一、排序实现
SELECT city,
name,
age
FROM t
WHERE city='杭州'
ORDER BY name LIMIT 1000 ;1.全字段排序
1.1排序过程
- 初始化sort_buffer, 确定放入city,name,age 字段
- 找到第一个city='杭州' 的主键
- 从主键找到整行,取name,city,age 三个字段,放入sort_buffer
- 从索引city中取下一个记录
- 重复3-4, 直到city取值不满足查询条件
- sort_buffer 中数据对name字段排序
- 取前1000行返回客户端
1.2临时文件
对name排序, 可以在内存中完成, 也可能需要使用外部排序, 取决于排序需要的内存和sort_buffer_size
sort_buffer_size 就是为排序开辟的空间,
1. 排序数据量< sort_buffer_size, 就在内存排序
2. 排序数据量>sort_buffer_size, 内存放不下,不得不利用磁盘临时文件辅助排序
如何确定一个排序语句是否使用到了临时文件
/* 打开 optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a 保存 Innodb_rows_read 的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`G
/* @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算 Innodb_rows_read 差值 */
select @b-@a;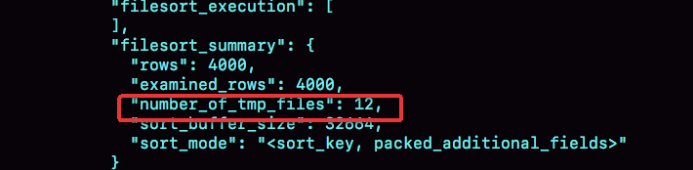
number_of_tmp_files 表示的是, 排序过程中,使用的临时文件数.
MySQL将排序数据分为了12份,每一份单独存储后存在这些临时文件中,然后把这12个有序文件再合并成一个有序的大文件
2. rowid 排序
上面的算法中, 对原表数据读了一遍, 剩下的操作都是在sort_buffer 和临时文件中.
存在一个问题, 查询需要返回的字段很多时, sort_buffer 中放的字段比较多,所以内存中同时放下的行数比较少,要分成很多个临时文件.
所以单行很大,效率不好, 影响算法的参数SET max_length_for_sort_data = 16;
控制排序行数据长度的参数, 单行长度超过这个值, 需要换个算法
city,name,age 三个字段的总长度是36, 将max_length_for_sort_data 设置为16, 放入sort_buffer 中的字段只有拍序列name 和主键id
流程:
- 初始化sort_buffer , 确定放入两个字段name,id
- 从索引city找到第一个满足city='杭州' 主键id
- 从主键访问,取name, ,将name id 放入sort_buffer
- 从索引city取下一个记录
- 重复3-4
- sort_buffer 对name排序
- 遍历排序结果,取前1000行, 回表访问city,name,age 返回客户端
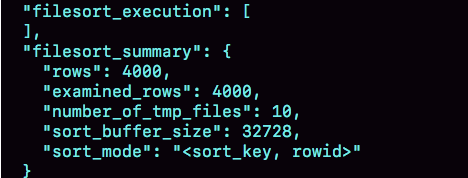
过程中有两次回表访问, examined_rows 是4000, 但是select @b-@a = 5000 ,访问成本4000+1000
sort_mode 变成 sort_key,rowid
number_of_tmp_file 变成10, 因为排序字段少了
3. 对比总结
MySQL 内存够用, 就多利用内存, 尽量减少磁盘访问.
排序成本高,甚至发生磁盘排序, 这是因为原来的数据都是无需的
alter table t add index city_user(city, name);
如果建立这样的索引, city='杭州'后 ,name还是有序的,查询过程:
- 从 city,name 取满足第一个city='杭州'主键id
- 从主键取name,city,age
- 从city索引取下一个
- 重复2-3 , 直到查询到第1000行结束, 或者不满足city='杭州'
这个过程中, 不需要临时表,也不需要排序
二、一个索引优化的case
语句和表结构
## SQL
SELECT *
FROM t_follow_timeline_099 force index (idx_uid_status)
WHERE UID = 1833901412800099
AND status = 1
ORDER BY create_time DESC
LIMIT 10
CREATE TABLE `t_follow_timeline_099` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT ,
`uid` bigint(20) NOT NULL DEFAULT '0' ,
`timeline_id` varchar(32) NOT NULL ,
`timeline_owner` bigint(20) NOT NULL DEFAULT '0' ,
`status` tinyint(4) NOT NULL DEFAULT '1' ,
`timeline_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ,
PRIMARY KEY (`id`),
KEY `idx_uid` (`uid`),
KEY `idx_create_time` (`create_time`),
KEY `idx_uid_timeline_owner` (`uid`,`timeline_owner`),
KEY `idx_uid_timeline_id` (`uid`,`timeline_id`),
KEY `idx_uid_create_time` (`uid`,`create_time`),
KEY `idx_uid_status` (`uid`,`status`)
) ENGINE=InnoDB AUTO_INCREMENT=1091861159388237825 DEFAULT CHARSET=utf8 第一页优化
## 第一页查询
mysql> explain SELECT *
-> FROM t_follow_timeline_099
-> force index (idx_uid_status)
-> WHERE UID = 1833901412800099
-> AND status = 1
-> ORDER BY create_time DESC
-> LIMIT 10;
+----+-------------+-----------------------+------------+------+----------------+----------------+---------+-------------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+------+----------------+----------------+---------+-------------+------+----------+---------------------------------------+
| 1 | SIMPLE | t_follow_timeline_099 | NULL | ref | idx_uid_status | idx_uid_status | 9 | const,const | 2875 | 100.00 | Using index condition; Using filesort |
+----+-------------+-----------------------+------------+------+----------------+----------------+---------+-------------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
# 执行时间
10 rows in set (0.02 sec)修改排序为order by id, 因为二级索引天然带主键,根据id排序直接返回
#修改成 order by id
SELECT *
FROM t_follow_timeline_099
force index (idx_uid_status)
WHERE UID = 1833901412800099
AND status = 1
ORDER BY id DESC
LIMIT 10
#查询耗时: 0.001135 秒去掉force index,出现与主键的merge

调整索引, 二级索引带上主键
mysql> alter table t_follow_timeline_099 add index idx_uid_status_id(`uid`,`status`,`id`) , drop index idx_uid_status;
Query OK, 0 rows affected (1 min 7.67 sec)
Records: 0 Duplicates: 0 Warnings: 0翻页查询 通过id实现
mysql> explain SELECT * FROM t_follow_timeline_099 WHERE UID = 1833901412800099 AND status = 1 and id < 1090943061166186580 ORDER BY id DESC LIMIT 10;
+----+-------------+-----------------------+------------+-------+--------------------------------------------------------------------------------------------------+-------------------+---------+------+------+----------+-----------------------+
----+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+--------------------------------------------------------------------------------------------------+-------------------+---------+--
| 1 | SIMPLE | t_follow_timeline_099 | NULL | range | PRIMARY,idx_uid,idx_uid_timeline_owner,idx_uid_timeline_id,idx_uid_create_time,idx_uid_status_id | idx_uid_status_id | 17 | NULL | 2774 | 100.00 | Using index condition |
+----+-------------+-----------------------+------------+-------+--------------------------------------------------------------------------------------------------+-------------------+---------+------+------+----------+-----------------------+
查询耗时: 0.00155 秒优化总结
mysql 关于order by的语句优化
- where条件后面的字段加索引,最好是order by id
- 为了保证order by id 不会走到主键索引,需要在组合索引最后一列,加上id
- 组合索引最后一列加上id,是为了让server层识别,避免走到了主键的执行计划,在存储引擎层面是一模一样的
- 这个实现的方法最优雅,比order by id+0好很多,因为这个绝对走不到主键的索引,而上面的方法还有可能
- order by id limit 10 , 目前不能体现在执行计划的row中。eg: idx_uid_status_id , 条件uid = 123 and status =1 order by id limit 10 , key_len 中依然是uid_status的长度,但是没有排序快速返回