垃圾收集器为垃圾收集算法的具体实现,是执行垃圾收集算法的,是守护线程。
HotSpot 虚拟机采用分代收集(JVM 规范并未对堆区进行划分),将堆分为年轻代和老年代,垃圾收集器也按照这样区分。不过已有通用垃圾收集器出现。
一、新生代垃圾收集器
Serial 垃圾收集器(单线程)
在垃圾收集过程中停止一切用户线程(Stop The World),适合客户端使用。
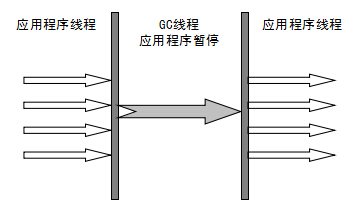
ParNew 垃圾收集器(多线程)
Serial 的多线程版本,但线程切换需要额外的开销,因此在单 CPU 环境中表现不如 Serial,清理过程依然需要 Stop The World。
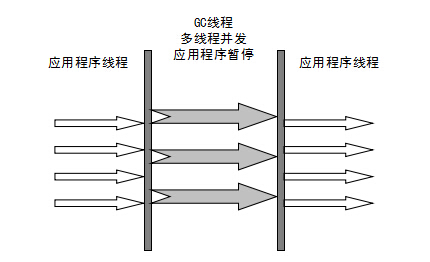
Parallel Scavenge 垃圾收集器(多线程)
Parallel Scavenge 和 ParNew 一样,都是多线程、新生代垃圾收集器。但是两者有巨大的不同点:
- Parallel Scavenge:追求 CPU 吞吐量,能够在较短时间内完成指定任务,因此适合没有交互的后台计算。
- ParNew:追求降低用户停顿时间,适合交互式应用。
吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)
二、老年代垃圾收集器
Serial Old 垃圾收集器(单线程)
Serial 的老年代版本,区别:Serial Old 工作在老年代,使用“标记-整理”算法;Serial 工作在新生代,使用“复制”算法。
Parallel Old 垃圾收集器(多线程)
Parallel Scavenge 的老年代版本,追求 CPU 吞吐量。
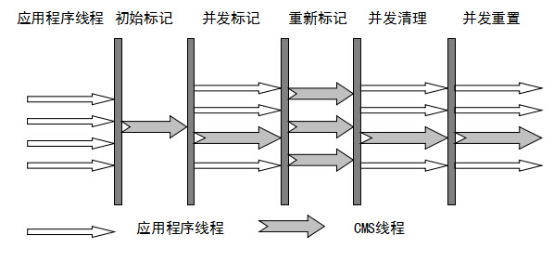
CMS 垃圾收集器
CMS(Concurrent Mark Sweep,并发标记清除)收集器是以获取最短回收停顿时间为目标的收集器(追求低停顿),它在垃圾收集时使得用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿。
三、G1 通用垃圾收集器
面向服务端应用的垃圾收集器,它没有新生代和老年代的概念,而是将堆划分为一块块独立的 Region。当要进行垃圾收集时,首先估计每个 Region 中垃圾的数量,每次都从垃圾回收价值最大的 Region 开始回收,因此可以获得最大的回收效率。
从整体上看, G1 是基于“标记-整理”算法实现的收集器,从局部(两个 Region 之间)上看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
四、相关命令
# 服务端与客户端查看 java -version

# 默认 GC 查看,显示出JVM初始化完毕后所有跟最初的默认值不同的参数及它们的值 java -XX:+PrintCommandLineFlags -version # java -XX:+PrintFlagsFinal -version | find ":"

| -XX:UseSerialGC | Client 模式的默认值,使用 Serial+Serial Old 收集器组合进行垃圾收集 |
| -XX:UseParNewGC | 使用 ParNew+Serial Old 收集器组合进行垃圾收集 |
| -XX:UseConcMarkSweepGC | 使用 ParNew+CMS+Serial Old 收集器组合进行垃圾收集。Serial Old 作为 CMS 收集器出现 Concurrent Mode Failure 的备用垃圾收集器 |
| -XX:UseParallelGC | Server 模式的默认值,使用 Parallel Scavenge+Serial Old 收集器组合进行垃圾收集 |
| -XX:UseParallelOldGC | 使用 Parallel Scavenge+Parallel Old 收集器组合进行垃圾收集 |
五、收集器组合情况

https://github.com/doocs/jvm/blob/master/docs/04-hotspot-gc.md