一、什么是事务?
1、事务遵循ACID原则:原子性(Atomic)、一致性(Consistency)、隔离性(Isolation)、持久性(durability);
二、为什么要事务?
保证数据的安全;
三、事务中出现的问题?
脏读:张三的账户有5000元,事务A将账户余额修改为8000,但事务A尚未提交;事务B访问账户读到了张三的账户是8000,此时事务A发生了异常回滚了,张三账户仍为5000;事务B读到的8000即为脏数据;
不可重复读:张三账户有5000元,事务A查询账户为5000,此时事务B更新账户为8000,事务A未提交,再次查询账户为8000,两次查询不一样,事务A发生了不可重复读;
幻读:工资为5000的员工有10个,事务A读取到有10个工资为5000的员工,事务B此时插入一个5000员工,事务A再次读取到有11个工资为5000的员工,事务A就发生了幻读;
第一类丢失更新:
在完全未隔离事务的情况下,两个事务更新同一条数据资源,某一事务完成,另一事务异常终止,回滚造成第一个完成的更新也同时丢失 。这个问题现代关系型数据库已经不会发生。
第二类丢失更新:
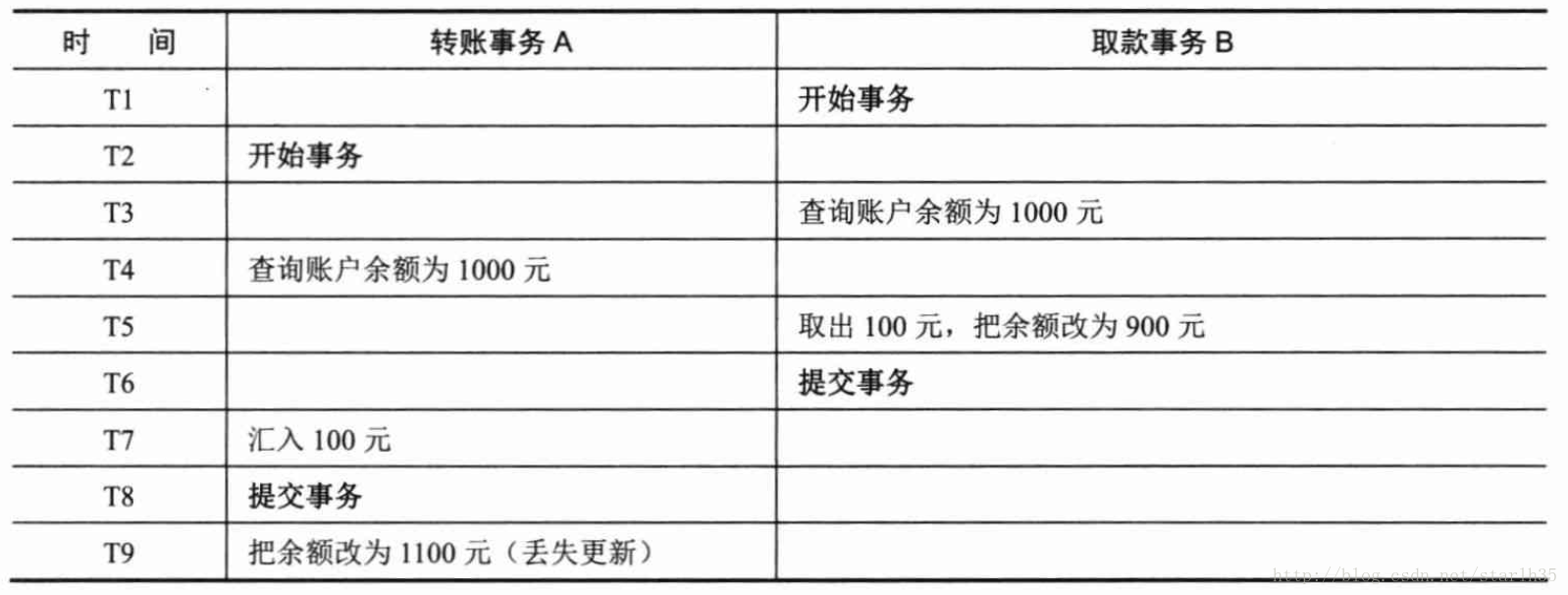
A事务覆盖B事务已经提交的数据,造成B事务所做的操作丢失
四、如何解决这些问题?
简单来讲,解决不可重复读的方法是 锁行,解决幻读的方式是 锁表。
四种隔离级别:
1、读未提交(Read uncommit);
这时,select语句不加锁,可能读到数据不一致,即脏读;并发高隔离性最差的一种级别;
2、读已提交(Read commit);
可以避免脏读;
----------------------------------------互联网大数据量,高并发量的场景下,几乎不使用以上两种级别-----------------------------------------------
3、可重复读(Repeatable read );
避免脏读、可重复读。是mysql的默认隔离级别
4、串行化(Serializable);
可避免脏读、可重复读、幻读的发生;
以上四种隔离级别最高的是 Serializable 级别,最低的是 Read uncommitted 级别,当然级别越高,执行效率就越低。
像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。