1.案例数据来自python数据分析手册,github地址:https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks/data
不克隆项目,怎么在github下载单个文件?:https://www.cnblogs.com/zhaoqingqing/p/5534827.html
2.pandas读取文件,参考:https://blog.csdn.net/sinat_29957455/article/details/79054126
1.导入三剑客的包:

2.读取数据:
read_csv可以读取1G的数据(excel无法打开)
读入各州缩写:

读入各州面积:

读入各州人口:

3.合并pop和abbr两个df
使用简称,合并全称,可知,需要使用merge:
并且,左右两列没有相同columns,需要使用left_on/right_on来进行限定;

由于默认使用的是内连接,所以通过shape发现会有部分未连接上的数据,通过how,可以控制内外连接方式:

//使用right右连接,也会出现2448,原因是虽然右表只有51条,但是左表有多条对应,会出现一对多
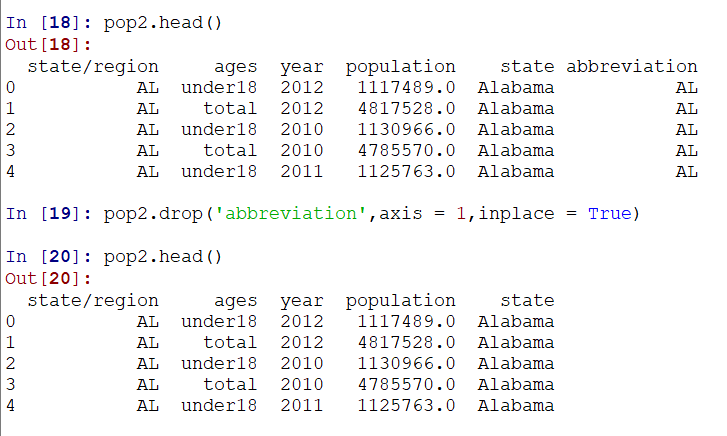
发现用于连接的列,有重复的列,我们可以使用drop进行删除一列:通过axis控制,我们就删除了一列:
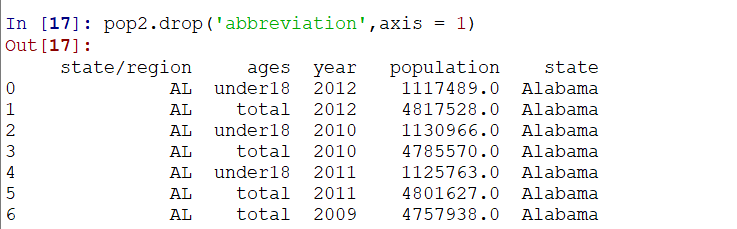
但是特别注意,drop返回的是删除后的新DF,原先的DF未改变(这点可以通过看控制台是否输出了内容,有输出时则是返回了新的数据,没有则是在原基础上修改)
要想在原基础上修改,需要控制inplace参数:
通过isnull()返回和原先形状相等的df,再通过any看哪一列有空值:

进一步,通过空值操作,可以查看具体哪些州有数据缺失:(通过unique来查看唯一值)

下一步,使用正确的值,填充这些缺失值:(通过boolean值来进行筛选,注意boolean这个Series的产生)
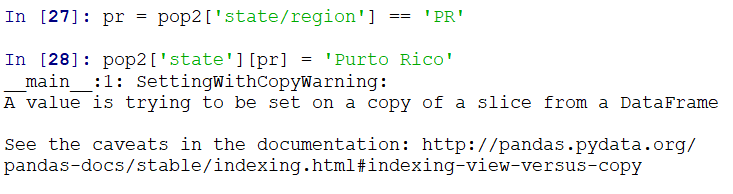
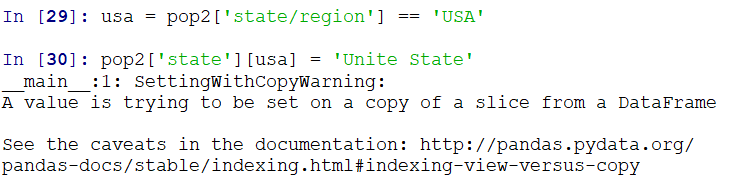
USA的处理,同理:
验证结果:(可以发现state已经没有空值)

4.合并pop和areas两个df
同样,使用merge:(注意这里使用left合并)

继续使用isnull()来检测空值:

发现area有空值,我们继续使用上面类似的方法,空值检测并填充:
具体这里是先检测area列的bool值,再通过pop3取到哪些state是空:

可以通过dropna来删除含有空数据的行:(dropna的文档注意查看)

检查空值处理结果:

5.使用query查找数据
使用query来进行数据检索:https://blog.csdn.net/tcy23456/article/details/85887334

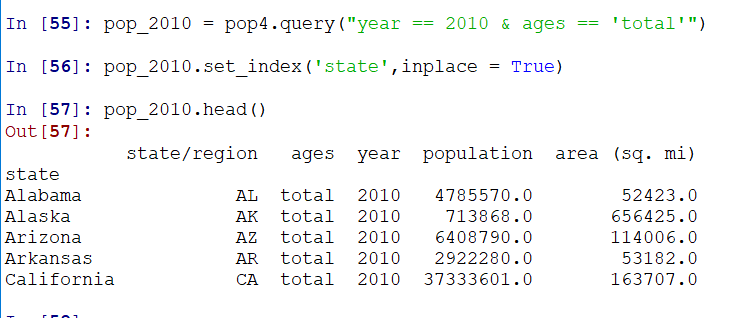
对查询结果进行索引重排,使用set_index,使得state成为新的Index:(注意通过inplace控制替换原值)
通过计算,返回人口密度的series:

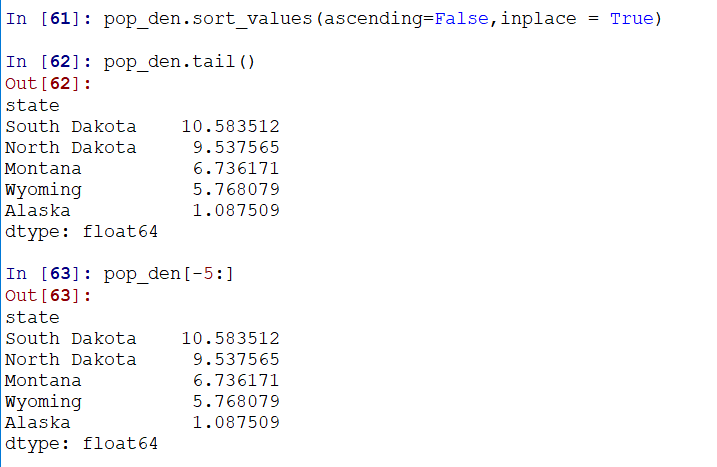
通过sort_values进行数据排序:
进一步的,可以通过切片或者tail()函数取最小的几个,取top几
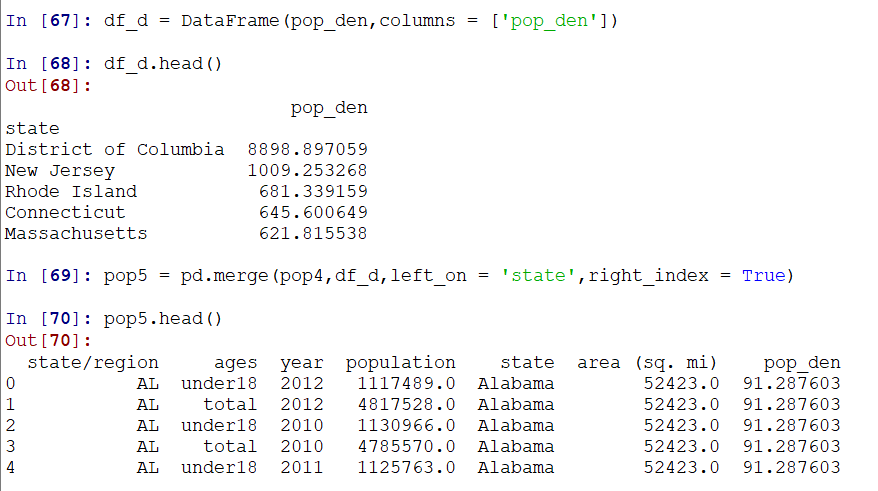
使用merge,可以将计算出的密码,融合进去人口结果集:
此处需要将Series转换为df再计算: