公司最近一直推崇拉姆达。自己怀着好奇心学习
Lambda在集合中的使用
列表的遍历
“Lambda 表达式”是一个匿名函数,它可以包含表达式和语句,并且可用于创建委托或表达式树类型.
所有 Lambda 表达式都使用 Lambda 运算符 =>,该运算符读为“goes to”.该 Lambda 运算符的左边是输入参数(如果有),右边包含表达式或语句块.Lambda 表达式 x => x * x 读作“x goes to x times x”.可以将此表达式分配给委托类型提起对于集合的遍历,恐怕下面的这种方式已经是一种思维定式了吧:
final List<String> friends = Arrays.asList("Brian", "Nate", "Neal", "Raju", "Sara", "Scott");
for(int i = 0; i < friends.size(); i++) {
System.out.println(friends.get(i));
}
但是仔细想想,以上的代码似乎出现了过多的细节,比如循环变量i的出现。在做简单的遍历操作时,循环变量实际上是不必要的,只有在对某个特定位置的元素执行某个特殊操作时,循环变量的使用才有意义。所以,在Java中引入了增强的for循环,在这种循环方式中,循环变量是不必要的:
for(String name : friends) {
System.out.println(name);
}
这种方式,在实现细节上使用的是iterator接口和它的hasNext(),next()方法。
无论使用哪种for循环,它们仍然使用了外部遍历器(External Iterator)。即在for循环中,你总是有办法通过诸如break,continue等方式来控制遍历的过程。
与外部遍历器相对的,是内部遍历器(Internal Iterator)。在Java 8中,Iterable接口被增强了,现在该接口拥有一个forEach方法用来实现内部遍历器。forEach方法会接受一个Consumer接口类型作为参数,该接口是一个函数式接口(Functional Interface),它是内部遍历器的实现方式。关于函数式接口,可以参考上一篇文章。
friends.forEach(new Consumer<String>() {
public void accept(final String name) {
System.out.println(name);
}
});
很显然,上述代码中使用的匿名类在Java 8中并不是最好的方案,在这种场景下Lambda表达式是更好的选择:
friends.forEach((final String name) -> System.out.println(name));
forEach方法本身是一个高阶函数,因为它接受了一个Lambda表达式作为其参数,而Lambda表达式在本质上则是一个函数。在Lambda表达式的左边,声明了一个String类型的变量name,它代表了集合中的元素。而箭头右边的代码则表达了对于该元素应该执行何种操作。forEach之所以被称为内部遍历器,原因在于一旦它开始执行了,那么遍历操作就不能够被轻易中断。
同时,借助Java编译器的类型推导(Type Inference)特性,Lambda表达式能够被进一步简化如下:
friends.forEach((name) -> System.out.println(name));
此时,编译器能够通过运行时的上下文知道这个name变量的类型是String。
另外,当Lambda表达式左端只接受一个变量的时候,括号也是可以省略的:
friends.forEach(name -> System.out.println(name));
但是用类型推导有一个不好的地方,就是参数不会自动被final修饰。因此,在Lambda表达式右端,是可以对参数进行修改的,然而这种行为是不被倡导的。
上面的代码已经足够简洁了,但是还有更简洁的方法,那就是使用方法引用:
friends.forEach(System.out::println);
使用这种方式甚至不需要写出Lambda表达式的左端参数部分。关于方法引用的详细情况,会在以后进行介绍。
与使用外部遍历不同,使用内部遍历的好处在于:
- 放弃使用显式的for循环,因其与生俱来的顺序执行的特性会阻碍并行化。换言之,使用内部遍历时,程序的并行程度能够很容易地被提高。
- 声明式的代码比命令式的代码更简洁,更具有可读性,更优雅。
列表的变换
将一个集合通过某种计算得到另一个集合是一种常用的操作,也是Lambda表达式的用武之地。 比如,以将一个名字集合转换为首字母大写了的名字集合为例。
为了不改变原集合,最“自然”的方式如下:
final List<String> uppercaseNames = new ArrayList<String>();
for(String name : friends) {
uppercaseNames.add(name.toUpperCase());
}
以上代码使用了外部遍历器,即for循环来完成集合操作。而将命令式代码转变为声明式代码(也就是函数式)的首要任务就是观察遍历的使用方式,尽可能地将外部遍历更改为内部遍历:
final List<String> uppercaseNames = new ArrayList<String>();
friends.forEach(name -> uppercaseNames.add(name.toUpperCase()));
System.out.println(uppercaseNames);
好了,现在我们使用了forEach来代替for循环。但是感觉代码并没有变的简洁多少。 我们可以使用其他的函数式接口(Functional Interface)来实现集合的转换。事实上,map方法比forEach方法更胜任这一类转换工作:
friends.stream()
.map(name -> name.toUpperCase())
.forEach(name -> System.out.print(name + " "));
System.out.println();
这里使用了一个新的方法叫做stream()。在Java 8中,所有的集合类型都拥有这个方法。该方法的返回值是一个Stream类型的实例,该实例将集合本身包含在内(即上述的friends集合被包含在了stream实例中)。
可以将它理解成一个建立在集合上的iterator,它提供了除了forEach之外的更加高级的方法,如上述的map()。map方法的作用在于,它能够将接受的一个输入序列转换成一个输出序列(即完成转换工作)。这也意味着map方法是存在返回值的,所以后续的forEach方法操作的集合即是map方法返回的集合。map也可连续操作如 list2.parallelStream().map(String::toUpperCase).map(obj->obj+"===").forEach(System.out::println);将第一个map操作完的值给第二个map继续操作 阿西吧也可以 .filter(过滤操作).filter(在次进行过滤操作)
集合的转换操作可以是任意的,比如需要得到每个名字的长度:
friends.stream()
.map(name -> name.length())
.forEach(count -> System.out.print(count + " "));
// 5 4 4 4 4 5
使用方法引用
使用方法引用能够对上面的代码进行简化:
friends.stream()
.map(String::toUpperCase)
.forEach(name -> System.out.println(name));
回顾之前我们提到过的,当一个方法接受函数式接口作为参数时,可以传入Lambda表达式或者方法/构造器的引用进行调用。而以上的String::toUpperCase就是一个方法应用。
注意到对该方法进行引用时,省略了其参数信息。这是因为Java编译器在为该方法引用生成实例时,会进行类型推导自动地将集合中的元素作为参数传入到该方法中。
寻找元素
比如,当我们需要得到名字集合中所有以N开头的名字时,最“自然”的实现方式马上就会反映如下:
final List<String> startsWithN = new ArrayList<String>();
for(String name : friends) {
if(name.startsWith("N")) {
startsWithN.add(name);
}
}
但是,我们可以让这一切变得更加简单和优雅:
final List<String> startsWithN = friends.stream()
.filter(name -> name.startsWith("N"))
.collect(Collectors.toList());
对于filter方法,它期待的参数是一个返回boolean类型的Lambda表达式。对于被操作的集合中的每个元素而言,如果Lambda表达式返回的是true,那么就意味着filter后得到的stream实例中是包含该元素的,反之亦然。最后,可以通过调用stream实例的collect方法来将stream实例转换成一个List实例。
Lambda表达式的重用
比如,当需要对不止一个集合进行操作时:
final long countFriendsStartN = friends.stream().filter(name -> name.startsWith("N")).count();
final long countComradesStartN = comrades.stream().filter(name -> name.startsWith("N")).count();
final long countEditorsStartN = editors.stream().filter(name -> name.startsWith("N")).count();
显而易见,Lambda表达式需要被重用。我们可以将Lambda表达式给保存到一个变量中,就像Java处理其他任何类型的变量一样。问题来了?Lambda表达式的类型是什么呢,在Java这种静态类型语言中,我们不能单单使用诸如var,val就来代表一个Lambda表达式。
对于filter方法接受的Lambda表达式,它是符合Predicate接口类型的,因此可以声明如下:
final Predicate<String> startsWithN = name -> name.startsWith("N");
final long countFriendsStartN = friends.stream().filter(startsWithN).count();
final long countComradesStartN = comrades.stream().filter(startsWithN).count();
final long countEditorsStartN = editors.stream().filter(startsWithN).count();
但是,问题又来了!如果在某些情况下需要检测的不是以N开头,而是以别的字母如B开头呢? 那么,就需要再创建一个Lambda表达式并保存到变量中:
final Predicate<String> startsWithN = name -> name.startsWith("N");
final Predicate<String> startsWithB = name -> name.startsWith("B");
final long countFriendsStartN = friends.stream().filter(startsWithN).count();
final long countFriendsStartB = friends.stream().filter(startsWithB).count();
显然,这并不是长久之计。不能因为需要检测的首字母不同,就创建额外的Lambda表达式。我们需要它进行进一步的抽象。
第一种方法:
public static Predicate<String> checkIfStartsWith(final String letter) {
return name -> name.startsWith(letter);
}
通过一个带参数的方法来得到需要的Lambda表达式。这个方法就是传说中的高阶函数,因为它返回了一个Lambda表达式作为返回值,而Lambda表达式本质上是一个函数。
另外,这里也体现了Java 8中关于Lambda表达式的另外一个特性:闭包和作用域。在以上返回的Lambda表达式中引用了一个letter变量,而这个letter变量则是checkIfStartsWith方法接受的参数,就像JavaScript等拥有闭包特性的语言那样,Java也具有这种特性了。
但是,在Java中利用闭包对变量进行访问时,有需要注意的问题。我们只能访问被final修饰的变量或者本质上是final的变量。正如上面checkIfStartsWith声明的参数被final修饰那样。
这是因为,Lambda表达式可能在任何时候被执行,也可能被任何其他线程执行。所以为了保证不出现竞态条件(Race Condition),需要保证Lambda表达式中引用到的变量不会被改变。
final long countFriendsStartN = friends.stream().filter(checkIfStartsWith("N")).count();
final long countFriendsStartB = friends.stream().filter(checkIfStartsWith("B")).count();
利用上述可以根据要求动态生成Lambda表达式的高阶函数,就可以按照上面这个样子来进行代码重用了。
缩小作用域
实际上,使用static来实现以上的高阶函数并不是一个好主意。可以将作用域缩小一些:
final Function<String, Predicate<String>> startsWithLetter =
(String letter) -> {
Predicate<String> checkStartsWith = (String name) -> name.startsWith(letter);
return checkStartsWith;
};
startsWithLetter变量代表的是一个Lambda表达式,该表达式接受一个String作为参数,返回另外一个Lambda表达式。这也就是它的类型Function>所代表的意义。
目前来看,使用这种方式让代码更加复杂了,但是将它简化之后就成了下面这个样子:
final Function<String, Predicate<String>> startsWithLetter = (String letter) -> (String name) -> name.startsWith(letter);
还可以通过省略参数类型进行进一步的简化:
final Function<String, Predicate<String>> startsWithLetter = letter -> name -> name.startsWith(letter);
乍一看也许觉得上面的形式太复杂,其实不然,你只是需要时间来适应这种简练的表达方式。
那么,我们需要实现的代码就可以这样写了:
final long countFriendsStartN = friends.stream().filter(startsWithLetter.apply("N")).count();
final long countFriendsStartB = friends.stream().filter(startsWithLetter.apply("B")).count();
使用startsWithLetter.apply("N")的结果是得到了Lambda表达式,它作为参数被传入到了filter方法中。剩下的事情,就和之前的代码一样了。
Predicate和Function
目前,已经出现了两种类型的函数式接口(Functional Interface)。它们分别是filter方法使用的Predicate和map方法使用的Function。其实从Java 8的源代码来看,它们的概念实际上是相当简单的:
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
// others...
}
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
// others...
}
Predicate可以看做是Function的一个特例,即Function代表的就是Predicate。
挑选元素
比如,当我们需要打印出集合中第一个以某字母开头的元素时,最“自然”的实现如下:
public static void pickName(
final List<String> names, final String startingLetter) {
String foundName = null;
for(String name : names) {
if(name.startsWith(startingLetter)) {
foundName = name;
break;
}
}
System.out.print(String.format("A name starting with %s: ", startingLetter));
if(foundName != null) {
System.out.println(foundName);
} else {
System.out.println("No name found");
}
}
虽然是最“自然”的实现方式,但是它太太太丑陋了。从将foundName设置成null开始,这段代码充斥着一些代码的“坏味道”。正因为变量被设置成了null,为了避免臭名昭著的NullPointerException,我们必须在使用它之前进行空检查。除此之外,声明了可变变量,使用了冗长的外部遍历,没有尽量实现不可变性也是这段代码具有的问题。
然而,任务本身是很简单的。我们只是想打印集合中第一个符合某种条件的元素而已。
这次,使用Lambda表达式来实现:
public static void pickName(
final List<String> names, final String startingLetter) {
final Optional<String> foundName = names.stream()
.filter(name ->name.startsWith(startingLetter))
.findFirst();
System.out.println(String.format("A name starting with %s: %s", startingLetter, foundName.orElse("No name found")));
}
以上代码出现了几个新概念: 在调用filter后,调用了findFirst方法(找到符合条件的第一个元素),这个方法返回的对象类型时Optional。关于这个Optional,可以将它理解成一个可能存在,也可能不存在的结果。这样的话,就可以避免对返回结果进行空检查了。对于结果是否真的存在,可以使用isPresent()方法进行判断,而get()方法用于尝试对结果的获取。当结果不存在时,我们也可以使用orElse()来指定一个替代结果,正如上面使用的那样。
另外,当结果存在时,通过使用ifPresent方法也可以运行某一段代码,运行的代码可以通过Lambda表达式声明:
foundName.ifPresent(name -> System.out.println("Hello " + name));
但是,对于使用Lambda表达式实现的pickName方法,它做的工作是否会比命令式的实现方式更多呢?因为可以发现,在命令式实现中,当我们发现了第一个符号条件的元素之后,for循环会被立即终止。而findFirst是否也会执行类型的操作,当发现第一个符号条件的元素后,及时中断剩下的操作呢?答案是肯定的,关于这一点会在后面的文章中会进行介绍。
集合归约
和前面的种种操作不同,对于集合的归约(Collection Reduction),元素与元素不再是独立的,它们会通过某种归约操作联系在一起。
比如得到名字集合的总字符数,就是一种典型的求和归约。可以实现如下:
System.out.println("Total number of characters in all names: " +
friends.stream()
.mapToInt(name -> name.length())
.sum());
通过stream实例的mapToInt方法,我们可以很方便地将一个字符串集合转换成一个整型数集合。然后调用sum方法得到整型数集合的和值。这里有一些实现细节,比如mapToInt方法得到的是一个Stream类型的子类型IntStream的实例,sum方法就是定义在IntStream类型之上。与IntStream类似,还有LongStream和DoubleStream类型,这些类型的存在是为了提供一些类型相关的操作,让代码调用更简洁。
比如,和sum()方法类似地,还有max(),min(),average()等一系列方法用来实现常用的归约。
//计算 count, min, max, sum, and average for numbers
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
IntSummaryStatistics stats = numbers
.stream()
.mapToInt((x) -> x)
.summaryStatistics();
System.out.println("List中最大的数字 : " + stats.getMax());
System.out.println("List中最小的数字 : " + stats.getMin());
System.out.println("所有数字的总和 : " + stats.getSum());
System.out.println("所有数字的平均值 : " + stats.getAverage());
但是归根到底,这些方法最终使用到的是一个叫做reduce()的方法。reduce方法的工作原理,可以这样概括:在对一个集合中的元素按照顺序进行两两操作时,根据某种策略来得到一个结果,得到的结果将作为一个元素参与到下一次操作中,最终这个集合会被归约成为一个结果。这个结果也就是reduce方法的返回值。
因此,当我们需要寻找并打印一个集合中最长的名字时(长度相同时,打印第一个),可以如下实现:
final Optional<String> aLongName = friends.stream()
.reduce((name1, name2) ->
name1.length() >= name2.length() ? name1 : name2);
aLongName.ifPresent(name -> System.out.println(String.format("A longest name: %s", name)));
我们来分析一下Lambda表达式:
(name1, name2) -> name1.length() >= name2.length() ? name1 : name2)
是不是符合我们概括的关于reduce方法的工作原理。
第一次执行两两操作时,name1和name2代表的是集合中的第一个和第二个元素,当第一个元素的长度大于等于第二个元素时,将第一个元素保留下来,否则保留第二个元素。 第二次执行两两操作时,name1代表的是上一次操作中被保留下来的拥有较长长度的元素,name2代表的是第三个元素。 以此类推...最后得到的结果就是集合中第一个拥有最长长度的元素了。
实际上,reduce方法接受的Lambda表达式的行为被抽象成了BinaryOperator接口:
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
// others...
}
@FunctionalInterface
public interface BiFunction<T, U, R> {
/**
* Applies this function to the given arguments.
*
* @param t the first function argument
* @param u the second function argument
* @return the function result
*/
R apply(T t, U u);
// others...
}
源码也反映了BinaryOperator和另一个函数式接口BiFunction之间的关系,当BiFunction接口中接受的三个参数类型一致时,也就成为了一个BinaryOperator接口。因此,前者实际上是后者的一个特例。
另外需要注意的几点:
- reduce方法返回的对象类型时Optional,这是因为待操作的集合可能是空的。
- 当集合只有一个元素时,reduce会立即将该元素作为实际结果以Optional类型返回,不会调用传入的Lambda表达式。
- reduce方法是会按照集合的顺序对其元素进行两两操作的,可以额外传入一个值作为“基础值”或者“默认值”,那么在第一次进行两两操作时,第一个操作对象就是这个额外传入的值,第二个操作对象是集合中的第一个元素。
比如,以下代码为reduce方法传入了默认值:
final String steveOrLonger =
friends.stream()
.reduce("Steve", (name1, name2) ->
name1.length() >= name2.length() ? name1 : name2);
元素连接
在过去,我们使用for循环来连接一个集合中的所有元素:
for(String name : friends) {
System.out.print(name + ", ");
}
System.out.println();
上述代码的问题是,在最后一个名字后面也出现了讨人厌的逗号!为了修复这个问题:
for(int i = 0; i < friends.size() - 1; i++) {
System.out.print(friends.get(i) + ", ");
}
if(friends.size() > 0)
System.out.println(friends.get(friends.size() - 1));
嗯,结果是正确了,但是你能忍受如此丑陋的代码吗?
为了解决这个非常非常常见的问题,Java 8中终于引入了一个StringJoiner类。 可以通过调用String类型的join方法完成这个操作:
System.out.println(String.join(", ", friends));
StringJoiner其实还能够对元素的连接操作进行更多的控制。比如为每个元素添加前缀,后缀然后再进行连接。具体的使用方法可以去参考API文档。
当然,使用reduce方法也能够完成对于集合元素的连接操作,毕竟集合元素的连接也是一种归约。只不过,正如前面看到的那样,reduce方法太过于底层了。针对这个问题,Stream类型还定义了一个collect方法用来完成一些常见的归约操作:
System.out.println(friends.stream().map(String::toUpperCase).collect(Collectors.joining(", ")));
可见collect方法并不自己完成归约操作,它会将归约操作委托给一个具体的Collector,而Collectors类型则是一个工具类,其中定义了许多常见的归约操作,比如上述的joining Collector
简单的基本操作
二、流的操作:
流的操作可以归结为几种:
1、遍历操作(map):
使用map操作可以遍历集合中的每个对象,并对其进行操作,map之后,用.collect(Collectors.toList())会得到操作后的集合。
1.1、遍历转换为大写:
List<String> output = wordList.stream().
map(String::toUpperCase).
collect(Collectors.toList());
1.2、平方数:
List<Integer> nums = Arrays.asList(1, 2, 3, 4);
List<Integer> squareNums = nums.stream().
map(n -> n * n).
collect(Collectors.toList());
2、过滤操作(filter):
使用filter可以对象Stream中进行过滤,通过测试的元素将会留下来生成一个新的Stream
List<Person> phpProgrammers = new ArrayList<Person>();
phpProgrammers.add(new Person("Jarrod", "Pace", "PHP programmer", "male", 34, 1550));
phpProgrammers.add(new Person("Clarette", "Cicely", "PHP programmer", "female", 23, 1200));
phpProgrammers.add(new Person("Victor", "Channing", "PHP programmer", "male", 32, 1600));
//根据自己的规则判断集合中是否存在某些数据
boolean isExits = phpProgrammers.stream().anyMatch(obj -> (obj.getFirstName().equals("Quinn") && obj.getLastName().equals("Tamara")));
System.out.println(isExits+"===isExits");
//根据自己的规则判断集合中是否存在某些数据添加到新的集合并打印
List<Person> lists = phpProgrammers.parallelStream().filter(php->(php.getFirstName().equals("Quinn") && php.getLastName().equals("Tamara")))
.collect(Collectors.toList());
lists.forEach(li->System.out.println(li.getFirstName()));
2.1、得到其中不为空的String
List<String> filterLists = new ArrayList<>();
filterLists.add("");
filterLists.add("a");
filterLists.add("b");
List afterFilterLists = filterLists.stream()
.filter(s -> !s.isEmpty())
.collect(Collectors.toList());
3、循环操作(forEach):
如果只是想对流中的每个对象进行一些自定义的操作,可以使用forEach:
List<String> forEachLists = new ArrayList<>();
forEachLists.add("a");
forEachLists.add("b");
forEachLists.add("c");
forEachLists.stream().forEach(s-> System.out.println(s));
4、返回特定的结果集合(limit/skip):
limit 返回 Stream 的前面 n 个元素;skip 则是扔掉前 n 个元素:
List<String> forEachLists = new ArrayList<>();
forEachLists.add("a");
forEachLists.add("b");
forEachLists.add("c");
forEachLists.add("d");
forEachLists.add("e");
forEachLists.add("f");
List<String> limitLists = forEachLists.stream().skip(2).limit(3).collect(Collectors.toList());
注意skip与limit是有顺序关系的,比如使用skip(2)会跳过集合的前两个,返回的为c、d、e、f,然后调用limit(3)会返回前3个,所以最后返回的c,d,e
5、排序(sort/min/max/distinct):
sort可以对集合中的所有元素进行排序。max,min可以寻找出流中最大或者最小的元素,而distinct可以寻找出不重复的元素:
5.1、对一个集合进行排序:
List<Integer> sortLists = new ArrayList<>();
sortLists.add(1);
sortLists.add(4);
sortLists.add(6);
sortLists.add(3);
sortLists.add(2);
List<Integer> afterSortLists = sortLists.stream().sorted((In1,In2)->
In1-In2).collect(Collectors.toList());
5.2、得到其中长度最大的元素:
List<String> maxLists = new ArrayList<>();
maxLists.add("a");
maxLists.add("b");
maxLists.add("c");
maxLists.add("d");
maxLists.add("e");
maxLists.add("f");
maxLists.add("hahaha");
int maxLength = maxLists.stream().mapToInt(s->s.length()).max().getAsInt();
System.out.println("字符串长度最长的长度为"+maxLength);
5.3、对一个集合进行查重:
List<String> distinctList = new ArrayList<>();
distinctList.add("a");
distinctList.add("a");
distinctList.add("c");
distinctList.add("d");
List<String> afterDistinctList = distinctList.stream().distinct().collect(Collectors.toList());
其中的distinct()方法能找出stream中元素equal(),即相同的元素,并将相同的去除,上述返回即为a,c,d。
6、匹配(Match方法):
有的时候,我们只需要判断集合中是否全部满足条件,或者判断集合中是否有满足条件的元素,这时候就可以使用match方法:
allMatch:Stream 中全部元素符合传入的 predicate,返回 true
anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
6.1、判断集合中没有有为‘c’的元素:
List<String> matchList = new ArrayList<>();
matchList.add("a");
matchList.add("a");
matchList.add("c");
matchList.add("d");
boolean isExits = matchList.stream().anyMatch(s -> s.equals("c"));
6.2、判断集合中是否全不为空:
List<String> matchList = new ArrayList<>();
matchList.add("a");
matchList.add("");
matchList.add("a");
matchList.add("c");
matchList.add("d");
boolean isNotEmpty = matchList.stream().noneMatch(s -> s.isEmpty());
则返回的为false
List<String> list1 = new ArrayList();
list1.add("1111");
list1.add("2222");
list1.add("3333");
List<String> list2 = new ArrayList();
list2.add("3333");
list2.add("qqqq");
list2.add("bbb33");
list2.add("qnnjnj");
list2.add("qhghgh");
// 交集
List<String> intersection = list1.parallelStream().filter(item -> list2.contains(item)).collect(toList());
System.out.println("---得到交集 intersection---");
intersection.parallelStream().forEach(System.out :: println);
// 差集 (list1 - list2)
List<String> reduce1 = list1.parallelStream().filter(item -> !list2.contains(item)).collect(toList());
System.out.println("---得到差集 reduce1 (list1 - list2)---");
reduce1.parallelStream().forEach(System.out :: println);
// 差集 (list2 - list1)
List<String> reduce2 = list2.parallelStream().filter(item -> !list1.contains(item)).collect(toList());
System.out.println("---得到差集 reduce2 (list2 - list1)---");
reduce2.parallelStream().forEach(System.out :: println);
// 并集
List<String> listAll = list1.parallelStream().collect(toList());
List<String> listAll2 = list2.parallelStream().collect(toList());
listAll.addAll(listAll2);
System.out.println("---得到并集 listAll---");
listAll.parallelStream().forEach(System.out :: println);
// 去重并集
List<String> listAllDistinct = listAll.stream().distinct().collect(toList());
System.out.println("---得到去重并集 listAllDistinct---");
listAllDistinct.parallelStream().forEach(System.out :: println);
System.out.println("---原来的List1---");
list1.parallelStream().forEach(System.out :: println);
System.out.println("---原来的List2---");
list2.parallelStream().forEach(System.out :: println);
map获取值为1得所有key
Set<String> strs = map.entrySet().stream().filter((e)->!Object.equals("1",e.getValue)).collect.(Collectors.toMap(Map.Entry::getKey,Map.Entry::getValue)).keySet();
获取元素的
https://blog.csdn.net/wangmuming/article/details/72743790
在这篇文章中,我们将向您展示如何使用java 8 Stream Collectors 对列表分组,计数,求和和排序。
今天使用lambda表达式处理集合时,发现对return、break以及continue的使用有点迷惑,于是自己动手测试了一下,才发现在使用foreach()处理集合时不能使用break和continue这两个方法,也就是说不能按照普通的for循环遍历集合时那样根据条件来中止遍历,而如果要实现在普通for循环中的效果时,可以使用return来达到,也就是说如果你在一个方法的lambda表达式中使用return时,这个方法是不会返回的,而只是执行下一次遍历,看如下的测试代码:
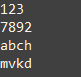
- List<String> list = Arrays.asList("123", "45634", "7892", "abch", "sdfhrthj", "mvkd");
- list.stream().forEach(e ->{
- if(e.length() >= 5){
- return;
- }
- System.out.println(e);
- });
上述代码的输出结果是如下图所示:
可以看出return起到的作用和continue是相同的。
想知道这是为什么,在Stack Overflow中找到一个答案,主要是说foreach()不是一个循环,不是设计为可以用break以及continue来中止的操作。
https://blog.csdn.net/abcwywht/article/details/77991868
https://blog.csdn.net/dm_vincent/article/details/40340291
本文基本来自这两个网站 对学习拉姆达的初学者很有用处 想升级自己的可以好好学学
https://mp.weixin.qq.com/s/G_QX7OcAqDfcAkD9fkN7Qw