本篇带来XL-Net和它的基础结构Transformer-XL。在讲解XL-Net之前需要先了解Transformer-XL,Transformer-XL不属于预训练模型范畴,而是Transformer的扩展版,旨在解决Transformer的捕获长距离依赖信息的上限问题。接下来我们详细的介绍Transformer-XL和XL-Net。
一,Transformer-XL
论文:TRANSFORMER-XL: LANGUAGE MODELING WITH LONGER-TERM DEPENDENCY
GitHub:https://github.com/kimiyoung/transformer-xl
Transformer模型在输入时采用的是固定长度序列输入,且Transformer模型的时间复杂度和序列长度的平方成正比,因此一般序列长度都限制在最大512,因为太大的长度,模型训练的时间消耗太大。此外Transformer模型又不像RNN这种结构,可以将最后时间输出的隐层向量作为整个序列的表示,然后作为下一序列的初始化输入。所以用Transformer训练语言模型时,不同的序列之间是没有联系的,因此这样的Transformer在长距离依赖的捕获能力是不够的,此外在处理长文本的时候,若是将文本分为多个固定长度的片段,对于连续的文本,这无异于将文本的整体性破坏了导致了文本的碎片化,这也是Transformer-XL被提出的原因。
Transformer-XL做了两个改变,一是引入了循环机制来提升模型的长距离依赖捕获能力,二是引入上述循环机制之后,之前的绝对位置就不work了,需要新的方法引入位置信息,因此有提出了相对位置的做法。我们来详细得看看这两个改变是怎么实现的。
1)SEGMENT-LEVEL RECURRENCE WITH STATE REUSE
Transformer模型在训练和评估时的图示化表示如下:

可以看到在训练阶段,序列之间是相互孤立的,在评估阶段,在预测下一个词的时候也只能利用前面的固定为n个词的序列。这样在训练时模型捕获信息的长度不够,且在评估时利用的信息也不够。再来看看Transformer-XL。
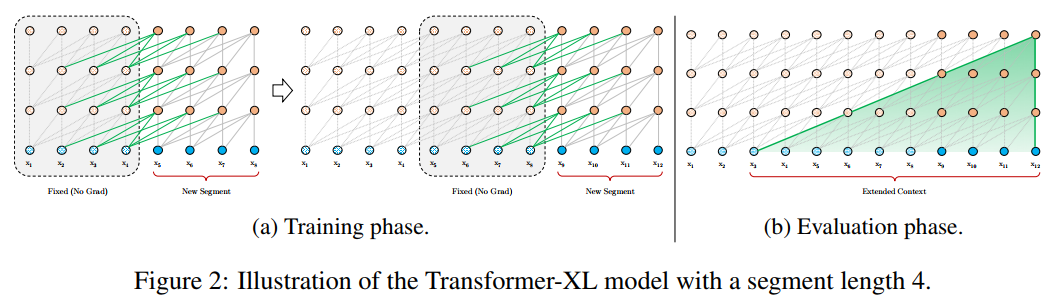
Transformer-XL在训练的时候将上一片段的结果引入到下一片段中,在评估时同样,因此能捕获的长距离信息较Transformer有很大的提升。从公式上来看就更加直观了
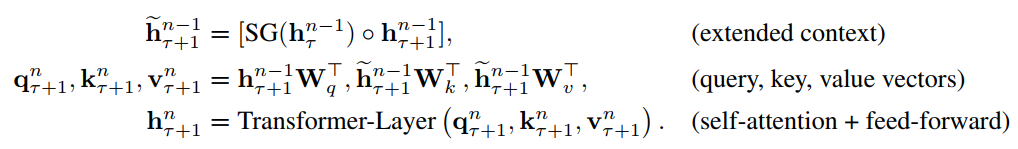
在上面式子中$ au$表示上一片段,$ au + 1$表示下一片段。将上一片段的输出缓存起来,然后直接和下一片段的隐层拼接在一起,在这里$SG()$的含义是stop-gradient。另外这个引入了上一片段的隐层表示只会用在key和value上,对于query还是保持原来的样子。这样做也好理解,query只是表示查询的词,而key,value表示的是表示这个查询的词的相关信息,我们要改变的是只是信息,因此只要在key,value中引入上一片段的信息就可以了,剩下的就和Transformer一致。
2)RELATIVE POSITIONAL ENCODINGS
引入了上述机制之后,绝对位置就用不了了,如下面所示:
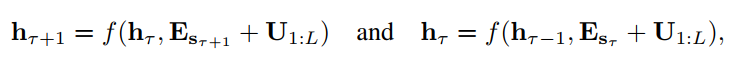
用绝对位置表示时,对于上一片段和当前片段的位置向量是一致的,这样看显然是不合理的,所以作者又引入了相对位置的概念。具体做法如下:
Transformer中的attention权重计算公式如下:
${(E_{x_i} + U_i)}^T W_q^T W_k (E_{x_j} + U_j)$
将其展开可以分解成下面四个部分:

这四个部分可以理解为:
a)基于内容的“寻址”,即没有添加位置向量,词对词的分数。
b)基于内容的位置偏置,相当于当前内容的位置偏差。
c)全局的内容偏置,用于衡量key的重要性。
d)全局的位置偏置,根据key和query调整位置的重要性。
拆分成这四部分之后,我们就可以对其进行改写,引入相对位置向量。具体做法如下:
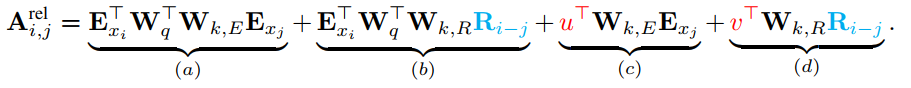
a)部分基本不变,只是对于key的位置向量的权重矩阵和词向量的权重矩阵不再共享;b)部分引入了相对位置向量$R_{i-j}$,是一个不可以学习的预先给定好的正弦编码矩阵;c)对于query的位置向量采用可以学习的初始化向量来表示,$u^T$表示对key中词的位置向量,d)同上,$v^T$表示对key中位置的位置向量。
将上面的式子合并后,可以得到:
${(W_q E_{x_i} + u)}^T W_{k, E} E_{x_j} + {(W_q E_{x_i} + v)}^T W_{k, R} R_{i-j}$
上面整个即使Transformer-XL的两个改变。
二,XL-Net
论文:XLNet: Generalized Autoregressive Pretraining for Language Understanding
GitHub:https://github.com/zihangdai/xlnet
XL-Net的提出是非常具有意义的,展示了自回归模型也是可以实现双向的,并且解决了bert中一些已有的缺陷。在XL-Net论文中提出bert主要有两个缺陷:
1)bert中的mask后的词相互独立,因此在预测mask的词的时候,忽略了mask词与词之间的关系,举个简单的例子,New York这两个词同时被mask,此时你在预测New的时候是无法使用York的信息的,因为它被mask了,但实际上你要准确的预测New,York提供的信息是非常大的。
2)训练时和预测时存在不一致,训练模型时会对词做mask,但是在预测的时候是没有mask的,或者说在下游任务上也是没有mask的,这也就导致了在训练时模型看到的和预测时模型看到的信息是有差异的。
上面两个问题对于bert这种去噪自编码模型(对输入进行破坏,然后通过自编码模型来重构未破坏的输入)来说,是无法避免的。因此XL-Net抛弃了这种自编码模型的思想,重新使用自回归(语言模型,如ELMO,GPT都是自回归模型)的模式,但是传统的自回归模式是无法使用上下文的信息的,因此在使用自回归语言模型的同时,如何引入双向的上下文信息是本文主要的贡献。作者采用了Permutation Language Modeling 的方法来引入双向上下文信息。
Objective: Permutation Language Modeling
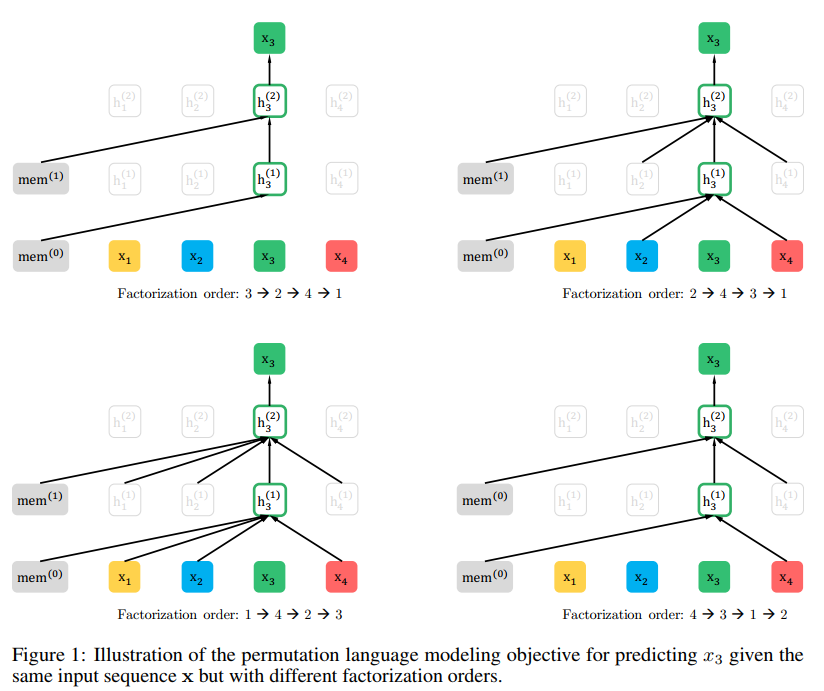
具体的做法如上图所示,保持序列的输入顺序不变,但是维护一个Factorization order的随机排序的位置表,如上面所示,保持x1,x2,x3,x4的原始输入不表,然后随机排序给出4个Factorization order,当你在预测x3的时候,通过mask的方式,使得只能看大Factorization order中3的前面的位置词,也就是第一个序列中3的前面什么都没有,第二条序列中3的前面有2和4,因此通过mask的方式使得在预测x3时只能看到x2,x4,同样在第三个序列中可以看到x1,x2,x4。在第四条序列中可以看到x4。现在假定我们采样的序列足够多,从期望的角度上来看,这种方式可以保证在预测x3时,x1,x2,x4被看到的次数基本一致。作者也就是通过这种方式引入了双向信息。
Architecture: Two-Stream Self-Attention for Target-Aware Representations
但是上面的方式在实现上有一些问题,例如给定一个a1,b2,c3,d4的序列,此时采样两条序列为:a1,c3,b2,d4和a1,c3,d4,b2。在预测序列1中的b2和预测序列2中的d4时,看到的都是a1和c3,因此预测概率都是一样的,但是直观上来说这个概率应该是不一样的,毕竟目标不一样,为了解决这样的问题,作者在预测当前词的时候引入了当前词的位置信息,例如在预测b2时除了用到a1和c3还会把它的位置信息一起传进来,但是你在预测下一个词的时候,你不仅要用到上一个词的位置信息,还需要将上一个词的词信息也加进来,这句话看上去有点难理解,我们来看看公式,就很明确了:
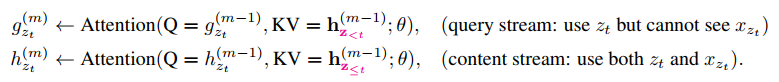
在这里$g_{z_t}^{(m)}$表示的是引入了之前的时刻的所有信息和当前时刻的位置信息的隐层向量,就如前面的a1,c3和位置2的信息,用来预测b2。但是这个公式中含有一个$h_{z_{<t}}^{(m-1)}$,这是之前所有时刻的隐藏信息,为了保证在$g_{z_{t+1}}^{(m)}$时能使用$h_{z_{<t+1}}^{(m-1)}$,我们要另外去计算这样一个h,因为这个h是对t时刻及之前所有的信息编码得到的,也就是说这里的h是包括t时刻的位置和词的信息,如在上面序列1中,此时你要预测d4,你是需要对a1,c3,b2编码的,但我们在计算$g_{z_t}^{(m)}$没用到b2的词信息。也就是这样的不一致,作者提出了双流attention机制,具体的图示如下:

如上图最右边的图中所示,实现起来就是mask不太一样,一上面的为例因为序列为3,2,4,1。因此在计算词1时,g(query stream)只能看到3,2,4;而h(content stream)能看到3,2,4,1。在计算词2时,g能看到3;h能看到2,3。
另外g的提出主要是为了训练预训练模型,因为你在预测当前词时,是要mask当前词(这个mask是不可避免的,这是语言模型的特性,利用上文预测当前词),但是在下游任务的时候,我们是不会mask任何词的,因此在下游任务时我们只需要使用content stream的值就行了。
总的来说,XL-Net这种方法很优雅的引入双向上下文信息,但是在实现上计算量很大,因为你要计算很多排序的序列才能使得期望上每个词出现的次数基本一致,为了降低计算量,作者在这里只对排序后的句子的后半段的词做预测,因为后半段的词的前面的词比较多,这样看到的词会多一些,可能很快的达到期望一致。
Incorporating Ideas from Transformer-XL
和上面讲到的Transformer-XL基本一致,可以说是直接引入了Transformer-XL的架构。
Modeling Multiple Segments
因为很多的下游任务是两个片段,甚至多个片段输入,因此XL-Net也引入了片段对的输入方式。不过输入的方式和bert稍有不同,其输入顺序为:[A, SEP, B, SEP, CLS],在这里将CLS放在最后,主要是因为XL-Net是从前往后预测,因此CLS放在最后可以看到所有的词,所涵盖的信息就更多充分。另外就是这里的segment编码也是采用的相对位置编码,理解起来很简单,不再赘述。
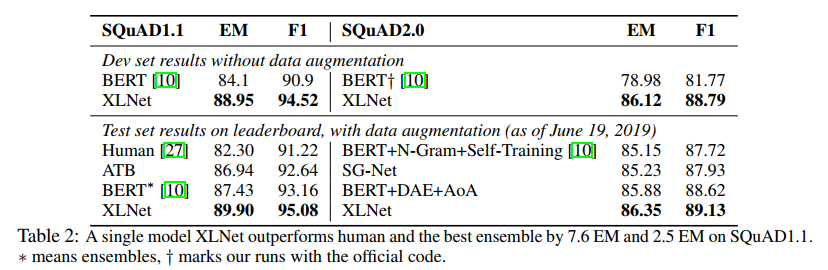
XL-Net在很多数据集上都取得了当前最佳的性能,如在SQuAD数据集上
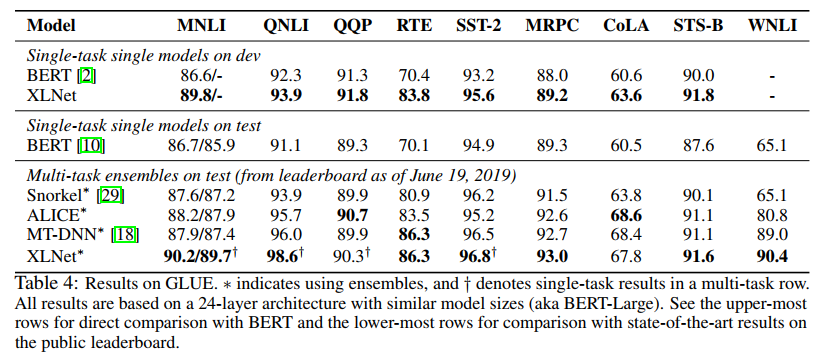
在GLUE数据集上:
XL-Net还是非常具有创新价值的,较之前在bert的基础上做一些调整的模型来说,它的意义是不一样的。