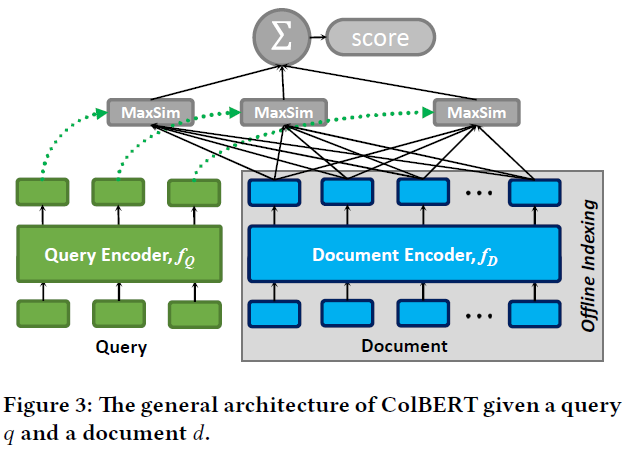
因为query和doc共享同一个transformer encoder,所以为了做区分,分别在query和doc引入一个用于识别的token [Q] 和 [D]。这个token放在[CLS]后面。另外就是query会固定要某一个固定长度,而doc不做任何截断和补全的,在编码完之后会对向量做归一化(这一步主要是为了后面计算MaxSim的方便),并且在计算MaxSim时去掉了doc中的一些标点符号,具体的表达式如下:
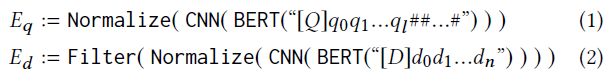
计算query和doc的方式如下:
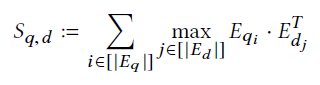
query中的每个token和doc中的每个token求点积,因为前面做过一次归一化,所以这里的结果就是余弦相似度值,然后取query中的token和doc中的token的余弦相似度的最大值之和,在这里这一步也称为MaxSim。在这里doc的向量时可以离线计算好的,且MaxSim时没有需要训练的参数,所以可以直接接如faiss这类的框架进行排序,类似于将召回和排序结合在一起了。
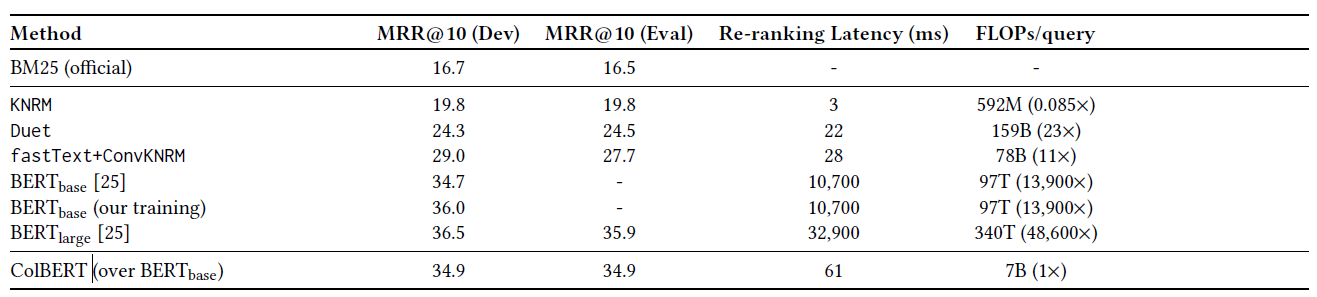
整体来看效果不错,而且速度也非常快,具体使用细节见论文。
参考文献:
DC-BERT: DECOUPLING QUESTION AND DOCUMENT FOR EFFICIENT CONTEXTUAL ENCODING
Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring
ColBERT: Eicient and Eective Passage Search via Contextualized Late Interaction over BERT