一、消息队列基本概念
1.消息队列概述
消息队列,一般我们会简称它为MQ(Message Queue),消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。目前使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ
消息队列可以简单理解为:把要传输的数据放在队列中。
把数据放到消息队列叫做生产者
从消息队列里边取数据叫做消费者
2.消息队列背景(举例)
周日玩手机,某东网APP突然蹦出来一条通知“为了回馈老客户,牛奶买一送一,活动仅限今天!”。买一送一还有这种好事,没忍住立马点了进去。立马买了两箱,下单、支付一气呵成!
第二天正常上着班,突然接到快递小哥的电话:
小哥:“你是xx吗?你的快递到了,我现在在你楼下,你来拿一下吧!”。
我:“这……我在上班呢,可以晚上送过来吗?“。
小哥:“晚上可不行哦,晚上我也下班了呢!”。
于是两个人僵持了很久……
最后小哥说,要不我帮你放到楼下便利店吧,你晚上下班了过来拿,尴尬的局面这才得以缓解!
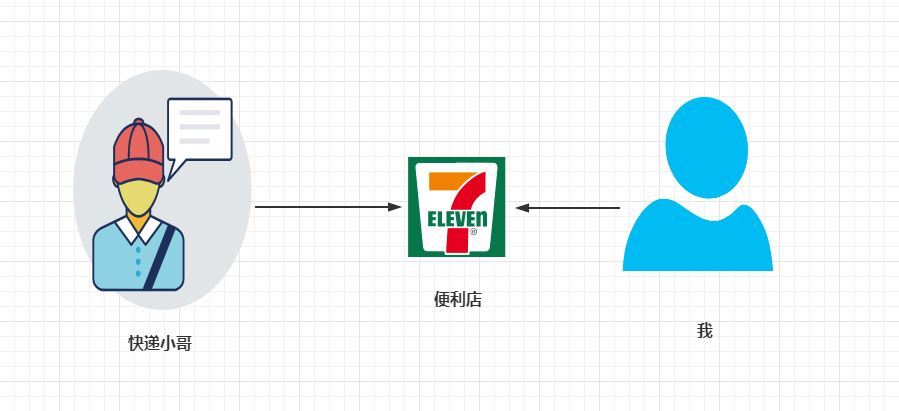
回到正题,如果没有便利店,那快递小哥和我的交互图就应该如下:

会出现什么情况呢?
1、为了这几箱牛奶,我请假回去拿,一天工资没了,还扣年假,血亏。
2、小哥一直在你楼下等,小哥还有其他的快递要送,也不可能等你的。
3、周末再送,等着喝牛奶呢,怎么可能。
4、这个牛奶我不要了,可能吗!
便利店出现后,交互图就应如下:
3.消息队列应用场景
在上面例子中,“快递小哥”和“我”就是需要交互的两个系统,便利店就是我们本文要讲的-“消息中间件”。总结下来小芳便利店(消息中间件)出现后有如下好处:
1、 解耦
快递小哥手上有很多快递需要送,他每次都需要先电话一一确认收货人是否有空、哪个时间段有空,然后再确定好送货的方案。这样完全依赖收货人了!如果快递一多,快递小哥估计的忙疯了……如果有了便利店,快递小哥只需要将同一个小区的快递放在同一个便利店,然后通知收货人来取货就可以了,这时候快递小哥和收货人就实现了解耦!
2、 异步
快递小哥打电话给我后需要一直在你楼下等着,直到我拿走你的快递他才能去送其他人的。快递小哥将快递放在小芳便利店后,又可以干其他的活儿去了,不需要等待你到来而一直处于等待状态。提高了工作的效率。
3、 削峰
假设双十一我买了不同店里的各种商品,而恰巧这些店发货的快递都不一样,有中通、圆通、申通、各种通等……更巧的是他们都同时到货了!中通的小哥打来电话叫我去北门取快递、圆通小哥叫我去南门、申通小哥叫我去东门。我一时手忙脚乱……
我们能看到在系统需要交互的场景中,使用消息队列中间件真的是好处多多,基于这种思路,就有了丰巢、菜鸟驿站等比便利店更专业的“中间件”了。
二、消息队列发展历程
实际上消息中间件的发展也是挺有意思的,我们知道任何一个技术的出现都是为了解决实际问题,这个 问题是 通过一种通用的软件总线也就是一种通信系统,解决应用程序之间繁重的信息通信工作。
最早的小白鼠就是金融交易领域,因为在当时这个领域中,交易员需要通过不同的终端完成交易,每台终端显示不同的信息。
如果接入消息总线,那么交易员只需要在一台终端上操作,然后订阅其他终端感兴趣 的消息。于是就诞生了发布订阅模型(pubsub),同时诞生了世界上第一个现代消息队列软件(TIB) The information Bus, TIB允许开发者建立一系列规则去描述消息内容,只要消息按照这些规则发布出 去,任何消费者应用都能订阅感兴趣的消息。
随着TIB带来的甜头被广泛应用在各大领域,IBM也开始研 究开发自己的消息中间件,3年后IBM的消息队列IBM MQ产品系列发布,之后的一段时间MQ系列进化 成了WebSphere MQ统治商业消息队列平台市场。
包括后期微软也研发了自己的消息队列(MSMQ)
各大厂商纷纷研究自己的MQ,但是他们是以商业化模式运营自己的MQ软件,商业MQ想要解决的是应用互通的问题,而不是创建标准接口来允许不同MQ产品互通。
三、消息队列通信的模式
通过上面的例子我们引出了消息中间件,并且介绍了消息队列出现后的好处,这里就需要介绍消息队列通信的两种模式了:
1.点对点模式
如上图所示,点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制。但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
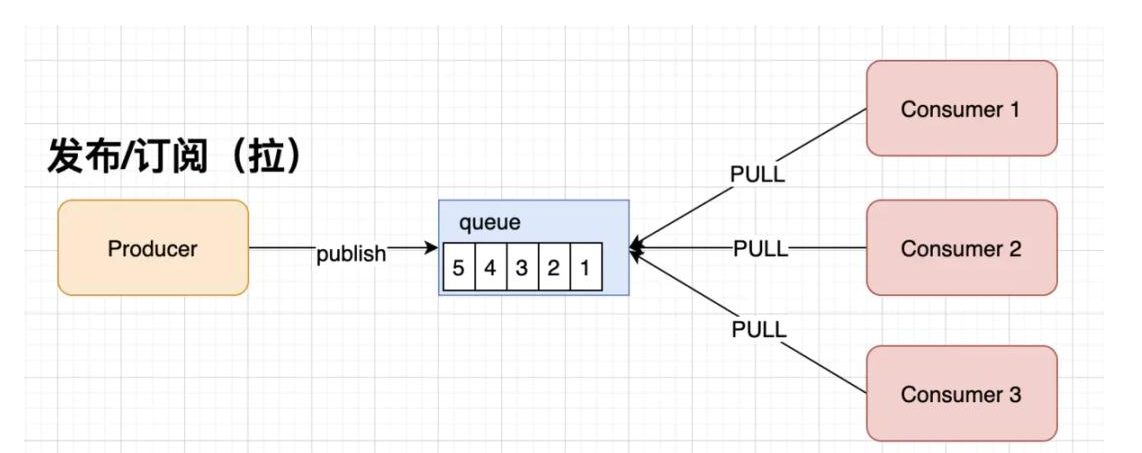
2. 发布订阅模式

如上图所示,发布订阅模式是一个基于消息送的消息传送模型,改模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,但消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!假设三个消费者处理速度分别是8M/s、5M/s、2M/s,如果队列推送的速度为5M/s,则consumer3无法承受!如果队列推送的速度为2M/s,则consumer1、consumer2会出现资源的极大浪费!
四、消息队列问题
经过我们上面的场景,我们已经可以发现,消息队列能做的事其实还是蛮多的。下面我们来看看要实现消息队列(中间件)可能要考虑什么问题。
1.高可用
无论是我们使用消息队列来做解耦、异步还是削峰,消息队列肯定不能是单机的。试着想一下,如果是单机的消息队列,万一这台机器挂了,那我们整个系统几乎就是不可用了。
所以,当我们项目中使用消息队列,都是得`集群/分布式`的。要做`集群/分布式`就必然希望该消息队列能够提供现成的支持,而不是自己写代码手动去实现。

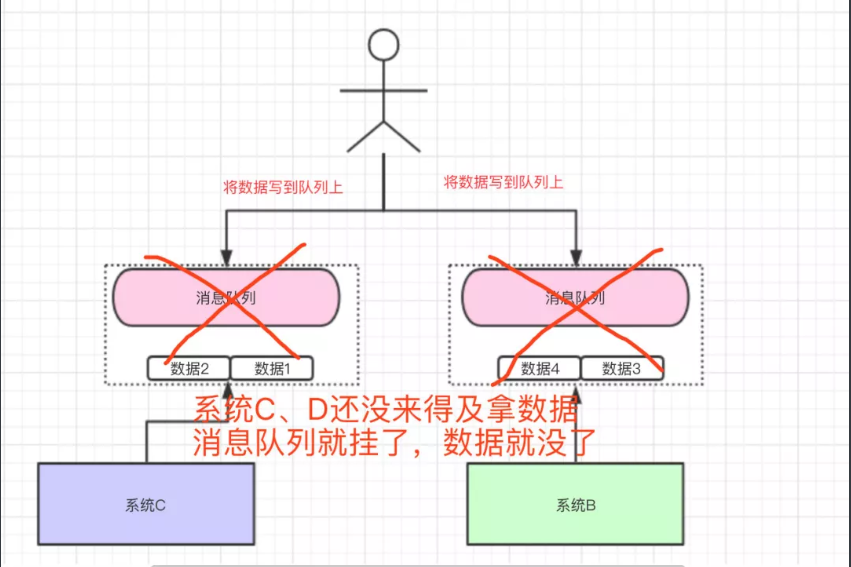
2 .数据丢失问题
我们将数据写到消息队列上,系统B和C还没来得及取消息队列的数据,就挂掉了。如果没有做任何的措施,我们的数据就丢了。
学过Redis的都知道,Redis可以将数据持久化磁盘上,万一Redis挂了,还能从磁盘从将数据恢复过来。同样地,消息队列中的数据也需要存在别的地方,这样才尽可能减少数据的丢失。
那存在哪呢?
- 磁盘?
- 数据库?
- Redis?
- 分布式文件系统?
同步存储还是异步存储?
3.消费者怎么得到数据
消费者怎么从消息队列里边得到数据?有两种办法:
- 生产者将数据放到消息队列中,消息队列有数据了,主动叫消费者去拿(俗称push)
- 消费者不断去轮询消息队列,看看有没有新的数据,如果有就消费(俗称pull)
4.其他
除了这些,我们在使用的时候还得考虑各种的问题:
- 消息重复消费了怎么办啊?
- 我想保证消息是绝对有顺序的怎么做?
- ...
虽然消息队列给我们带来了那么多的好处,但同时我们发现引入消息队列也会提高系统的复杂性。市面上现在已经有不少消息队列轮子了,每种消息队列都有自己的特点,选取哪种MQ还得好好斟酌。
五、主流消息队列中间件比较
目前在市面上比较主流的消息队列中间件主要有,Kafka、ActiveMQ、RabbitMQ、RocketMQ 等这几种。
ActiveMQ和RabbitMQ这两着因为吞吐量还有GitHub的社区活跃度的原因,在各大互联网公司都已经基本上绝迹了,业务体量一般的公司会是有在用的,但是越来越多的公司更青睐RocketMQ这样的消息中间件了。
Kafka和RocketMQ一直在各自擅长的领域发光发亮。

上图很明显就能看到差距了:
就拿吞吐量来说,早期比较活跃的ActiveMQ 和RabbitMQ基本上不是后两者的对手了,在现在这样大数据的年代吞吐量是真的很重要。比如现在突然爆发了一个超级热点新闻,你的APP注册用户高达亿数,你要想办法第一时间把突发全部推送到每个人手上,你没有大吞吐量的消息队列中间件用啥去推?再说这些用户大量涌进来看了你的新闻产生了一系列的附带流量,你怎么应对这些数据,很多场景离开消息队列基本上难以为继。就部署方式而言前两者也是大不如后面两个天然分布式架构的哥哥,都是高可用的分布式架构,而且数据多个副本的数据也能做到0丢失。
我们再聊一下RabbitMQ这个中间件其实还行,但是这玩意开发语言居然是erlang,我敢说绝大部分工程师肯定不会为了一个中间件去刻意学习一门语言的,开发维护成本你想都想不到,出个问题查都查半天。至于RocketMQ(阿里开源的),git活跃度还可以。基本上你push了自己的bug确认了有问题都有阿里大佬跟你试试解答并修复的,他的架构设计部分跟同样是阿里开源的一个RPC框架是真的很像(Dubbo)可能是因为师出同门的原因吧。
Kafka我放到最后说,你们也应该知道了,压轴的这是个大哥,大数据领域,公司的日志采集,实时计算等场景,都离不开他的身影,他基本上算得上是世界范围级别的消息队列标杆了。以上这些都只是一些我自己的个人意见,真正的选型还是要去深入研究的,不然那你公司一天UV就1000你告诉我你要去用Kafka我只能说你吃饱撑的。记住,没有最好的技术,只有最适合的技术,不要为了用而用。