一:硬件调优
决定dmbs性能因数有两个,硬件和软件。使用频率高的cpu、使用多处理器、加大内存容量、增加Cache、提高网络速度
但这些对系统心梗的提高是有限的
二:sql调优
1、调优原则:
‘二八’原则,将主要精力耗费在20%的最消耗系统资源的sql语句中,不要期望把所有的sql语句都调整到最优状态
2、索引:
索引是数据库调优的最根本优化方法,可以说索引是一切优化方法的内功。
根据索引顺序与数据表的物理顺序是否相同,可以将索引分为两类:聚簇索引,数据表的物理顺序和索引顺序相同;非聚簇索引,物理顺序和索引顺序不同
如汉语字典的拼音目录是聚类索引,偏旁部首为费聚类索引。应该在标准经常搜索的列或者安装顺序访问的列上创建聚类索引,聚类索引只能有一个,因为物理顺序只有一个,非聚类索引可以有多个
索引占据存储空间,因而创建必备的索引,一般是在检索需要读字段中创建索引。
索引会造成存储碎片问题,当删除一条记录时候会导致对应的索引记录为空,由于采用B数结构,对应索引不会删除,一段时间后出现大量的存储碎片,这些不仅会占用存储空间,更会降低数据库运行速度,如果存储碎片过多,则需要整理。最简单的是重建索引
3、表扫描和索因查找
一般数据访问采用:全表扫描和索因查找
如果表中有索引并且带匹配条件符合索引,则不会执行全表扫描。会直接去 索引加大查询速度(使用不当检索依旧会采用全表扫描)
4、常用优化手法
<1>创建必备的索引
<2>使用预编译查询,程序通常根据用户动态输入执行sql语句,这时候应该尽量使用参数化sql,不仅避免sql注入漏洞工具,而且第一次执行的时候dbms会对申请了语句进行查询优化且执行预编译,以后在这执行这个sql的时候就直接使用预编译的结果,大大提高执行速度
<3>调整where子句的连接顺序
DBMS一般采用自下而上的顺序解析where语句,因此表连接最好建立在其他where条件之前,那些可以过滤到大数量记录的条件写在where子句的末尾
<4>SELECT语句避免使用*
<5>尽量将多条sql语句压缩到一句sql中
<6>用WHERE字句替换having
having只会在检索出所有结果后对结果集进行过滤。如果能通过where限制记录数目,则能减少开销,having的条件一般用具聚合函数过滤,除此之外,应该讲条件写在where子句之外
<7>使用表的别名
当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个列名上。这样就可以减少解析的时间并减少那些由列名歧义引起的语法错误
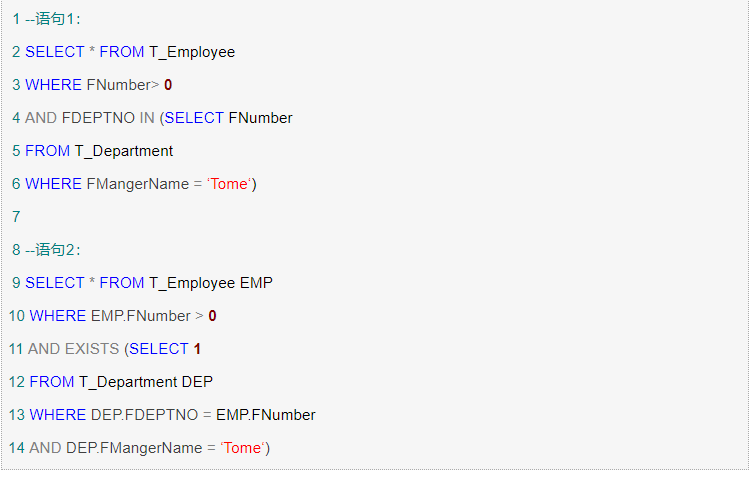
<8>用exists代替in
在查询中,为了满足一个条件,往往需要对另一个表进行联接,在这种情况下,使用EXISTS而不是IN通常将提高查询的效率,因为IN 子句将执行一个子查询内部的排序和合并。下面的语句2就比语句1效率更加高。
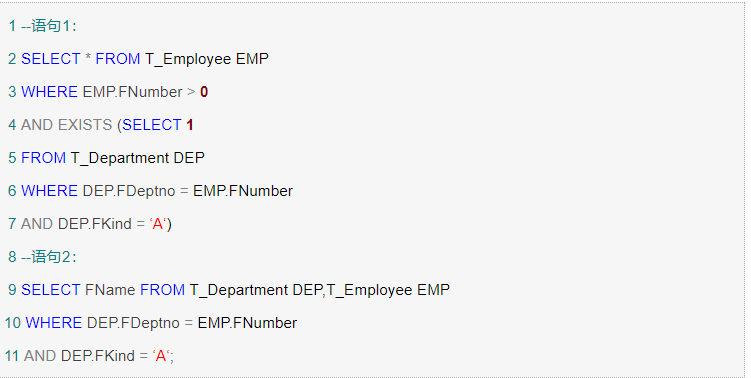
<9>用表连接替换你exists
通常来说,表连接的方式比EXISTS更有效率,因此如果可能的话尽量使用表连接替换EXISTS。下面的语句2就比语句1效率更加高。
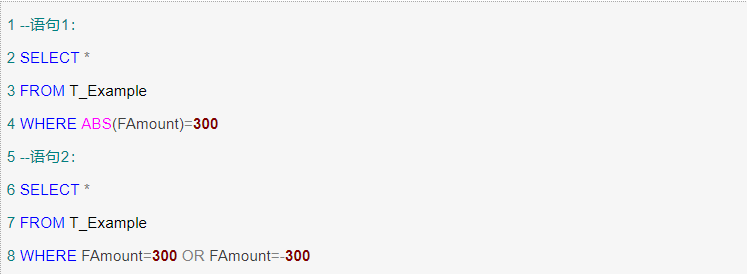
<10>避免在索引列上使用计算
在WHERE子句中,如果索引列是计算或者函数的一部分,DBMS的优化器将不会使用索引而使用全表扫描。
正确写法

同样的,不能在索引列上使用函数,因为函数也是一种计算,会造成全表扫描。下面的语句2就比语句1效率更加高。
参考地址 : http://www.cnblogs.com/cnjavahome/p/4230534.html