1. 深层网络的贪婪逐层预训练方法由Bengio等人在2007年提出,是一种重要的深度神经网络参数初始化和预训练方法。
2. 同时它也是一种堆叠自编码器,对于很多数据来说,仅使用两层神经网络的自编码器还不足以获取一种好的数据表示。为了获取更好的数据表示,我们可以使用更深层的神经网络。
深层神经网络作为自编码器提取的数据表示一般会更加抽象,能够更好地捕捉到数据的语义信息。 在实践中经常使用逐层堆叠的方式来训练一个深层的自编码器,
称为堆叠自编码器(Stacked Auto-Encoder, SAE)。堆叠自编码一般可以采用逐层训练(layer-wise training)来学习网络参数 [Bengio et al., 2007]。
Bengio, Y., Lamblin, P., Popovici, D., & Larochelle, H. (2007). Greedy layer-wise training of deep networks. In Advances in neural information processing systems (pp. 153-160).
对于深层模型的训练,通常采用BP算法来更新网络参数。但是需要对网络参数进行很小心的初始化,以免网络陷入局部最小点。
当然,现在已经有了很多网络参数初始化的办法,或者其他的深度网络处理技巧,可以很好的避免网络陷入局部最小点,
但鉴于无监督逐层贪婪预训练在深度网络优化中不可磨灭的影响,我们还是有必要了解这一方法。
考虑一个神经网络,如下图所示。它的输入是6维向量,输出是3维向量,代表输入样本属于三个类别的概率。

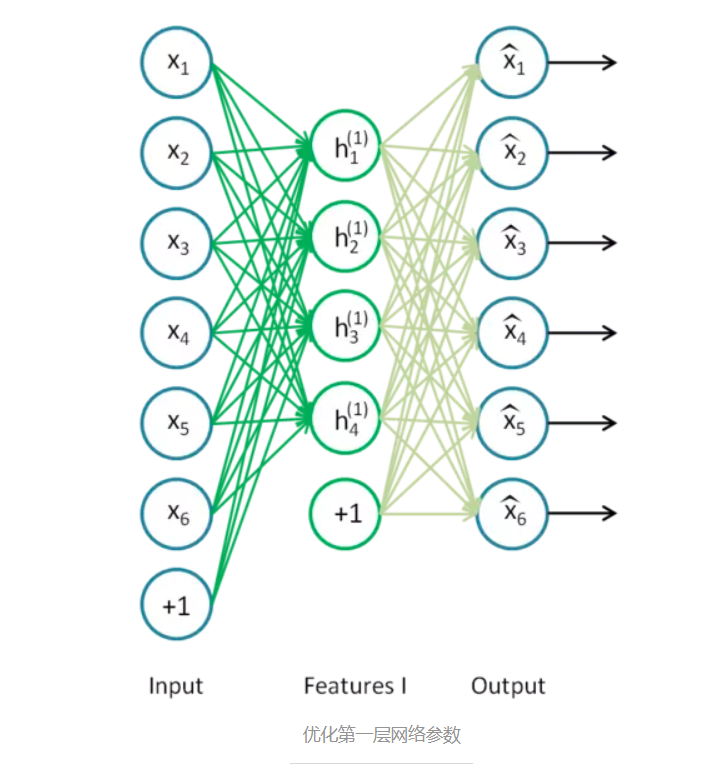
最开始我们通过高斯分布随机初始化网络参数,然后逐层地优化网络参数。首先第一层。如下图,我们只保留输入层Input和第一个隐藏层Features I,其余层去掉。
之后,加入一个输出层,该输出层的输出向量维度和输入层一样,从而构成一个自编码器。我们训练这个自编码器,便可以得到第一层的网络参数,即绿线部分。
然后是第二层的网络参数。如下图,我们只保留原始神经网络中的第一个隐藏层和第二个隐藏层,其余层去掉。
之后添加一个输出层,其输出向量维度和第一个隐藏层维度一样,从而构成一个自编码器,自编码器的输入是第一个隐藏层。
优化这个自编码器,我们就可以得到第二层网络参数,即红线部分。

优化这两个自编码器的过程就是逐层贪婪预训练。由于每个自编码器都只是优化了一层隐藏层,所以每个隐藏层的参数都只是局部最优的。
优化完这两个自编码器之后,我们把优化后的网络参数作为神经网络的初始值,之后微调(fine tune)整个网络,直到网络收敛。
参考资料
[1] UFLDL栈式自编码器
[2] Autoencoder
作者:JiaxYau
链接:https://www.jianshu.com/p/7cd769bbb3e6
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。