一、基本原理
1.hbase的位置
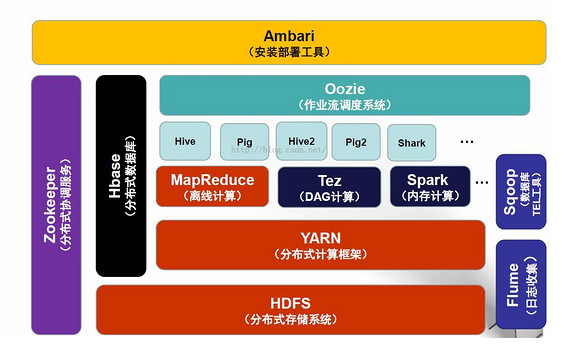
上图描述了Hadoop 2.0生态系统中的各层结构。其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBase提供了高性能的批处理能力,Zookeeper为HBase提供了稳定服务和failover机制,Pig和Hive为HBase提供了进行数据统计处理的高层语言支持,Sqoop则为HBase提供了便捷的RDBMS数据导入功能,使业务数据从传统数据库向HBase迁移变的非常方便。
2.体系图
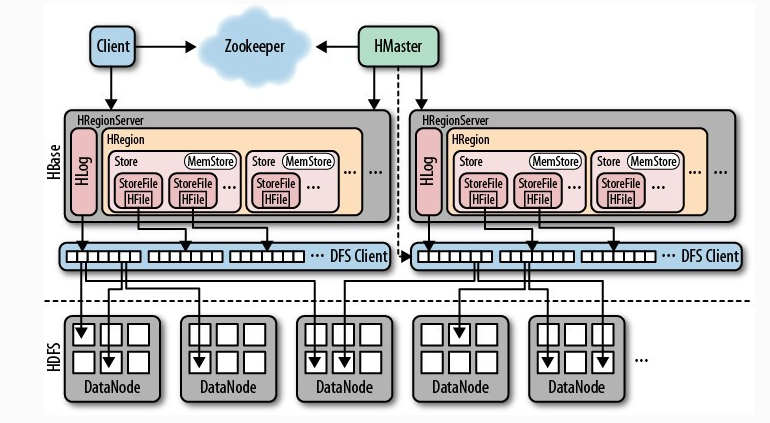
体系图中各个组件的含义,参考:http://blog.csdn.net/carl810224/article/details/51970039/
https://www.cnblogs.com/qiaoyihang/p/6246424.html
3.基本流程
1. 写流程
1、 client向hregionserver发送写请求。
2、 hregionserver将数据写到hlog(write ahead log)。为了数据的持久化和恢复。
3、 hregionserver将数据写到内存(memstore)
4、 反馈client写成功。
2. 数据flush过程
1、 当memstore数据达到阈值(老版本默认是64M),将数据刷到硬盘,将内存中的数据删除,同时删除Hlog中的历史数据。
2、 并将数据存储到hdfs中。
3、 在hlog中做标记点。
3. 数据合并过程
1、 当数据块达到4块,hmaster将数据块加载到本地,进行合并
2、 当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
3、 当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
4、 注意:hlog会同步到hdfs
4. hbase的读流程
1、 通过zookeeper和-ROOT- .META.表定位hregionserver。
2、 数据从内存和硬盘合并后返回给client
3、 数据块会缓存
二、MR操作
1.实现方法
Hbase对MapReduce提供支持,它实现了TableMapper类和TableReducer类,我们只需要继承这两个类即可。
2.准备相关表
1、建立数据来源表‘word’,包含一个列族‘content’
向表中添加数据,在列族中放入列‘info’,并将短文数据放入该列中,如此插入多行,行键为不同的数据即可
2、建立输出表‘stat’,包含一个列族‘content’
3、通过Mr操作Hbase的‘word’表,对‘content:info’中的短文做词频统计,并将统计结果写入‘stat’表的‘content:info中’,行键为单词
3.实现代码
package com.itcast.hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
/**
* mapreduce操作hbase
* @author wilson
*
*/
public class HBaseMr {
/**
* 创建hbase配置
*/
static Configuration config = null;
static {
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");
config.set("hbase.zookeeper.property.clientPort", "2181");
}
/**
* 表信息
*/
public static final String tableName = "word";//表名1
public static final String colf = "content";//列族
public static final String col = "info";//列
public static final String tableName2 = "stat";//表名2
/**
* 初始化表结构,及其数据
*/
public static void initTB() {
HTable table=null;
HBaseAdmin admin=null;
try {
admin = new HBaseAdmin(config);//创建表管理
/*删除表*/
if (admin.tableExists(tableName)||admin.tableExists(tableName2)) {
System.out.println("table is already exists!");
admin.disableTable(tableName);
admin.deleteTable(tableName);
admin.disableTable(tableName2);
admin.deleteTable(tableName2);
}
/*创建表*/
HTableDescriptor desc = new HTableDescriptor(tableName);
HColumnDescriptor family = new HColumnDescriptor(colf);
desc.addFamily(family);
admin.createTable(desc);
HTableDescriptor desc2 = new HTableDescriptor(tableName2);
HColumnDescriptor family2 = new HColumnDescriptor(colf);
desc2.addFamily(family2);
admin.createTable(desc2);
/*插入数据*/
table = new HTable(config,tableName);
table.setAutoFlush(false);
table.setWriteBufferSize(5);
List<Put> lp = new ArrayList<Put>();
Put p1 = new Put(Bytes.toBytes("1"));
p1.add(colf.getBytes(), col.getBytes(), ("The Apache Hadoop software library is a framework").getBytes());
lp.add(p1);
Put p2 = new Put(Bytes.toBytes("2"));p2.add(colf.getBytes(),col.getBytes(),("The common utilities that support the other Hadoop modules").getBytes());
lp.add(p2);
Put p3 = new Put(Bytes.toBytes("3"));
p3.add(colf.getBytes(), col.getBytes(),("Hadoop by reading the documentation").getBytes());
lp.add(p3);
Put p4 = new Put(Bytes.toBytes("4"));
p4.add(colf.getBytes(), col.getBytes(),("Hadoop from the release page").getBytes());
lp.add(p4);
Put p5 = new Put(Bytes.toBytes("5"));
p5.add(colf.getBytes(), col.getBytes(),("Hadoop on the mailing list").getBytes());
lp.add(p5);
table.put(lp);
table.flushCommits();
lp.clear();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if(table!=null){
table.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* MyMapper 继承 TableMapper
* TableMapper<Text,IntWritable>
* Text:输出的key类型,
* IntWritable:输出的value类型
*/
public static class MyMapper extends TableMapper<Text, IntWritable> {
private static IntWritable one = new IntWritable(1);
private static Text word = new Text();
@Override
//输入的类型为:key:rowKey; value:一行数据的结果集Result
protected void map(ImmutableBytesWritable key, Result value,
Context context) throws IOException, InterruptedException {
//获取一行数据中的colf:col
String words = Bytes.toString(value.getValue(Bytes.toBytes(colf), Bytes.toBytes(col)));// 表里面只有一个列族,所以我就直接获取每一行的值
//按空格分割
String itr[] = words.toString().split(" ");
//循环输出word和1
for (int i = 0; i < itr.length; i++) {
word.set(itr[i]);
context.write(word, one);
}
}
}
/**
* MyReducer 继承 TableReducer
* TableReducer<Text,IntWritable>
* Text:输入的key类型,
* IntWritable:输入的value类型,
* ImmutableBytesWritable:输出类型,表示rowkey的类型
*/
public static class MyReducer extends
TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//对mapper的数据求和
int sum = 0;
for (IntWritable val : values) {//叠加
sum += val.get();
}
// 创建put,设置rowkey为单词
Put put = new Put(Bytes.toBytes(key.toString()));
// 封装数据
put.add(Bytes.toBytes(colf), Bytes.toBytes(col),Bytes.toBytes(String.valueOf(sum)));
//写到hbase,需要指定rowkey、put
context.write(new ImmutableBytesWritable(Bytes.toBytes(key.toString())),put);
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
config.set("df.default.name", "hdfs://master:9000/");//设置hdfs的默认路径
config.set("hadoop.job.ugi", "hadoop,hadoop");//用户名,组
config.set("mapred.job.tracker", "master:9001");//设置jobtracker在哪
//初始化表
initTB();//初始化表
//创建job
Job job = new Job(config, "HBaseMr");//job
job.setJarByClass(HBaseMr.class);//主类
//创建scan
Scan scan = new Scan();
//可以指定查询某一列
scan.addColumn(Bytes.toBytes(colf), Bytes.toBytes(col));
//创建查询hbase的mapper,设置表名、scan、mapper类、mapper的输出key、mapper的输出value
TableMapReduceUtil.initTableMapperJob(tableName, scan, MyMapper.class,Text.class, IntWritable.class, job);
//创建写入hbase的reducer,指定表名、reducer类、job
TableMapReduceUtil.initTableReducerJob(tableName2, MyReducer.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}