一.jml语言
1.理论基础
JML作为Java的强大的契约式设计(DBC)工具。是Java的一个正式的行为接口规约语言,它包含了DBC中使用的基本符号作为子集。
契约式设计(DBC)是一种软件开发方法。DBC背后的主要思想是类和它的客户之间有一个"契约"。客户机在调用类定义的方法之前必须保证某些条件,作为回报,类保证在调用之后保持某些属性。使用这样的前置和后置条件来指定软件可以追溯到1969年Hoare关于形式验证的论文DBC的新颖之处在于它使这些合同可执行。契约由编程语言本身的程序代码定义,并由编译器转换成可执行代码。因此,可以立即检测到在程序运行时发生的任何违反协议的行为。
Jml使用一个requires子句来指定client的义务,使用ensures子句来指定implementor的义务,通常通过指定方法的前置和后置条件来编写契约。方法的前置条件说明了调用它必须是真实的。方法的后置条件说明它终止时什么必须为真。在支持异常的Java语言中,我们进一步区分正常后置条件和异常后置条件。方法的正常后置条件表示当它正常返回时必须为真,即没有抛出异常。JML还允许对方法可能抛出的异常进行说明。这可以通过使用JML的signalsonly子句来完成。
DBC更适合于文档化,而不仅仅是代码;甚至比使用非正式文档(如Javadoccomments)更好。DBC契约规范比代码更抽象;这在某种程度上是因为它不必给出详细的算法,但可以集中于假设的内容和必须实现的内容。与注释不同的是,JML中的形式规范文件是可检查的,因此可以帮助进行调试。也就是说,在错误传播过远之前,检查规范可以帮助隔离它们。此外,由于机械地检查了JML规范,它比非正式文档更有可能保持代码的最新。
2.相关工具
• JML 编译器(jmlc)是对Java 编译器将带有 JML 规范注释的 Java 程序编译成 Java 字节码。 编译的字节码包括检查的运行时断言检查指令。
•单元测试工具(jmlunit)将Jml 编译器与 JUnit(一个流行的单元测试工具)结合。 这个工具将程序员从编写测试用例用解放,使他们转而去写使用 JML 规范的测试工具,由 jmlc 处理,来决定被测试的代码是否有效适当Jml 规范,例如先决条件、正常和异常的后置条件以及不变量。
•文件产生器文档(jmldoc)生成包含 Javadoc 注释和任何 JML 规范的 HTML。 这便于将JML 规范公布在网上。
•扩展静态检查器(escjava2)可以找到在 Java 代码中可能出现的错误。 特别擅长寻找潜在的空指针异常和数组越界索引操作。 它使用 JML 注释来关闭它的警告、传播和检查 JML 规范。
•类型检查器(type checker,JML)是检查 JML 规范的另一个工具,如果程序员不需要编译代码。可以比Jmlc更快。
二.使用Solver工具检查
这里检测MyPath:


package pathmana; import java.math.BigInteger; import java.util.ArrayList; import java.util.HashSet; import java.util.Iterator; import com.oocourse.specs3.models.Path; public class MyPath implements Path { //@ public instance model non_null int[] nods; private ArrayList<Integer> nodes; private int disnodeInteger; private HashSet<Integer> nodeHashSet = null; private int hasInteger; private int size; public MyPath(int... nodeList) { // TODO Auto-generated constructor stub nodes = new ArrayList<Integer>(nodeList.length); for (int i = 0; i < nodeList.length; i++) { nodes.add(nodeList[i]); } hasInteger = nodes.hashCode(); size = nodes.size(); } @Override public Iterator<Integer> iterator() { // TODO Auto-generated method stub return nodes.iterator(); } @Override public int compareTo(Path o) { // TODO Auto-generated method stub int i = 0; if (size >= o.size()) { for (Integer integer : o) { int tmp = new BigInteger(nodes.get(i).toString()) .compareTo(new BigInteger(integer.toString())); if (tmp != 0) { return tmp; } i++; } return size - o.size(); } else { for (Integer integer : o) { int tmp = new BigInteger(nodes.get(i).toString()) .compareTo(new BigInteger(integer.toString())); if (tmp != 0) { return tmp; } i++; if (i == size) { break; } } return size - o.size(); } } //@ also //@ ensures esult == (exists int i; 0 <= i && i < nods.length; nods[i] == arg0); @Override public /*@pure@*/ boolean containsNode(int arg0) { // TODO Auto-generated method stub if (nodeHashSet == null) { nodeHashSet = new HashSet<Integer>(nodes); disnodeInteger = nodeHashSet.size(); } return nodeHashSet.contains(arg0); } /*@ also @ ensures esult == ( um_of int i, j; 0 <= i && i < j && j < nods.length;nods[i] != nods[j]); @*/ @Override public /*pure*/ int getDistinctNodeCount() { // TODO Auto-generated method stub if (nodeHashSet == null) { nodeHashSet = new HashSet<Integer>(nodes); disnodeInteger = nodeHashSet.size(); } return disnodeInteger; } /*@ also @ requires arg0 >= 0 && arg0 < size(); @ assignable othing; @ ensures esult == nods[arg0]; @*/ @Override public /*@pure@*/ int getNode(int arg0) { // TODO Auto-generated method stub return nodes.get(arg0); } //@ also //@ ensures esult == (nods.length >= 2); @Override public /*@pure@*/ boolean isValid() { // TODO Auto-generated method stub return size >= 2; } //@ also //@ ensures esult == nods.length; @Override public /*@pure@*/ int size() { // TODO Auto-generated method stub return size; } // TODO : IMPLEMENT @Override public int hashCode() { // TODO Auto-generated method stub return hasInteger; } /*@ also @ public normal_behavior @ requires obj != null && obj instanceof Path; @ assignable othing; @ ensures esult == (((MyPath) obj).size() == nods.length) && (forall int i; 0 <= i && i < nods.length; nods[i] == ((MyPath) obj).getNode(i)); @ also @ public normal_behavior @ requires obj == null || !(obj instanceof Path); @ assignable othing; @ ensures esult == false; @*/ @Override public boolean equals(Object obj) { // TODO Auto-generated method stub if (obj == null) { return false; } else if (obj instanceof Path) { Path tmp = (Path) obj; if (tmp.size() != size) { return false; } int i = 0; for (int integer : tmp) { if (integer != nodes.get(i)) { return false; } i++; } return true; } return false; } @Override public int getUnpleasantValue(int arg0) { // TODO Auto-generated method stub if (!containsNode(arg0)) { return 0; } return (int) Math.pow(4, (arg0 % 5 + 5) % 5); } }
首先检查JML语法
命令:
openjml.bat -cp specs-homework-md3-1.3-raw-jar-with-dependencies.jar -check MyPath.java

没有报错
然后进行形式化验证
命令:openjml.bat -cp specs-homework-md3-1.3-raw-jar-with-dependencies.jar -exec E:OpenJmlSolvers-windowsz3-4.7.1.exe -esc MyPath.java,只z3-4.7.1.exe一种工具可用,其他两个工具版本不兼容。

输出结果(部分):
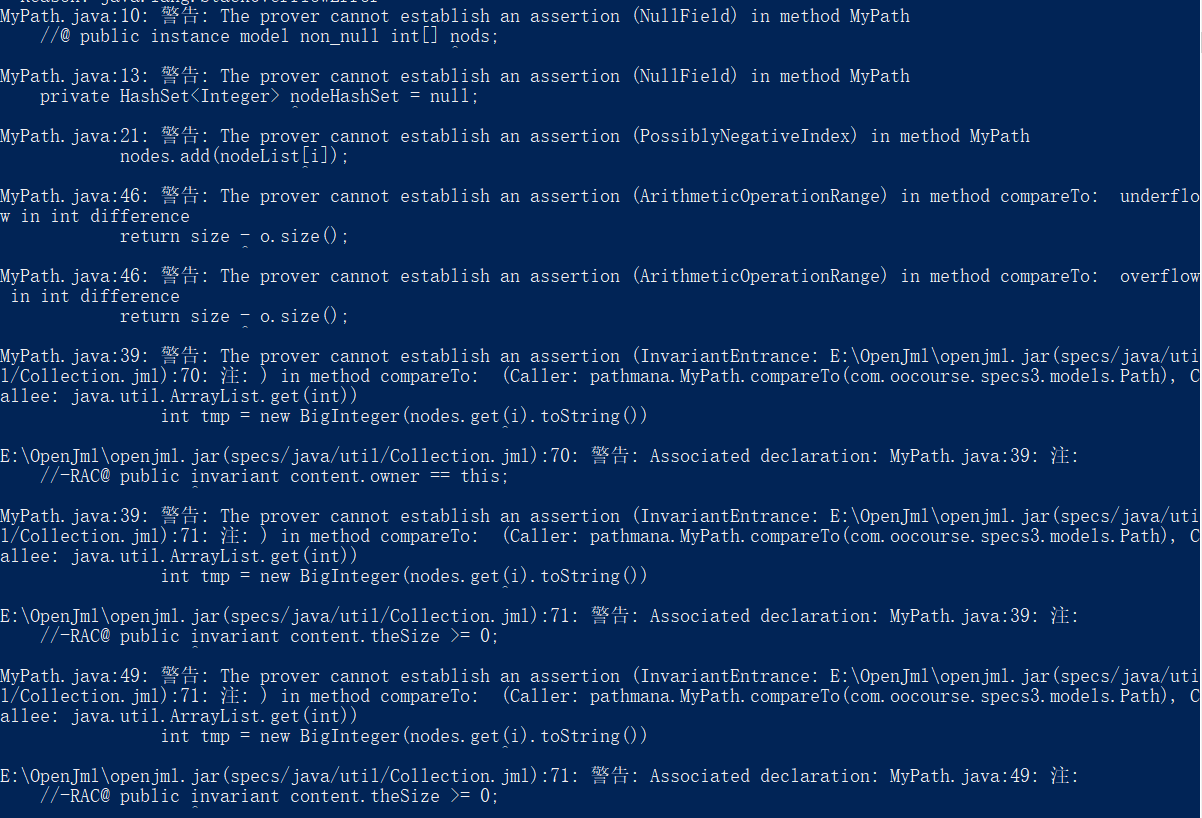
可以看到检测出了我程序中的不少潜在隐患,比如compare时大整数相减可能越界,我第二次强测因为这个吃了大亏,当时如果用了这个工具一定可以避免这种错误;再比如对于一些可能为null的对象我直接调用了其方法(当然在本次作业的MyPath类中我可以保证这个对象非空),这是不好的习惯,应该先判断返回值是否为null或者用trycatch方法。
三.部署JMLUnitNG/JMLUnit,生成测试用例
针对PathContainer接口生成测试用例(eclipse操作如下):
生成的测试用例:
package shy6; import com.oocourse.specs1.models.Path; import com.oocourse.specs1.models.PathContainer; import org.junit.After; import org.junit.Assert; import org.junit.Before; import org.junit.Test; public class MyPathContainerTest { private final PathContainer pathContainer = new MyPathContainer(); private Path path1, path2, path3; @Before public void before() { path1 = new MyPath(1, 2, 3, 4); path2 = new MyPath(1, 2, 3, 4); path3 = new MyPath(1, 2, 3, 4, 5); } @After public void after() { // do something here } @Test public void testAddPath() throws Exception { Assert.assertEquals(1, pathContainer.addPath(path1), 1); Assert.assertTrue(pathContainer.containsPathId(1)); Assert.assertEquals(path1, pathContainer.getPathById(1)); Assert.assertEquals(1, pathContainer.size()); Assert.assertEquals(1, pathContainer.addPath(path2)); Assert.assertTrue(pathContainer.containsPathId(1)); Assert.assertEquals(path2, pathContainer.getPathById(1)); Assert.assertEquals(1, pathContainer.size()); Assert.assertEquals(2, pathContainer.addPath(path3)); Assert.assertTrue(pathContainer.containsPathId(2)); Assert.assertEquals(path3, pathContainer.getPathById(2)); Assert.assertEquals(2, pathContainer.size()); } }
可以看到对添加路径、获取路径id、查询路径、打印容器size等方法都做了测试。
四.分析架构
我这三次的迭代设计还是有些问题的,所以每次更新作业都是手忙脚乱地修改。
第一次我没有将图的结构与计算专门提出来,也没有注意中间结果的利用,导致最后复杂度一塌糊涂。现在想想,各个路径都可能有交叉节点,况且还有统计全局相异节点个数这种函数,那时我就应该意识到应该维护一张全局的图,这样还能有助于利用中间节点。可惜我当时虽然往这里想了想,却觉得没必要(懒得)再开一个图结构,统计全局节点直接建一个集合遍历path就是(这也是我复杂度爆炸的原因)。
第二次作业发布后,激烈的思想斗争后,我意识到在不把全局的图建起来,我几乎都没法算最短路径了,这才另外开了一个类维护图。可是我仍然没有在程序的可扩展性上下功夫,我的图只是为了计算不带权的最短路径建立的,节点间只有相连信息,没有权值信息,最短路径算法也是宽度优先,这种架构在第二次作业是很顺手的,可惜第二次作业不是终点……
第三次作业公布,我又开始痛苦地重构,加权值、改算法,甚至还要拆点,总之第二次的程序几乎被改的面目全非,完全没有逐渐拓展的感觉。
反思自己,我总是少想一步,总是将程序设计得很适合于解决当前问题,却不能很好面对问题的扩展,这也可能和抽象能力不足有关,比如想到图,就应该想到带权图,毕竟权都为1的图在现实中应用场景还是太少。
五.代码及bug分析
第一次作业没有发现什么bug,但是算法不好,没有利用中间结果,复杂度高,另外对数组的字典序理解不到位,我直接把数组转为字符串字典序比较了,第一次作业只是实现了接口的方法,没有自行添加任何类。
第二次作业有两个严重bug,其一为偏序比较实现方法不严谨(两整数相减),导致异号大整数比较时加法溢出,比较结果错误;其二为忽略了同一条路径可能有重复节点,导致删路径时一个节点删了两遍,一个回收节点数组index的栈溢出。
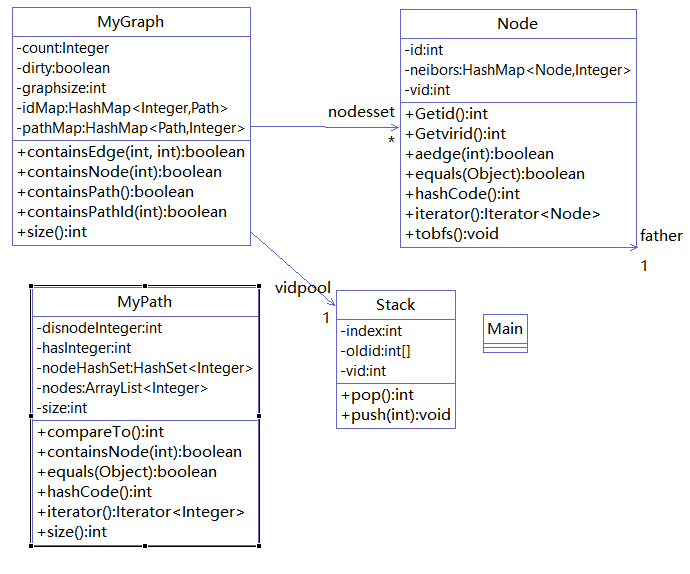
这次新添加了一个node类储存图结构及进行计算,用全局数组储存节点间最短路径(同一时刻节点数不超过250,所以我用256*256的数组储存距离),因此每个节点需要对应一个数组下标(我称为虚拟id,范围0——255),stack类就是回收和分配虚拟id。
第三次作业改得匆忙,bug较多,比如对自环的处理不当、加换乘代价时不能保证最短路径的中间也一定是最短路径、对扩展出的节点没有随图的更新而更新,到ddl还有两个中测没过。究其原因,一是架构不好,修改起来费时费力;二是算法选择较多,在这上面犹豫辗转多次不能从一而终;三是好高骛远没确保好程序正确性就去思考怎么优化、怎么存更多中间结果(因为当时觉得优化方法会影响数据结构及算法的选择,所以在重构前就开始寻找优化思路),最终大限之前力不从心,基础代码都没写好,谈何优化。痛定思痛,若时间充足,先都想明白胸有成竹再动手也不迟,可若时间紧迫,还是先着手基础功能,保证程序正确,循序渐进,否则就是赔了夫人又折兵。
这次添加了较多类,而且感觉抽象得并不好,为了方便染色及计算最小换乘次数,我又构建了以path为节点的图(两条path相连即连一条边),这个其实就是地铁图的简化版(储存信息少,最短路径计算只需要宽度优先),应该能作为地铁图的父类的,可是我却直接将地铁图的代码粘贴过来进行修改,现在想想,图的节点、图的边、图的最短路径计算都应该抽象出来作为接口或父类,这样程序也能更简单。
六. 规格撰写体会
说实话,一开始我是比较排斥规格的,因为刚接触,对其语法还不熟悉,觉得其比起自然语言太过繁琐,可读性不好还容易理解错。后来逐渐熟练语法,发现也慢慢接受和习惯了这种表达,虽然它乍看起来繁琐些,可是逻辑很严谨,也没有二义性,将自己每个函数要有什么执行前提、执行结果、何时报错讲得明明白白,这清晰的思路对代码的编写也有很大的帮助。再后来自己撰写规格,才意识到过去自己觉得它繁琐是因为许多高级语句没学到,只会用最基础的语句写规格,现在会的语句越来越多,感觉规格也越来越清晰和简洁,读写起来也不怎么头疼了。最后我了解到原来jml是可以被编译的(之前一直以为它只是特殊格式的注释),这就让我对它刮目相看了,这样它就可以精确地定位在哪个函数报了错,是哪个前置条件没满足报错,还是前置条件都满足了但输出不符合预期,这对debug绝对是莫大的帮助。
参考文献:
C. A. R. Hoare. An axiomatic basis for computer programming. Communications of the ACM, 12(10):576–583, October 1969.
http://www.jmlspecs.org/jmldbc.pdf