三台机器分别命名为:
hadoop-master ip:192.168.0.25 hadoop-slave1 ip:192.168.0.26 hadoop-slave2 ip:192.168.0.27
部署前的基本准备:三台机器共同的用户hadoop,三台机器已经设置好静态ip且能互相ping通,三台机器的jdk已经安装好,路径最好一样。
大概流程:
1、修改主机名并在各个机器的/etc/hosts中相互添加ip和主机名
2、每台机器安装ssh,并实现master主机到slave主机无密码登录
3、hadoop安装和配置,记住路径要一样,最好都是/home/hadoop/xxxx
4、从master启动hadoop
一、修改主机名
1)设置静态ip,参照http://www.cnblogs.com/jhldreams/p/4161123.html
2)修改主机名
sudo gedit /etc/hostname (先修改hostname)
sudo gedit /etc/hosts (在hosts文档中加入相应ip和对应主机)
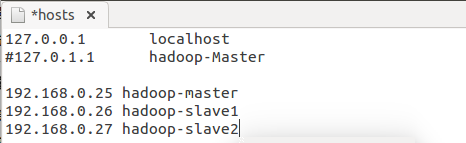
这个是master机器上面的hosts,在两个slave里面也是一样
有的时候修改了这两个你仍然会看到使用的命令行名字不是你修改的,可以su获取root权限,然后hostname xxxx,这样退出terminal后再次进入就会发现名字已经改过来了
二、安装ssh并设置免密码登录
sudo apt-get install ssh
安装完了后设置密码
$ssh-keygen -t rsa(执行完本条命令后一直回车) $cd .ssh (进入.ssh目录) $cp id_rsa.pub authorized_keys (到此处已经可以免密码登录本机,ssh localhost可测试) 以上每台机器都做一遍,不过需要master主机能够免密码登录slave主机,还需要将master的公钥复制到两个slave节点的公钥中去,在master上执行命令: $scp authorized_keys 从节点主机名@名字(如hadoop@hadoop-slave1):/home/hadoop/.ssh。 虽然公钥都弄好了,但是需要权限,你可以设置777权限,不过644权限就已经够了,在所有主机中将authorized)_keys文件的许可权限改为644 $chmod 644 authorized_keys 这时可以从master向slave主机发起ssh连接,需要输入yes的地方输入yes,可能第一次连接时候仍然需要输入一次密码。 以上实现了从master主机访问slave主机免密码登录问题
三、在所有机器安装hadoop并配置hadoop
我用的是hadoop-1.2.1版本
去官网下载hadoop-1.2.1的tar的包
$tar zxvf xxxx.tar.gz
我没用sudo解压,因为linux下的权限问题真的把我搞怕了,我的hadoop是安装在home文件下的,包括jdk的解压,都没用sudo
解压好之后,主要配置hadoop文件夹下conf中的hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml三个文件
hadoop-env.sh中主要找到JAVA_HOME那一行,去掉#号,并且把路径填写为自己的jdk路径
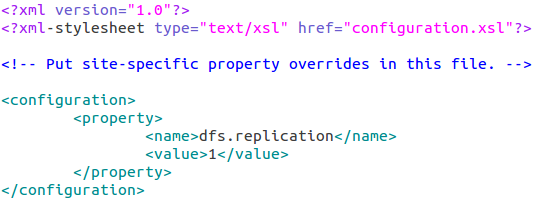
core-site.xml
配置hadoop.tmp.dir的原因是为了避免重复格式化hdfs文件系统,如果没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错
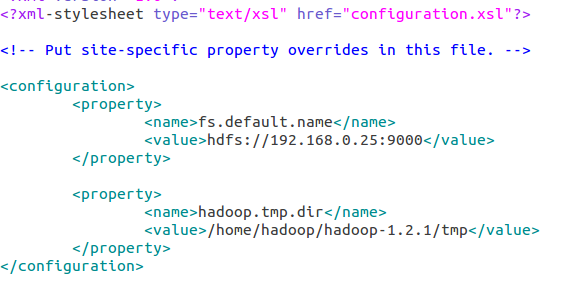
hdfs-site.xml
replication 是数据副本数量,默认为3,salve少于3台就会报错
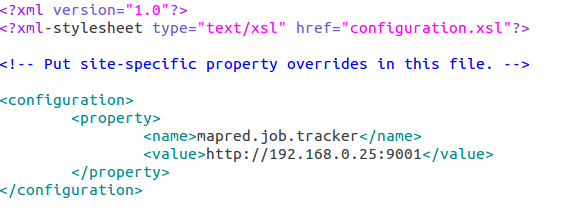
mapred-site.xml
以上做好后,开始在master主机上配置masters文件和slaves文件
$cd hadoop-1.2.1/conf $sudo gedit masters
修改内容为 当然也可以写成之前规定的静态ip192.168.0.25
当然也可以写成之前规定的静态ip192.168.0.25
配置slaves文件内容为:

到此位置,master主机上面的配置已经完成了,slave主机和此配置基本一样,可以直接从master主机拷贝hadoop文件夹过去(这样的话slave主机没必要提前下载hadoop)
$scp -r hadoop-1.2.1 hadoop@hadoop-slave1:/home/hadoop
slave2一样执行如此命令
四、启动
第一次启动需要格式化分布式文件系统,后来就不需要了
先进入到hadoop文件夹下 $cd hadoop-1.2.1 $bin/hadoop namenode -format(格式化)
启动
$cd hadoop-1.2.1 $bin/start-all.sh
可以用jps命令查看运行的进程情况
至此,hadoop完全分布式已经安装成功