一、简介
见官网:http://www.selenium.org.cn/
简单使用参考:https://www.jianshu.com/p/3aa45532e179
二、安装
使用pip安装
pip install Selenium -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
下载chrome驱动(框架需要):
https://chromedriver.storage.googleapis.com/index.html?path=2.35/
将目录放到path:(zip解压到当前文件夹)
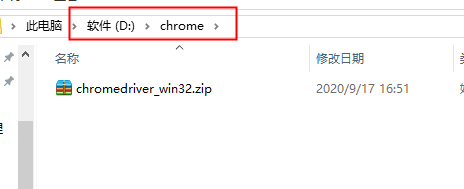
三、快速入门
1.声明浏览器对象
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
2.简单示例:打印网页源代码
# -*- coding:UTF-8 -*- from selenium import webdriver if __name__ == '__main__': target = 'http://www.baidu.com' browser = webdriver.Chrome() browser.get(target) # 打开浏览器预设网址 print(browser.page_source) # 打印网页源代码 browser.close() # 关闭浏览器
// 这样,就实现了简单的使用
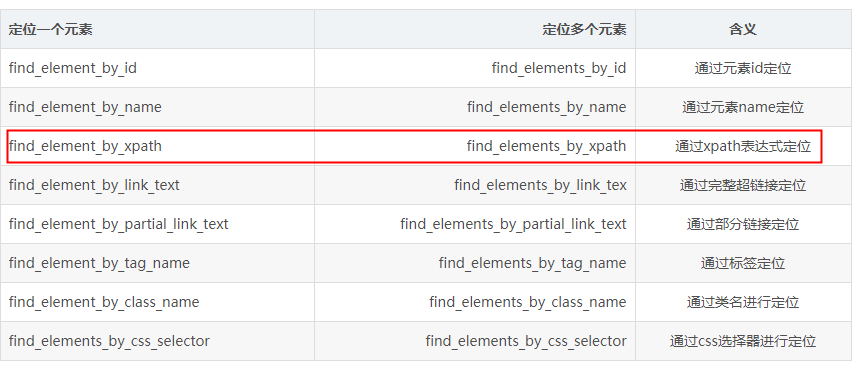
3.元素定位
多种元素定位方式:推荐xpath:
查看文本可以用text属性 //name/text()或者.text属性:
a = browser.find_element_by_xpath('//*[@id="xiaomiroot"]/ul[1]/li[1]/div[1]/p').text print(a)
4.简单示例
提取页面中元素
# -*- coding:UTF-8 -*- from selenium import webdriver if __name__ == '__main__': target = 'http://www.zjzwfw.gov.cn/zjservice/front/index/page.do?webId=83' browser = webdriver.Chrome() browser.get(target) # 打开浏览器预设网址 browser.implicitly_wait(3) # 等待3秒 a = browser.find_element_by_xpath('//*[@id="id17"]/div[1]/div[2]/span').text print(a) browser.close() # 关闭浏览器
// 这里需要注意一个等待几秒等页面加载完的坑(当然也可以用不太推荐的time.sleep),否则可能会报没有这个元素的错