一、概述
1.kafka是什么
根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦
根据官网:http://kafka.apache.org/intro 的解释呢,是这样的:
Apache Kafka® is a distributed streaming platform
ApacheKafka®是一个分布式流媒体平台
l Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
l Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
l Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
l Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
l 无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
2.主要feature
1:It lets you publish and subscribe to streams of records.发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
2:It lets you store streams of records in a fault-tolerant way.以容错的方式记录消息流,kafka以文件的方式来存储消息流
3:It lets you process streams of records as they occur.可以再消息发布的时候进行处理
3.使用场景
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
经典组合是:kafka+storm+redis
4.消息队列补充
JMS参考基础篇ActiveMQ相关介绍:http://www.cnblogs.com/jiangbei/p/8311148.html
为什么需要消息队列:
消息系统的核心作用就是三点:解耦,异步和并行
kafka是类JMS,它吸收了JMS两种模式,将发布/订阅模式中消费者或者数据的方式从被动推送变成主动拉取
二、相关概念与组件
- Topics:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Producers:We'll call processes that publish messages to a Kafka topic producers。
- Consumers:We'll call processes that subscribe to topics and process the feed of published messages consumers。消费组是逻辑上的一个订阅者
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。(相应的同个topic的不同分区,有消费者组的概念)
什么是consumer group? 一言以蔽之,consumer group是kafka提供的可扩展且具有容错性的消费者机制。
既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,
即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。
当然,每个分区只能由同一个消费组内的一个consumer来消费。(网上文章中说到此处各种炫目多彩的图就会紧跟着抛出来,我这里就不画了,请原谅)。
个人认为,理解consumer group记住下面这三个特性就好了:
consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程
group.id是一个字符串,唯一标识一个consumer group
consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
- Segment:partition物理上由多个segment组成。
更多详细介绍,参考:http://kafka.apache.org/intro
http://blog.csdn.net/a568078283/article/details/51464524
消息发送流程:
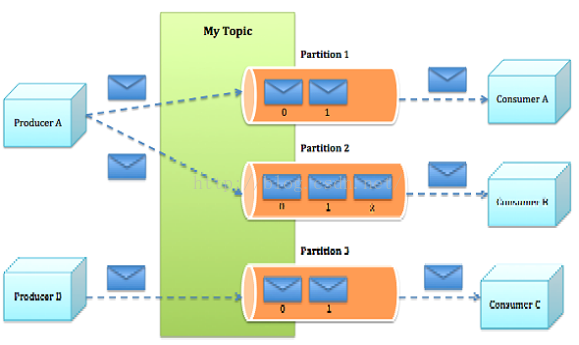
kafka消息结构:讲解参考:https://blog.csdn.net/u013256816/article/details/80300225

请带着以下问题思考:


分组策略
如何保证数据的完全生产
partition数量和broker的关系
每个partition数据如何保存到硬盘上
kafka有什么独特的特点(为什么它是大数据下消息队列的宠儿)
消费者如何标记消费状态
消费者负载均衡的策略
如何保证消费者消费数据是有序的
三、kafka集群安装
1.下载
这里换成一下wget,下载速度还是非常快的!
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/0.11.0.2/kafka_2.11-0.11.0.2.tgz
// 这里也可以使用windows下载完成后通过ftp进行上传(help命令进行提示),rz/sz请勿使用!属于远古时代的协议!大文件速度堪忧!
前导条件是java环境和zk,当然,新版的kafka已经内置了zk(属于可选配置了)
2.解压
tar -zxvf kafka_2.11-0.11.0.2.tgz -C apps/
这里就不采用mv进行解压后目录的重命名了,采用一下创建软连接的方式!
ln -s kafka_2.11-0.11.0.2/ kafka
3.修改配置文件
同样的,养成一个备份出厂设置的习惯:
[hadoop@mini1 config]$ cp server.properties server.properties.bak
此配置文件的各项说明参考:http://blog.csdn.net/lizhitao/article/details/25667831
[hadoop@mini1 config]$ vim server.properties
主要修改的配置如下:
最重要的参数为:broker.id、log.dir、zookeeper.connect
broker.id=0
listeners=PLAINTEXT://192.168.137.128:9092
port=9092
log.dirs=home/hadoop/apps/kafka/logs
number.partition=2
zookeeper.connect=mini1:2181,mini2:2181,mini3:2181
// 注意listener处必须是IP!原因参考:http://blog.csdn.net/louisliaoxh/article/details/51567515
4.分发安装包
[hadoop@mini1 apps]$ scp -r kafka_2.11-0.11.0.2/ mini2:/home/hadoop/apps/
[hadoop@mini1 apps]$ scp -r kafka_2.11-0.11.0.2/ mini3:/home/hadoop/apps/
5.修改分发的节点配置
先依次给mini2,mini3创建软连接:
ln -s kafka_2.11-0.11.0.2/ kafka
再修改配置:
修改broker.id分别是1和2(不得重复);修改监听处的IP
6.启动kafka
先启动zk(使用了自己的zk)
这里可以配置一下环境变量,可以方便后续的一些操作,并且这里配置了软连接的话是非常方便的(后续即使安装新版本,环境变量也无需变更)
模仿zk写一个一键启动脚本
#!/bin/bash BROKERS="mini1 mini2 mini3" KAFKA_HOME="/home/hadoop/apps/kafka" for BROKER in $BROKERS do echo "Starting kafka on ${BROKER} ... " ssh ${BROKER} "source /etc/profile; nohup sh ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties > /dev/null 2>&1 &" if [[ $? -ne 0 ]]; then echo "Start kafka on ${BROKER} is OK !" fi done
kafka启动命令如下:(这里使用后台启动)
bin/kafka-server-start.sh config/server.properties &
四、相关配置
参考博文:https://www.cnblogs.com/jun1019/p/6256371.html
强烈推荐入门:https://www.cnblogs.com/along21/p/10278100.html
官网配置讲解:http://kafka.apache.org/0110/documentation.html#configuration