本文讨论python中的函数。主要内容如下:
函数的定义
函数的参数和函数的重载
函数的嵌套
函数的全局变量与局部变量
函数的递归
函数的作用域
匿名函数和lamda表达式
函数式编程
函数常见的内置函数
1.函数的定义
1 def test(): 2 print('这是我的第一个函数') 3 return 0 4 5 f=test 6 f1=test() 7 print(f) 8 print(f1)
函数一般包=包含两部分:函数的定义和函数的调用。上面的代码中1-3行定义了一个函数,后面几行是测试这个函数。首先看函数的定义。函数是用def关键字来标志的。函数的标准定义是:def 函数名(形参列表):第二行和第三行是这个函数的内容,其中第三行定义了函数的返回值。每一个函数都有一个返回值返回值的数据由return标志。函数执行了return语句之后,函数的内容中return后面的语句不会再执行,就像while循环中的break关键字,一旦执行了break,while循环就立马终止。函数一旦执行了return语句,函数调用立马结束。return语句后面的语句将不再执行。因此可以理解为函数是以return作为结束标志的,如果定义的函数没有return语句,那么python解释器会默认return None.
需要注意,python中,函数定以后,程序代码执行时,会把函数名作为一个变量存放在内存中,此时不会去执行函数体中语句,直到遇到函数的调用语句,此时才会去执行函数体中的内容。
第五行和第六行看似都是定义了一个变量来吧函数赋给这个变量,但这两个语句有着本质区别。上一段说过,在python中,会把定义的函数的函数名作为一个变量存放在内存中。因此第五句f=test相当于把函数作为一个变量赋予了f,此时f存放的是test函数在内存中存放的地址,这一条语句并不是调用该函数,因此函数体中的内容不会执行,用c语言来说,就是f是一个指向该函数的指针。而第六句f1=test(),这是一个标准的函数调用语句,变量f1接收的是函数return 语句返回的值。这句代码会执行函数体中的内容,并把return的值返回给f1,若没有return语句,则返回None.
2.函数的参数和函数的重载
函数的参数分为形参和实参,其中形参指的是在定义函数时()中的参数列表,实参指的是在调用函数时传给函数的参数,形参是一种抽象的意义,而实参则是我们在使用这个函数时传给函数的关键数据。
函数的形参分为三种形式:关键字参数,位置参数,参数组,下面分别来讨论。
(1)位置参数
def test(x,y,z): s=x+y+z #计算三个数的和 return s f1=test(1,2,3) print(f1)
位置参数是我们很熟悉的一种参数形式,无论在java还是在c中,形参都是可以这样表示的,只是会在参数前面加上数据类型。该例子的函数是实现三个数值的相加,x,y,z是函数的三个关键字参数,在调用该函数时,实参会传入1,2,3三个数字。因此在调用该函数后,形参的x=1,y=2,z=3.注意,形参和实参是一一对应的,因此在本例中,一定是x=1,y=2,z=3,而不会是其他的对应关系。这一点,在所有编程语言中都是如此。
(2)关键字参数
1 def test(x,y,z=2): 2 return x+y+z 3 4 s1=test(1,2) 5 s2=test(1,2,3) 6 print(s1) 7 print(s2)
关键字参数类似在c语言中很熟悉的缺省参数。关键字参数的定义形式是“z=2”,即给某些形参附上一个默认值。观察第4行和第5行的函数调用可以知道,对于有关键字参数的函数,一般有多种调用方式,第一种就是正常的给所有形参都传一个实参,就如第5行,这样的话,实参的值会覆盖掉定义函数时给关键字形参赋予的值。其他调用方式就是对于那些关键字形参,不传实参,这样函数在执行时,相应的关键字参数就会用其默认值来参与函数的计算。这个概念跟缺省参数类似。缺省参数的意思就是调用函数,传入实参时,这个函数的实参可传可不传,如果传了实参,就用实参参与函数的计算,如果没有传入实参,则用定义函数时给该缺省参数的默认值参与计算。
需要注意的是,关键字参数必须要在位置参数的后面,即不能这么定义:
1 def test(x,y=2,z):#错误,关键字参数不能在位置参数前面
(3)参数组 *代表列表,**代表字典
1 def test(x,*args): 2 print(x) 3 print(args) 4 def test1(x,**kwargs): 5 print(x) 6 print(kwargs) 7 test(1,*[2,'hekki',[12,43]]) 8 test(1,[2,'hekki',[12,43]]) 9 test(1,2,3,4,) 10 test1(1,**{'key':'value'})
列表参数组的形参一般用*args来表示,字典的的形参一般用**kwargs来表示。这里主要说明一下实参调用的方式,对于列表参数组,实参的调用方式比较灵活。第7,8,9行都可以表示为列表的调用方式,其中第7行在列表前面加了一个*,第8行没有加,这两种方式是一致的,第9行传了了多个实参,没有用列表表示,这样在调用时,会根据形参的分布情况,把多的实参合成一个列表。而对于字典的调用,则只能用第10行的形式进行调用,即用**标志实参是一个字典。
函数的重载指的是在定义函数时,可能会定义多个相同名字的函数,但是每一个函数的形参个数和形参形式不一致,这样在调用函数时,就可以利用实参传入的参数的个数和形式把不同的函数区分开。
3.函数的嵌套
1 def test1(): 2 print('form test1') 3 def test2(): 4 print('form test2') 5 return 1 6 return 2 7 8 f=test1() 9 print(f)
函数的嵌套,意思就是在一个函数中定义了另外一个函数,请注意与在一个函数中调用另一个函数的区别。对于函数的嵌套,有一点需要记住,那就是python对于函数的处理是把函数作为一个变量存放在内存中,直到遇到该函数的调用语句,才会执行函数体中的语句。根据这一原则,简单分析一下上面的代码。
在上面的代码中,定义了一个函数test1(),并在test1中定义了一个test2()函数。然后我们在下面调用了test1()函数。现在分析调用test1()这个函数会发生的事情。前面说过,python是把函数作为一个变量存放在内存中的,直到遇到该函数的调用语句,才会执行函数体中的内容。因此在第8行调用test1()函数后,python解释器会返回存放该函数变量的地方,开始执行函数体中的内容。函数体中第一句会执行第2行,这一行会打印一条语句。打印完成后,继续向下执行第三行,这一行定义了一个新的函数test2(),根据前面说的,python会把函数当做一个变量存放在内存中,直到遇到该函数的调用语句才执行函数体中的内容,因此执行完第三行,python会把第三行的函数名字作为一个变量存放在内存中,然后跳过第4行和第5行的函数体内容,跳到了第六行的return语句。上文曾说过,函数遇到return语句,就会将return语句后面的数据作为函数的返回值,并结束该函数的调用。因此执行完第6行,test1()函数执行完成。程序转到第9行,继续执行。
通过上面的分析,我们可以总结,执行了第8行的语句后,发生了这几件事:第一,执行了第三行语句,向控制台打印出了‘form test1’这条语句,第二,把函数test2作为一个变量存放在了内存中,第三件事:将2作为函数的返回值赋给了变量f.因此这段代码的结果如图所示:

分析完上面的代码,我们发现一个问题就是函数test2中的内容并没有被执行,因为我们上面的程序并没有出现调用test2()的语句,因此python只是把test2()作为一个变量存放在内存中,那么现在的问题是要如何调用test2(),使这个程序能执行test2()中的代码呢?
这个问题有两个解决方案,第一个是在调用函数的部分加入一个调用test2()的语句,如下面的代码所示:
def test1(): print('form test1') def test2(): print('form test2') return 1 return 2 f=test1() f1=test2() print(f) print(f1)
我们希望这段代码能执行test2()语句,输出form test2,并把1赋值给f1,然后把f1打印出来,但是实际结果却是如下:

报错了。报错提示test2未定义。这是为什么呢?因为test2是定义在函数test1中的,他属于函数test1的局部变量,而我们上面的语句是调用的全局变量,因为局部变量的生命周期只在本语句块内,因此会报这个错。关于局部变量和全局变量的区别,下面马上就会讨论。现在先来看看第二种解决方案。
调用一个函数只有两种方式:在函数调用部分去调用和在函数定义的部分去调用。上面使用的是在函数调用部分调用,事实证明这种方案是不行的,那么就只剩下在函数定义的部分去调用了:
1 def test1(): 2 print('form test1') 3 def test2(): 4 print('form test2') 5 return 1 6 res=test2() 7 return res 8 9 f=test1() 10 print(f)
上面的代码,我们把test2函数的调用语句定义在了函数test1的内部,这样就相当于调用了局部变量,这样就不会有问题了,结果如图:
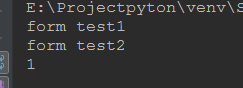
通过上面分析可知,要想实现嵌套函数的调用,必须在定义的函数内部去调用,不能在函数调用部分去调用。
4.函数的全局变量和局部变量
(1)全局变量与局部变量的区别
全局变量指的是这个变量的作用域是整个程序,而局部变量指的是这个变量的作用域只有某一特定的代码块,比如函数的形参就是一个局部变量,他的作用范围仅限于这个函数。
1 name='我是全局变量' 2 def test(): 3 name='我是局部变量' 4 print('test函数中输出name:%s' % name) 5 return 0 6 7 test() 8 print("在函数外面输出name:%s" % name)
上面的代码定义了两个name变量,第一行的name变量是一个全局变量,因为它不存在于任何代码块中,他是一个相对独立的成分,第3行也定义了一个name变量,但是因为该变量是定义在test函数内部中的,因此它属于test函数的局部变量。通过上面的分析,可以简单的总结为,任何局部变量,都必然要依附于某一个代码块(函数,for循环,while循环,if语句,类),而全局变量则依附于任何代码块,他在程序中相对独立,与这些代码块是处于同一个层级。因为python是一个严格控制缩进的语言,正好可以借助这一特性帮我们分析代码的层级关系,然后通过层级关系来判断局部变量和全局变量。
明白了全局变量和局部变量的区别,下面来分析如果存在全局变量和局部变量同名,那么该如何取值的问题。对于这个问题,记住一个原则,一条代码语句如果需要使用某一个变量的值,那么它会首先在同一级找,如果在同一级内找到了这个变量,那么就使用这个变量,如果同一层级没有这个变量,那么就会向上一层级找,如果上一层级找到了该变量,就用该变量的值,如果上一层没有,就再往上找。也就是最近原则。因此如果在一个程序中,存在全局变量和局部变量同名的情况,那么会优先寻找局部变量,如果局部变量不存在,再去找上一层的变量。
上面的代码执行结果如图:

因为在函数test内部定义了局部变量,因此第四行使用的name是局部变量name,而因为局部变量的作用域只限于他所处的层级,第8行的代码的层级是和函数定义同一层级(函数体的层级比函数定义层级低一个层级),因此第8行调用的是全局变量name。
(2)global关键字
前面讲过,局部变量的作用域仅限于其申明的代码块中。代码块中针对该变量的所有操作都是对局部变量进行的,那么现在有一个问题是,有没有办法在代码块中对全局变量进行操作呢?答案是肯定的,只需要使用global关键字声明该变量是全局变量即可:
1 name='我是全局变量' 2 def test(): 3 global name 4 name='猜猜我是谁' 5 print('test函数中输出name:%s' % name) 6 return 0 7 8 test() 9 print("在函数外面输出name:%s" % name)
上面的代码首先定义了一个全局变量,然后在函数的定义中,用global关键字表明了在函数中会对全局变量进行操作。如果没有第三行代码,那么第四行就相当于定义了一个局部变量,这样的话就无法做到改变全局变量。因为在4行改变了全局变量的值,因此第九行的输出和第5行相同:

需要注意,在代码块中如果使用global关键字表明全局变量,那么在global关键字之前就不能再定义同名的局部变量,如果定义了,则会出现全局变量与局部变量冲突,就会报错:
1 name='我是全局变量' 2 def test(): 3 name='ja' #不能在global关键字之前定义同名的局部变量,系统会报错 4 global name 5 name='猜猜我是谁' 6 print('test函数中输出name:%s' % name) 7 return 0 8 9 test() 10 print("在函数外面输出name:%s" % name)
(3)全局变量与局部变量命名规则
前面讨论了局部变量和全局变量的作用域问题,并讨论了局部变量和全局变量同名该如何区分的问题。但是在实际开发中,一般不会存在全局变量和局部变量同名的情形。在实际开发中,为了更好的区分全局变量和局部变量,一般用大写表示全局变量,小写表示局部变量。
5函数的递归
函数的递归,即函数自己调用自己下面仅通过一个简单的例子说明递归的形式,具体讨论后续讨论数据结构系列时在细论
1 def cal(n): 2 print(n) 3 if int(n/2)==0: 4 return n 5 else: 6 return cal(int(n/2)) 7 l=cal(10) 8 print(l)
在上面代码中,第6行出现了函数自己调用自己,这便是递归。写一个递归函数需要注意两点:第一:递归函数必须有明确的结束递归的条件,没有这个条件,递归就会一直执行下去,直到系统崩溃,第二:每一次递归后,问题的规模应该是逐渐减少的。
6函数的作用域和高阶函数
1 def foo(): 2 name='foo1' 3 print('from foo %s' %name) 4 def bar(): 5 name='badd' 6 print('from bar %s' % name) 7 return bar 8 9 f=foo() #调用foo函数,返回bar函数在内存中的地址,把该地址赋给变量f 10 print(f) 11 s=f() #调用bar函数 12 print(s)
函数的作用域指的是函数的生命周期,前面说过在python中,是把函数当做一个变量存放在内存中,直到遇到该代码的调用语句才会执行。前面也说过,对于嵌套函数,要想执行嵌套函数的函数体,必须在函数定义里面调用,那么有没有一种办法可以在全局调用嵌套函数呢?答案是肯定的,上述的代码就实现了在全局调用嵌套函数bar.之所以能这样实现,关键在于第7行的return 语句。因为此处的return语句返回的不是一个常规的数据,而是一个函数。即定义的函数的返回值也是一个函数。如果一个函数返回的是另外一个函数,那么我们就可以使用变量来接收这个函数,然后再加上括号就可以调用该函数了。
对于这种返回值也是一个函数的函数,我们称为高阶函数。高阶函数的定义是:如果一个函数的形参或者返回值是函数,那么这样的函数就称为高阶函数。
7 匿名函数和lambda表达式
匿名函数,即没有函数名的函数,在python中,要实现匿名函数,需要借助lambda表达式。首先来看一段代码:
1 def cal(x): 2 return x+1 3 4 res=cal(10) 5 print(res)
这是一个简单的使传入的参数值加一的函数,这个函数如果用匿名函数来改写,可以写成如下的形式:
1 res=lambda x:x+1 2 print(res(10))
在这段代码中,第一行的代码就代替了cal函数,这段代码执行效果跟上面的代码执行效果一致。通过这两段代码可以看出,使用匿名函数更加简洁,而且匿名函数一般是配合其他函数使用,这样就免去了为函数专门定义一个变量,使得内存占用更少。下面来分析lambda表达式的写法。
在lambda x:x+1这句代码中,lambda是关键字,表明后面的语句是一条lambda表达式后面x:x+1是lambda的内容。这个表达式用:分隔成了两部分,前面部分x是参数,相当于定义函数的形参,后面部分是返回对该参数的操作,相当于函数中的return语句。因此lambda的意义就是,根据:前面的形参执行:后面的运算,并把该运算结果作为lambda的返回值。因为函数的参数可以有多个,因此在lambda表达式中,:前面的参数部分可以有多个参数,但是:后面的返回语句则只能有一条,因为一个函数只会有一个最终的返回值。
8函数式编程
函数式编程同面向对象编程,面向过程编程一样,是一种比较重要的编程思想,此处先略过,后面会开辟专章来讨论这三种编程思想的区别。
9python常见的内置函数
(1)map,reduce,filter函数
a map函数
在讨论map函数之前,先看一个简单的问题:将列表l=[1,2,3,4,5,6]中的每一个元素的值加1。这个问题的解决方案很简单,只需要几行代码就可以实现:
1 l=[1,2,3,4,5,6] 2 ret=[] 3 for i in l: 4 ret.append(i+1) 5 print(ret)
上面这个代码只能处理列表l,为了让这段代码复用性更高,能处理更多的列表,现在我们将这段代码改成函数的形式,这样就可以处理其他列表了:
1 def map_test(array): 2 ret=[] 3 for i in array: 4 ret.append(i+1) 5 return ret 6 li=[1,2,3,4,5,6] 7 s=map_test(li) 8 print(s) 9 print(li)
通过定义函数,现在这段代码就可以处理所有的列表元素加1的操作了。那么现在新增一个需求,上面的代码只能处理将列表元素加1的操作,我现在需要新增一个可以把所有元素减一的操作。针对这个问题,最直观的想法就是在map_test中添加代码。但是这样有一个问题就是,如果后续还需要有新的操作需求就意味着每一次都要在,map_test中添加新的代码。这样做存在两个问题:第一个问题,在实际开发中,一般是不会去动已经写好的代码,因为这样动可能会对其他地方造成影响。第二个:这样不断的向一个函数中添加代码,就会使一个函数变得很臃肿,这就有违函数应该简洁,一个函数解决某一个特定问题的特性了。因此为了能让这个函数处理其他的操作(比如将列表每个元素减一),我们可以考虑将这些操作作为一个参数传入map_test中,这样以后添加新的操作就不用去动map_test的内部操作了。这样就提高了程序的可扩展性:
1 def add_one(x): 2 return x+1 3 4 def redecu_one(x): 5 return x-1 6 7 def map_test(fun,array): 8 ret=[] 9 for i in array: 10 res=fun(i) 11 ret.append(res) 12 return ret
在这段代码中,我们将map_test函数的形参改为了传入一个函数和一个列表,这样就可以处理对任意列表的任意操作了。如果以后还需要添加其他操作,只需要在外面再定义其他操作的实现函数就好,然后传入map_test中即可。
因为map_test在python中经常会使用到,因此python就将其封装为python的内置函数——map().map函数的实现原理就是map_test的代码。
1 l1=map(add_one,l) 2 print(list(l1))
第一行的代码就实现了map_test的操作。现在来分析map函数的参数,第一个参数传入的是一个操作方法(函数),第二个是需要处理的数据集。map函数会针对传入的数据集中的元素逐一用操作方法去处理。map函数的返回值是一个内存地址,如果要输出,需要指明输出的形式。
因为map函数的第一参数是一个函数,因此我们可以把lambda表达式作为参数传入:
1 l1=map(add_one,l) 2 l2=map(lambda x:x+1,l) 3 print(list(l1)) 4 print(list(l2))
lambda表达式的效果与add_one的效果一致,这样我们就可以不用特意去声明一个函数,这对于大型项目是很能提高效率的。
b.reduce函数
同样,通过一个简单的例子开始对reduce函数的讨论。现在有一个需求:需要求一个列表中的元素的和。为了日后方便对程序进行扩展,现在将这个功能写为函数形式:
1 li=[1,2,3,4,5] 2 def reduce_test(array): 3 s=0 4 for i in array: 5 s=s+i 6 return s 7 res=reduce_test(li) 8 print(res)
这段代码很容易实现了上述的需求,现在就要开始加需求了,现在需要新增一个求列表中所有元素的积的操作。为了更好的拓展该函数的功能,现在需要把这些操作以函数的形式传给reduce_test函数。
1 li=[1,2,3,4,5] 2 def add_one(x,y): 3 return x+y 4 def reduce_test(fun,array): 5 s=0 6 for i in array: 7 s=fun(s,i) 8 return s 9 res=reduce_test(add_one,li) 10 print(res)
这段代码也可以用lambda表达式来改写:
1 li=[1,2,3,4,5] 2 def reduce_test(fun,array): 3 s=0 4 for i in array: 5 s=fun(s,i) 6 return s 7 res=reduce_test(lambda x,y:x+y,li) 8 print(res)
现在来考虑另外一个问题,我们之前的计算都是默认给s赋了一个初值,但是在实际开发中,这样并不妥当,初始值应该由用户来提供,如果用户不提供初值,那么就使用列表中的第一个元素,这样可以使代码可用性更高,因为如果是我们给s赋初值,那么对于加法,我们要赋0,而对于乘法则需要赋1,这样就使得程序代码在处理不同的操作时发生冲突,因此为了使程序兼容性更好,现在对初始值做一下改动,以列表第一个元素作为初始值,如果用户有指定初始值,则以用户指定的值作为初始值:
1 li=[1,2,3,4,5] 2 def reduce_test(fun,array,init=None):#指定关键字参数,该参数作为用户输入的初始值 3 if init==None: 4 s=array.pop(0) #如果没有指定初始值,则取出列表的第一个元素,作为s的初始值 5 else: 6 s=init 7 for i in array: 8 s=fun(s,i) 9 return s 10 res=reduce_test(lambda x,y:x+y,li,10) 11 print(res)
上面的reduce_test函数就是python内置函数reduce函数的实现原理,即:
1 from functools import reduce #reduce函数需要从functools中导入 2 li=[1,2,3,4,5] 3 def reduce_test(fun,array,init=None):#指定关键字参数,该参数作为用户输入的初始值 4 if init==None: 5 s=array.pop(0) #如果没有指定初始值,则取出列表的第一个元素,作为s的初始值 6 else: 7 s=init 8 for i in array: 9 s=fun(s,i) 10 return s 11 res=reduce_test(lambda x,y:x+y,li,10) 12 print(res) 13 res1=reduce(lambda x,y:x+y,li,10) #reduce函数执行结果与reduce_test执行结果相同 14 print(res1)
需要注意,reduce函数是定义在functools模块中定义,因此需要从functools模块导入。
c.filter函数
同样,以一个例子开始,现在有一个列表li=['sb_ha','sb_he','sb_ni','zhengchangren'],要求将这个列表中所有以'sb'开头的元素过滤掉。这个需求很容易做到,用一个简单的函数就可以完成:
1 li=['sb_ha','sb_he','sb_ni','zhengchangren'] 2 def filter_test(array): 3 res=[] 4 for i in li: 5 if not i.startswith('sb'): 6 res.append(i) 7 return res 8 9 print(list(filter_test(li)))
现在要对这个函数进行扩展了,要它不但能实现过滤掉以sb开头的,还可以过滤掉以sb结束的,而且后面还可能会增加其他需求,为了满足这样的需求,现在把这些操作作为函数传给filter_test.
1 li=['sb_ha','sb_he','sb_ni','zhengchangren'] 2 def start_with(x): 3 return x.startswith('sb') 4 def filter_test(func,array): 5 res=[] 6 for i in li: 7 if not func(i): 8 res.append(i) 9 return res 10 11 s=filter_test(start_with,li) 12 print(list(s))
这样就成功完成了对该函数的扩展,上面的操作方法可以用lambda表达式来简化:
1 li=['sb_ha','sb_he','sb_ni','zhengchangren'] 2 3 def filter_test(func,array): 4 res=[] 5 for i in li: 6 if not func(i): 7 res.append(i) 8 return res 9 10 s=filter_test(lambda x:x.startswith('sb'),li) 11 print(list(s))
明白了上述代码的功能,就可以使用python内置的函数filter来代替filter_test函数了:
1 def filter_test(func,array): 2 res=[] 3 for i in li: 4 if not func(i): 5 res.append(i) 6 return res 7 8 s=filter_test(lambda x:x.startswith('sb'),li) 9 s1=filter(lambda x:not x.startswith('sb'),li) #filter函数的功能与filter_test的功能一致 10 print(list(s)) 11 print(list(s1))
这里需要注意,filter函数的作用是把符合条件的元素保留下来,因此如果是要删除掉符合条件的元素,需要在lambda表达式中加入not
d.三个函数的总结
map函数处理序列中的每一个元素,得到的结果是一个‘列表’,该列表元素个数及位置与原来序列一致,即map函数的处理结果不会改变序列的长度
reduce函数处理一个序列,然后把序列进行合并操作,reduce函数需要从functools模块中导入
filter遍历序列中的每个元素,判断每个元素得到一个布尔值,如果是True就将该元素保留下来
(2)abs:求绝对值
1 a=-1 2 b=abs(a) 3 print(b)
(3)all:判断序列中的每一个元素的bool值,如果所有元素的bool值都为true,则返回true,否则返回false
1 print(all([1,2,''])) 2 print(all([1,2,3])) 3 print(all([1,2,False]))
(4)bin,hex,oct十进制转为二进制,十六进制,八进制
1 print(bin(99)) #十进制转为二进制 2 print(oct(99)) #十进制转为八进制 3 print(hex(99)) #十进制转为十六进制
(5)bool:返回一个数据的布尔值,0,‘ ’空列表,元组,字典返回False,其他返回true
1 print(bool(0)) 2 print(bool('')) 3 print(bool([]))
(6)bytes:将字符串按照指定的编码方式转为字节
1 name='你好' 2 print(bytes(name,encoding='utf-8')) #encoding指定编码方式 3 print(bytes(name,encoding='utf-8').decode('utf-8')) #decode指定解码方式
(7)chr(int),ord(str)输出int在ASCII马中代表的字符,输出ASCII表中str的序号
print(chr(46)) #46在ASCII码中代表.
(8)dir(obj)输出obj类在pythin中的所有内置方法
1 print(dir(dict)) #输出dict(字典)的所有内置方法
(9)divmod(a,b)返回a除以b的商和余数,结果以元组形式展示
1 print(divmod(10,3)) #返回10除3的商和余数
(10)hash(a)求a的hash值
1 name='hah' 2 print(hash(name)) 3 name='hehh' 4 print(hash(name)) #重新定义了name变量,因此hash值会改变
hash函数的参数要求该变量可hash,前面说过,可hash代表着该变量是不可变的数据类型(包括数字,字符串,元组)。每一个变量一旦定义了变量值,就会有一个唯一的hash值与之对应。如果后面改变了该变量的值,相当于重新定义了一个变量,因此此时hash也会改变。
(11)isinstance(a,b)判断数据a是否是属于类型b,如果是返回True,否则返回False
1 print(isinstance(1,int)) #1是int类型,返回true 2 print(isinstance(1,str)) #1不是str,返回false 3 print(isinstance(1,list)) 4 print(isinstance(1,tuple)) 5 print(isinstance(1,dict))
(12)globals() locals()返回所有的全局变量,局部变量
(13)zip,max,min
a.zip(a,b):将序列a中的元素与序列b中的元素一一配对
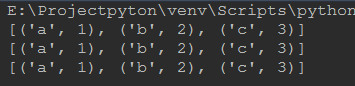
1 print(list(zip(('a','b','c'),(1,2,3)))) #将('a','b','c')与(1,2,3)一一配对 2 print(list(zip(('a','b','c'),(1,2,3,4)))) #如果两个元组中的元素不一致,则会从左往右一一配对,没有配对的元素丢掉 3 print(list(zip(('a','b','c','d'),(1,2,3))))
zip函数中的序列a和序列b的元素个数不一定要相等,如果有一个序列的的元素比另一个序列的元素个数多,那么zip会按照从左往右的顺序将两个序列的元素一一匹配,多余的元素自动舍弃。上述三行代码执行效果一样:
zip除了可以把两个序列的元素一一配对外,还可以将一个字典中的键值对进行一一配对:
1 p={'key1':'value1','key2':'value2','key3':'value3'} 2 print(list(zip((p.keys()),(p.values()))))
b.max(li):返回序列li中的最大值
1 p={'key1':'value1','key2':'value2','key3':'value3'} 2 print(list(zip((p.keys()),(p.values())))) 3 4 s=max(p) #默认比较的是字典的key值,返回的是字典中key值最大的键值对对应的key值,在本例中,返回key3 5 print(s)
在上面的例子中可以看到,如果序列是一个字典,那么默认是对字典的key值进行比较,但是在实际开发中,我们往往需要对字典的value值进行比较,当然,我们可以自己写代码来实现,但是如果借助zip函数,就可以很快的得出结果:
1 p={'key1':'value1','key2':'value2','key3':'value3'} 2 print(list(zip((p.keys()),(p.values())))) 3 4 s=max(p) #默认比较的是字典的key值,返回的是字典中key值最大的键值对对应的key值,在本例中,返回key3 5 print(s) 6 s1=list(max(zip((p.values()),(p.keys())))) #这样将返回value值最大的键值对并将value和key值以列表形式返回。返回值为['value3','key3'] 7 print(s1)
另外,max还可以通过关键字参数key来指定比较的方式:
1 p=[ #将字典元素作为列表的元素 2 {'name':'nihao','gender':'man','age':12}, 3 {'name':'hello','gender':'faman','age':34}, 4 {'name':'nihao','gender':'man','age':56}, 5 {'name':'nihao','gender':'man','age':45}, 6 {'name':'nihao','gender':'man','age':567}, 7 {'name':'nihao','gender':'man','age':4567}, 8 {'name':'nihao','gender':'man','age':909}, 9 {'name':'nihao','gender':'man','age':12789} 10 ] 11 res=max(p,key=lambda dic:dic['age'] ) #指定max比较的是字典的age关键字对应的value值 12 print(res)
注意,这种方式,需要将字典转为列表中元素
需要注意:不同类型的元素不可以进行比较,因此如果一个序列中含有不同的数据类型,则不同使用max
c.min(li)min函数返回序列li中的最小值,该函数用法与max一致
(14)pow(a,n,d=None)求a的n次幂:
1 s=pow(2,3) #求2的3次方 2 s1=pow(4,5,6) #先计算4的5次方,再求该值除以6的余数(求模) 3 print(s) 4 print(s1)
(15)round(a):四舍五入
1 s1=round(3.5) #返回4 2 s2=round(3.3) #返回3 3 print(s1, s2)
(16)slice(a,b,step=None)指定切片的范围,其中step用来指定切片的步长,即每取一个元素的间隔是多少.
1 l='helloword' 2 s1=slice(3,5) #指定切片范围是[3,5) 3 s2=slice(2,7,2) #指定切片范围是[2,7),并且是间隔2位取一位 4 print(l[3:5]) #返回lo 5 print(l[s1]) #返回lo 6 print(l[s2]) #返回loo 7 8 print(s2.start) #返回切片的开始位置 9 print(s2.step) #返回切片的步长 10 print(s2.stop) #返回切片的结束位置
(17)sorted()排序
1 li=[100,34,23,556,45,67,32,109,3] 2 li2=[19,'se',[12,54]] 3 print(sorted(li)) #将列表按升序排序 4 print(sorted(li,reverse=True)) #将列表按照降序排序 5 print(sorted(li2)) #错误,一个序列中存在不同的数据类型,不能进行排序
注意,排序的本质是比较大小,因此如果一个序列中含有不同的数据类型,则不能进行排序。此外,同max函数一样,对于字典,可以通过指定key参数来指明排序的标准:
1 p=[ #将字典元素作为列表的元素 2 {'name':'nihao','gender':'man','age':12}, 3 {'name':'hello','gender':'faman','age':34}, 4 {'name':'nihao','gender':'man','age':56}, 5 {'name':'nihao','gender':'man','age':45}, 6 {'name':'nihao','gender':'man','age':567}, 7 {'name':'nihao','gender':'man','age':4567}, 8 {'name':'nihao','gender':'man','age':909}, 9 {'name':'nihao','gender':'man','age':12789} 10 ] 11 print(list(sorted(p,key=lambda dic:dic['age'])))