我们下载下来的预训练的bert模型的大小大概是400M左右,但是我们自己预训练的bert模型,或者是我们在开源的bert模型上fine-tuning之后的模型的大小大约是1.1G,我们来看看到底是什么原因造成的,首先我们可以通过下一段代码来输出我们训练好的模型的参数变量。
下面这段代码可以输出我们下载的官方预训练模型的参数变量
import tensorflow as tf from tensorflow.python import pywrap_tensorflow model_reader = pywrap_tensorflow.NewCheckpointReader("chinese_L-12_H-768_A-12/bert_model.ckpt") var_dict = model_reader.get_variable_to_shape_map() for key in var_dict: print(key)
我们截取了部分参数如下:

现在换成我们自己预训练的bert模型,代码和上面一样
from tensorflow.python import pywrap_tensorflow model_reader = pywrap_tensorflow.NewCheckpointReader("H_12_768_L12_vocab5/model.ckpt-1500000") var_dict = model_reader.get_variable_to_shape_map() for key in var_dict: print(key)
我们同样截取部分参数
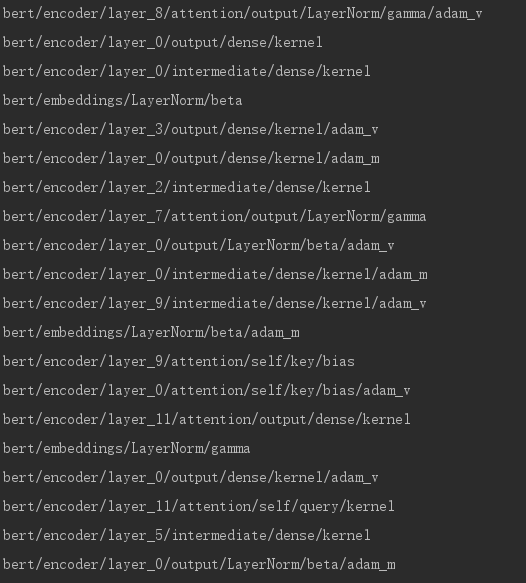
我们可以看到这里混入了不少带有"adam"的变量,我们来看adam优化算法,在计算一阶矩和二阶矩时,我们是要保存之前时刻的滑动平均值的,而每个需要通过梯度更新的参数,都要维护这样一个一阶矩和二阶矩之前时刻的滑动平均值,也就是对应上面的 "adam_m" (一阶矩) 和 “adam_v” (二阶矩),因此导致我们自己预训练的模型的大小大约是官方预训练模型的大小的3倍。而这些参数变量只有训练模型的时候有用,在之后预测的时候以及fine-tuning阶段都是没有用的(fine-tuning时我们只是用到了之前预训练好的模型的参数来作为初始化值,并不会用到优化算法中的中间值),因此我们可以在训练完或者fine-tuning完bert模型之后,在保存模型时将这些参数去掉,也可以在保存了完整的参数之后,再加载去掉这些参数,然后重新保存,这样就不需要改动bert的源码,具体的实现如下:
import re import tensorflow as tf from tensorflow.contrib.slim import get_variables_to_restore # 将bert中和adam相关的参数的值去掉,较小模型的内存 graph = tf.Graph() with graph.as_default(): sess = tf.Session() checkpoint_file = tf.train.latest_checkpoint("H_12_768_L12_vocab5/") saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file)) saver.restore(sess, checkpoint_file) variables = get_variables_to_restore() other_vars = [variable for variable in variables if not re.search("adam", variable.name)] var_saver = tf.train.Saver(other_vars) var_saver.save(sess, "light_bert/model.ckpt")
之后就可以直接加载这个去掉带"adam"的变量的模型用来做预测。这样虽然不能提升模型的预测速度,但是可以减小模型的内存。