最近得到了一个依旧用芯片直读方式得到的Android全盘镜像,这次是一个红米手机的镜像,和之前的镜像不同,这次的分区类型的DOS分区,这里说明一下,算是对之前那篇记录的补充。
首先要纠正一下我的一个错误观点:认为DOS分区只和windows OS有关,和linux OS没有关系。正确的认知应该是:DOS分区是不分什么OS的,他和GPT分区相似,都是用来管理操作系统中各个文件系统分区的,而这些文件系统可以是windows的fat系列、NTFS,也可以是linux的extx系列。
DOS分区和GPT分区类比: 1)GPT分区中的EFI相当于x86的BIOS;
2)GPT分区表相当于DOS分区的MBR;
下面来详细说明一下DOS分区的格式:
1、MBR
我拿到的这个镜像,最开始是一个MBR扇区,MBR扇区由三部分组成:1)引导代码
2)分区表信息
3)签名值(55 AA)
想要解析这个镜像,分区表信息是我们的线索,DOS的分区表每项由16个字节构成,每个MBR的分区表有四项,也就是MBR的分区表占据64字节。MBR分区表每项结构是:
表里的所有数字都是十六进制的。
| 偏移(0x) | 字节数 | 描述 |
| 00 | 1 | 可引导标志,80是可引导,00是不可引导 |
| 01-03 | 3 | 分区起始CHS地址,这个好像现在没有怎么用到 |
| 04 | 1 | 分区类型,05是扩展分区,83是linux分区,82是linux swap,0B、0C是win95 FAT32,86、87是NTFS |
| 05-07 | 3 | 分区结束CHS地址 |
| 08-0B | 4 | 分区起始逻辑扇区号,逻辑的意思是相对于DOS分区的起始扇区号而言,也就是说是一个相对地址,计算的时候要通过加上MBR扇区起始地址装换成绝对地址 |
| 0C-0F | 4 | 分区大小扇区数 |
分区表的四项内容中,一般是三个主分区和一个扩展分区,主分区项目记录不一定要在扩展分区这一项的前面,就是说下面的两种顺序都是可以的:
| 主分区1 | 扩展分区 | |
| 主分区2 | 主分区1 | |
| 主分区3 | 主分区2 | |
| 扩展分区 | 主分区3 |
当然分区表不一定是四项都有内容,也可以是一个主分区,剩下的都是扩展分区,总体来说是比较灵活的。
2、EBR
EBR中的E就是extended 扩展的意思,这个扇区用来管理扩展分区,结构和MBR是类似的,也是用分区表来记录扩展分区中每个主分区的分区类型、逻辑起始扇区号、分区扇区数目。需要注意的一点事是,虽然EBR中的逻辑起始扇区号是相对于这个EBR扇区的地址而言的,但是在每个扩展分区的起始扇区号是相对主扩展分区而言,也就是说在跟进EBR分区表将相对地址转为绝对地址时要小心每个扩展分区地址的计算,其他每个分区的计算都只要考虑分区表的起始地址就可以了。下面这张图截自 马林《数据重现-文件系统原理精解与数据恢复最佳实践》 51页:
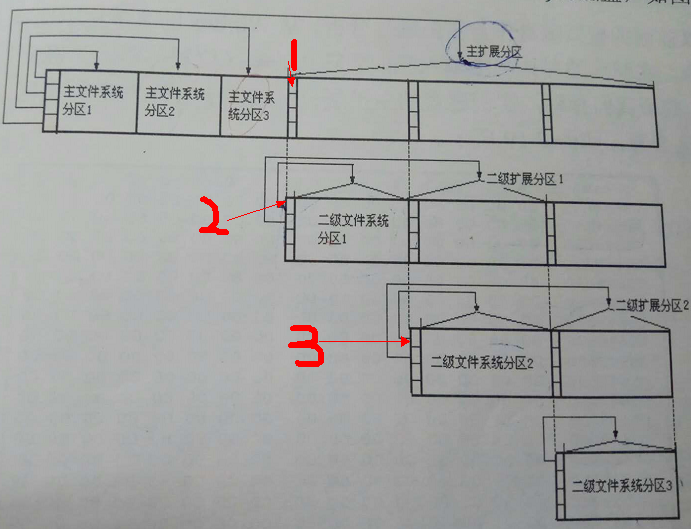
展示的是6个文件系统分区的情况,当计算二级系统文件分区1的绝对地址时,用2处地址做基址,二级扩展分区1的绝对地址用1处做基址;二级文件系统分区2的基址是3,二级扩展分区2的基址还是1。
另外要注意到,6个文件系统分区的组织情况是:三个主分区和三个逻辑分区即二级文件系统分区1,2,3都是逻辑分区,他们的EBR分区表最多包含两项,一个逻辑分区一个扩展分区。
3、superblock
我们根据MBR和EBR的指引找到了每个文件系统分区的类型,但我们怎么知道这个文件系统分区的名字是什么呢?(比如我们关注比较多的data分区)在GPT分区中,我们通过GPT分区表就直接得到了每个文件系统分区的分区名和地址,但在DOS分区中,我们需要利用超级块得到Android镜像各分区的名字。超级块的偏移0x78-0x87的16个字节记录了这个分区的分区名,因此,根据MBR和EBR分区表得到的文件系统分区起始地址和对应超级块中的分区名组合,我们就可以定位到目标分区的起始地址。
后续的解析工作就和解析ext4文件系统过程一样,不再重复。
参考:
马林《数据重现-文件系统原理精解与数据恢复最佳实践》 第二章和第五章