Tips
- 只要引入了异常机制,无论系统是否会抛出异常,异常代码都会影响代码的大小与性能
- 未触发异常时对系统影响并不明显,主要影响一些编译优化手段
- 触发异常之后按异常实现机制的不同,其对系统性能的影响也不相同,不过一般很明显
- 不用担心异常对正常代码逻辑性能的影响 && 不要借用异常机制处理业务逻辑
- 异常机制只用于异常问题的处理,原因如上
异常实现机制
setjmp/longjmp(SJLJ)
特点:通用性强但性能差,只有非常老的编译器使用此类方法
用 setjmp 实现的异常机制也被称为 Portable Exception Handling ,因为这类机制直接使用了 c 语言提供的基础方法(setjmp/longjmp,简称 sjlj),有着很强的可移植性,但性能差
这篇文章使用 sjlj 实现了一个简单的异常机制,其主要思想如下:
#include <stdio.h>
#include <setjmp.h>
// 注意 setjmp 在第一次调用时返回 0,第二次调用时返回 longjmp 第二个参数的值
#define TRY do{ jmp_buf ex_buf__; switch( setjmp(ex_buf__) ){ case 0:
#define CATCH(x) break; case x:
#define ETRY } }while(0)
#define THROW(x) longjmp(ex_buf__, x)
#define FOO_EXCEPTION (1)
#define BAR_EXCEPTION (2)
#define BAZ_EXCEPTION (3)
int main(int argc, char** argv) {
TRY {
printf("In Try Statement
");
THROW( BAR_EXCEPTION );
printf("I do not appear
");
}
CATCH( FOO_EXCEPTION ) {
printf("Got Foo!
");
}
CATCH( BAR_EXCEPTION ) {
printf("Got Bar!
");
}
CATCH( BAZ_EXCEPTION ) {
printf("Got Baz!
");
}
ETRY;
return 0;
}
将上面思想应用到 C++ 中,因为抛出异常时局部对象需要被析构,所以编译器需要为每个 try 块维护一个局部对象信息链表,以便于在捕获异常时析构这些对象。上面的方法没有体现出异常的抛出机制,即异常是可以层层上抛的,为了实现这个机制,编译器需要维护一个变量用于保存异常对象的层次结构
由此可知此类异常实现方法的额外开销如下(代码膨胀与性能损耗皆有):
- 每个 try 块的起始部分都需要调用一次 setjmp
- 一个链表类型的变量用于记录异常的层次信息,以便于异常的向上传递
- 一个链表类型的变量用于记录局部对象的创建情况,出现异常时这些对象需要被析构
由此可见,即使系统不抛出异常,这类异常机制对系统性能的影响也很大
基于表格的异常机制
大部分现代编译器都使用了此类方法实现异常机制
编译器知道哪些位置有抛异常的可能性的(比如 throw 语句、没有使用 noexcept 修饰的函数等),所以编译器在编译代码时生成若干表格以方便异常抛出时处理异常
编译器会生成几种不同类型的表格来辅助异常处理,示例如图:
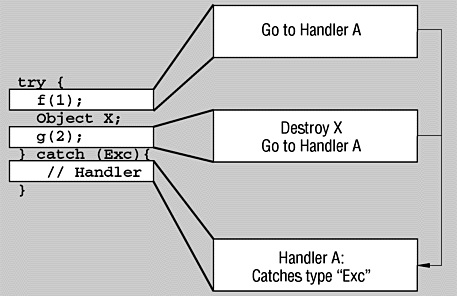
- 第一种表格用于映射 PC 指针和具体的异常处理表。编译器知道哪些命令可能抛异常,所以维护了一个 map,使用抛出异常的地址来寻找具体的处理表
- 处理表(action table),异常出现后,具体位置的异常处理流程其实已经确定,处理表保存异常处理流程
- handler table,具体的 catch 处理表
和 SJLJ 相比,基于表格的异常处理大大减少了运行时开销,没有了 setjmp 操作与各个链表变量的维护开销
但相较于 SJLJ 方法,基于表格的方法需要消耗更多的静态存储空间,比如上面的三张表一般在编译时即已计算完成,这放大了可执行文件的大小
基于表格的异常机制依旧会影响系统的性能
异常与编译优化
原始代码如下:
struct Object { float x, y; ~Object(); };
Object object;
for (int i = 1; i < 1000; i++) {
object.x += f(i);
object.y += g(i);
}
没有异常机制时编译器可能生成如下代码(使用寄存器提高执行效率):
register float tmp_x = object.x;
register float tmp_y = object.y;
for (int i = 0; i < 1000; i++) {
tmp_x += f(i);
tmp_y += g(i);
}
object.x = tmp_x;
object.y = tmp_y;
如果存在异常处理,因为 f(i)/g(i) 有抛出异常的可能且抛出异常时线程的处理逻辑已经 goto 到了指定的异常处理表格,如果编译器做了上述优化且循环中途 f/g 抛出了异常,那么栈中 x 的值很有可能是错误的,因为寄存器中的值还没有同步到内存中。有异常机制编译器就不能做上述优化
基于表格的异常机制对性能的影响分类大致如下:
- Cost of saving and restoring registers
- Ordering constraints due to additional arcs in the control graph
在 IA-64 体系结构下有一定的优化手段来解决上面的问题,详细信息可参考这里:
https://www.usenix.org/legacy/events/osdi2000/wiess2000/full_papers/dinechin/dinechin_html/
比如使用 RSE (Register Stack Engine) 解决第一个问题;第二各问题可以通过其他编译手段得到部分解决
优化异常
这里只介绍几个编程时可用的方法,其他优化方法一般是面向编译器的,比如异常表的压缩等
- 明确告诉编译器当前函数不会抛异常,比如 C++ 11 后使用 noexcept 关键字标识函数不会抛异常
- 这种方法有效是因为编译器不会在调用此类函数的位置添加异常跳转代码
- 其他
异常替换方法
Expected<T>
C++11 以后支持不受限制的联合体,可以利用这个特性在一个对象中同时保存有效数据和异常信息
template <class T>
class Expected {
private:
union {
T value;
Exception exception;
};
public:
Expected(const T& value) ...
Expected(const Exception& ex) ...
bool hasError() ...
T value() ...
Exception error() ...
};
使用方式如下:
Expected<int> exitWithExpected() {
if (getRandom() == errorInt) {
return std::runtime_error("Halt! If you want..."); // Return; don't throw!
}
return 0;
}
其他类似的工具有:
参考:
- https://gcc.gnu.org/wiki/WindowsGCCImprovements
- C++ Exception Handling for IA-64
- Structured Exception Handling
- C++异常机制的实现方式和开销分析
- https://gcc.gnu.org/wiki/Dwarf2EHNewbiesHowto
- https://www.codeproject.com/Articles/2126/How-a-C-compiler-implements-exception-handling
- https://github.com/itanium-cxx-abi/cxx-abi/blob/master/exceptions.pdf