本文隶属于AVR单片机教程系列。
在系列教程的最后一篇中,我将向你推荐3个可以深造的方向:C++、事件驱动、RTOS。掌握这些技术可以帮助你更快、更好地开发更大的项目。
本文涉及到许多概念性的内容,如果你有不同意见,欢迎讨论。
关于高层
这一篇教程叫作“走向高层”。什么是高层?
我认为,如果寥寥几行代码就能实现一个复杂功能,或者一行代码可以对应到几百句汇编,那么你就站在高层。高层与底层是相对的概念,没有绝对的界限。
站得高,看得远,这同样适用于编程,我们要走向高层。高层是对底层的封装,是对现实的抽象,高层相比于底层更加贴近应用。站在高层,你可以看到很多底层看不到的东西,主要有编程工具和思路。合理利用工具,可以简化代码,降低工作量;用合适的思路编程,更可以事半功倍。
但是,掌握高层并不意味着忽视甚至鄙视底层,高层建立在底层基础之上。其一,有些高层出现的诡异现象可以追溯到底层,这样的debug任务只有通晓底层与高层的开发者才能胜任;其二,为了让高层实现复杂功能的同时获得可接受的运行效率,底层必须设计地更加精致,这就对底层提出了更高的要求。
相信你经过一期和二期的教程,已经相当熟悉AVR编程的底层了。跟我一起走上高层吧!
C++
C++继承自C,兼有低级语言和高级语言的特性。C++代码可以被编译为汇编语句,这决定了它的高效;C++支持过程式、面向对象、泛型等编程范式,还有庞大的标准库,这决定了它的高级。所有C++代码都可以转换成C代码,使用C++绝非必要,但是不能仅凭这一点而否定C++——因为同理,C也是没有必要的,你为什么还要学C呢?我们使用C++,就是要发挥它的高级。
在几十年的发展过程中,C++委员会制定了多个标准,主要的有C++98和C++11,C++11添加了很多新特性,既能简化程序又能提升性能。本文写于下一个主要标准C++20即将发布之际,主流编译器对C++11的支持已经很完整,所以我的建议是,如果想学C++,按照C++11标准来学。
在AVR平台上写C++比较特殊,在于工具链没有提供C++标准库。如果你想用标准库,无论是IO设施还是容器算法,要么委曲求全,用网上能找到的不完整的实现,要么自己写。这是AVR很劝退C++的一点,对此我的建议是,不要把AVR作为你学习C++的平台,尽管这一节讲的是C++给AVR单片机开发带来的益处。用AVR来操练C++倒是有很多意想不到的好处。
说起AVR与C++,还不得不提起Arduino,这个平台从AVR起家,一直使用C++语言,是AVR平台上C++的最大甚至唯一的应用。我想,如果你能读到这里,你对Arduino肯定不会陌生,方便易用是它的核心卖点之一。事实上,C++这门语言为它提供了不少帮助,而C++的威力还不止于此。我将以范式为线索,介绍C++的高级之处。
在面向对象的世界中,对象和消息是主角,语句是创建对象和规定消息传递方式的工具。定义对象需要用类,定义消息需要类中的函数,安排类之间的关系需要继承和虚函数,这些是功能上的配角,编程逻辑上的主角。
代码中的对象是现实中的对象的抽象,由于单片机往往是跟现实世界打交道,这一点比较容易理解。比如,开发板上的每一个外设,包括LED、按键等,都是对象。
#include <avr/io.h>
#define F_CPU 25000000
#include <util/delay.h>
class Led
{
public:
Led(uint8_t index)
{
mask = 1 << (4 + index);
DDRC |= mask;
}
void on()
{
PORTC |= mask;
}
void off()
{
PORTC &= ~mask;
}
private:
uint8_t mask;
};
Led red(0), yellow(1), green(2), blue(3);
int main()
{
while (1)
{
red.on();
blue.off();
_delay_ms(500);
red.off();
blue.on();
_delay_ms(500);
}
}
在这个程序中,我定义了类Led,它有3个函数:构造函数Led(uint8_t),设置mask并在硬件上初始化LED;on和off,分别开和关LED。然后创建了4个全局变量,分别代表4个LED。最后在main中使用,red.on()使红灯亮,是不是很形象呢?除了形象,你也许还注意到,我没有显式调用含有DDRC的那个函数,实际上它在main之前创建全局变量的时候被调用,自动地初始化硬件。我打赌你之前一定忘记过初始化,而C++帮你解决了这个问题。对象的构造、复制、移动、销毁,以及内存分配,都可以交给C++的语法和标准库来处理。
上面这个程序实际上是基于对象范式的,它体现了抽象和封装。面向对象则更进一步,体现了继承和多态。继承是类与类之间的关系,如果类D继承自类B,那么D类型的对象就包含B类型对象所包含的一切内容,类B称为类D的基类,类D称为类B的派生类。多态是指相同的语句表现出不同的行为,换言之不同行为可以有统一的接口,可分为编译期多态和运行时多态。运行时多态体现为虚函数:基类定义虚函数,派生类们实现虚函数,通过基类调用时,实际属于不同派生类的对象表现出不同的行为。很难理解吧,我们通过实例来看:
#include <stdint.h>
class Shape
{
public:
virtual void draw() const = 0;
};
class Line : public Shape
{
public:
Line(uint8_t x1, uint8_t y1, uint8_t x2, uint8_t y2)
: x1(x1), y1(y1), x2(x2), y2(y2) { }
virtual void draw() const override
{
// Bresenham line...
}
private:
uint8_t x1, y1, x2, y2;
};
class Circle : public Shape
{
public:
Circle(uint8_t x, uint8_t y, uint8_t r)
: x(x), y(y), r(r) { }
virtual void draw() const override
{
// Bresenham circle...
}
private:
uint8_t x, y, r;
};
int main(void)
{
Line line(0, 0, 127, 63);
Circle circle(64, 32, 16);
Shape* shapes[2];
shapes[0] = &line;
shapes[1] = &circle;
for (uint8_t i = 0; i != sizeof(shapes) / sizeof(*shapes); ++i)
shapes[i]->draw();
while (1)
;
}
override是C++11引入的关键字,你需要在项目属性->Toolchain->AVR/GNU C++ Compiler->Miscellaneous->Other flags中写-std=c++11,以启用C++11标准。
这个程序涉及3个类:
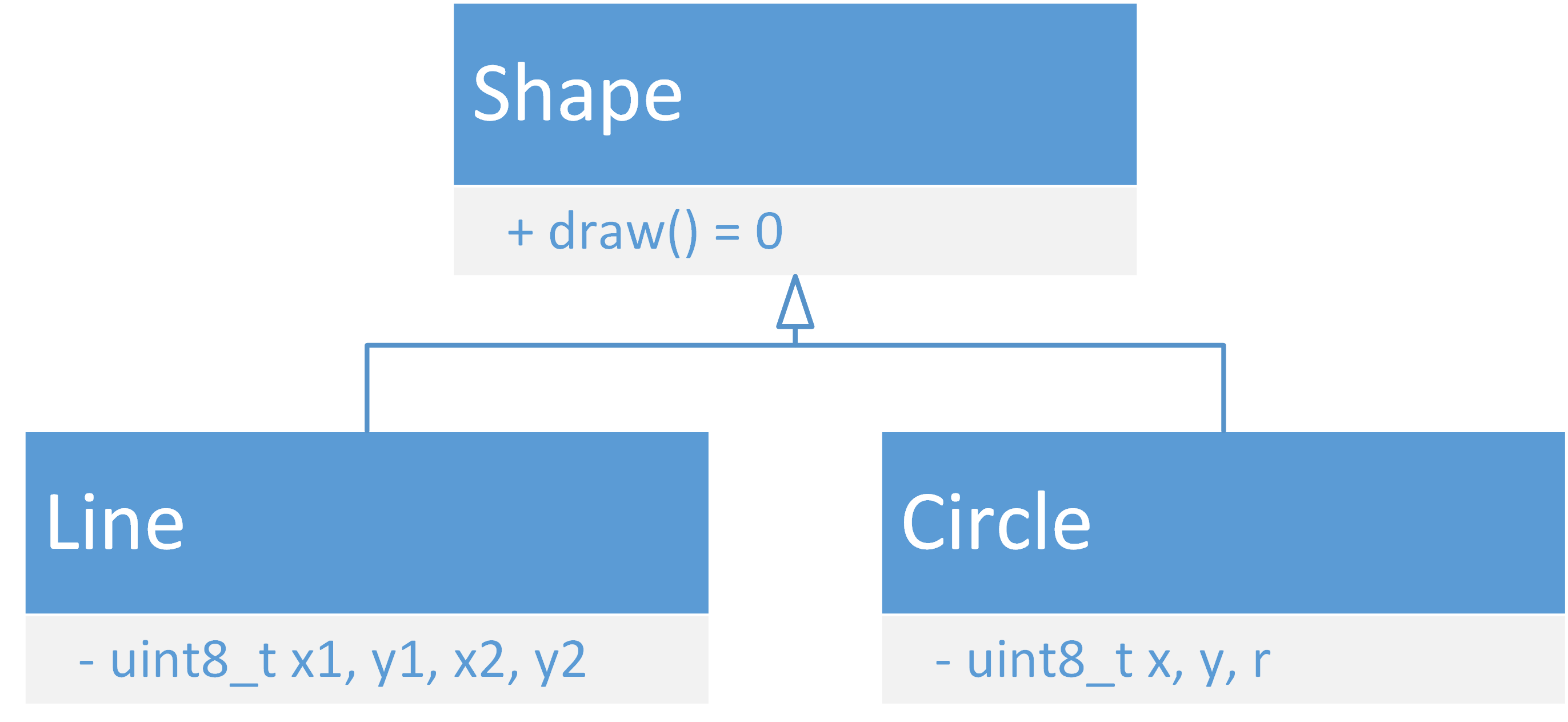
基类Shape定义了虚函数draw,派生类Line和Circle提供了不同的实现。main创建了Line和Circle类各一个对象,把指针放到Shape*类型的数组shapes中,然后通过指针调用draw函数,结果是Line::draw和Circle::draw分别被调用一次。要注意,只有通过指针或引用调用虚函数才能多态。引用用类型后的&表示,功能与指针类似,但不用写取地址和解引用符号,形式上更加简洁一点。
正如你所见,面向对象范式可以帮助你构建起现实中的对象之间的关系。在大型程序中,类与类、对象与对象、类与对象之间有复杂的联系,形成了各种设计模式。
C++和C一样可以自定义数据结构,但是不像C一样用宏来定义ADT,也不用void*来抹去类型,而是引入了模板,可以把元素类型作为模板参数定义类和函数,一个模板类或模板函数可以实例化成很多个类或函数。比如我们在UART一讲中写过的队列,在C++中可以这么写:
#include <stddef.h>
template <typename T, size_t S>
class Queue
{
public:
Queue() = default;
Queue(const Queue&) = delete;
Queue& operator=(const Queue&) = delete;
Queue(Queue&&) = delete;
Queue& operator=(Queue&&) = delete;
void push(const T& element)
{
data[tail] = element;
tail = increase(tail);
}
void pop()
{
head = increase(head);
}
bool empty() const
{
return head == tail;
}
bool full() const
{
return increase(tail) == head;
}
const T& peek() const
{
return data[head];
}
private:
T data[S];
size_t head = 0;
size_t tail = 0;
static size_t increase(size_t value)
{
if (++value == S)
value = 0;
return value;
}
};
顺便把UART那些函数改写一下:
#include <stdint.h>
#include <stdlib.h>
#include <avr/io.h>
#include <avr/interrupt.h>
#include <util/atomic.h>
#define F_CPU 25000000
#include <util/delay.h>
class Uart
{
public:
Uart()
{
UCSR0B = 0 << UDRIE0 // UDRE interrupt disabled
| 1 << TXEN0; // TX only
UCSR0C = 0b00 << UMSEL00 // asynchronous USART
| 0b10 << UPM00 // even parity
| 0 << USBS0 // 1 stop bit
| 0b11 << UCSZ00; // 8-bit
UBRR0L = 40; // 38400bps
}
void print(char c)
{
bool full = true;
while (1)
{
ATOMIC_BLOCK(ATOMIC_FORCEON)
{
if (!queue.full())
full = false;
}
if (!full)
break; // if full, wait until buffer is not full
}
ATOMIC_BLOCK(ATOMIC_FORCEON)
{
if (queue.empty())
UCSR0B |= 1 << UDRIE0;
queue.push(c);
}
}
void print(int i)
{
char str[10];
itoa(i, str, 10);
print(str);
}
void print(const char* s)
{
for (; *s; ++s)
print(*s);
}
void println()
{
print('
');
}
template <typename T>
void println(const T& t)
{
print(t);
println();
}
void _interrupt()
{
UDR0 = queue.peek();
queue.pop();
if (queue.empty())
UCSR0B &= ~(1 << UDRIE0);
}
private:
Queue<char, 64> queue;
} uart;
ISR(USART0_UDRE_vect)
{
uart._interrupt();
}
int main()
{
for (char c = ' '; c <= '~'; ++c)
uart.print(c);
uart.println();
for (int16_t i = 0; ; ++i)
{
uart.println(i);
_delay_ms(500);
}
}
有什么好处呢?第一段代码把原来为char编写的64字节队列缓冲区改写成任意类型、任意长度的队列类模板Queue,以类型T与大小S为模板参数。Uart类中创建了Queue<char, 64> queue,实现原来的功能,而Queue类模板还可以在其他地方使用,比如处理用户输入的指令:Queue<std::string, 10> instr;。
第二段代码是把C代码转换成了基于对象风格的C++代码,这个刚刚介绍过了,亮点在于函数print和println。print这一个函数名字对应参数为char、int和const char*的三个版本,这三个函数是重载函数。如果你给print函数传一个参数,编译器会帮你匹配到最合适的一个重载。在没有模板的情况下,你可以把重载看作是一个人性化的功能,毕竟你是知道实际上哪个函数会被调用的,如果你给函数名字加个表示参数类型的后缀,你也可以不使用重载,只不过这件事现在可以交给编译器了。
讲到函数重载,不得不顺便提一下运算符重载。私以为,运算符重载是C++最美丽的特性之一。在Java中你可以把两个字符串用+号连接,C++也可以;C++还允许你赋予运算符以意义,即为原本语义上不成立的运算符编写代码,它们往往与形象或数学上的意义相契合,比如用operator<<输出,再比如写有理数Rational类然后重载四则运算和比较运算符,而Java中只能覆写Object类的equals方法。况且直观上,operator==是比equals更加原生的写法——==是运算符,属于语言核心,而equals是函数名字,属于标准库。总之,函数重载省去了你为相同功能的函数起不同名字的麻烦,运算符重载则更加直接,连函数名字都省了。
回到正题,在有模板的情况下,重载不再仅仅是人性化功能,而是与泛型紧密结合了。println是一个函数模板,尽管你知道它只能接受char、int和const char*类型的参数,但是写成模板一可以省事,二允许添加额外的print重载而不改变println。如果给print加上后缀,你能在println中知道要调用哪个吗?这也是一种多态,编译期多态。
不过,如果你给println传了一个错误的类型,编译器给的错误信息会很难看,这是C++中模板错误的通病。如果不跳票的话,C++20引入的concept会解决这个问题。
Uart还可以再优化一下,让它继承自基类Print,其中定义了virtual print(char),其他函数照抄,Uart中只需覆写这一个print(char)函数,其他print和println都可以删去,而客户依然可以使用它们。这是因为,虽然println定义在Print中,但println中调用的print(char)是虚函数,还是会回到Uart::print(char)上来。同样地还可以有Oled类继承自Print类,同样覆写自己的print(char)。如果一个函数debug需要打印,它应该接受Print&类型的参数,传入Uart和Oled的实例可以分别实现在串口和OLED屏上打印。
#include <stdlib.h>
class Print
{
public:
virtual void print(char) = 0;
void print(int i)
{
char str[10];
itoa(i, str, 10);
print(str);
}
void print(const char* s)
{
for (; *s; ++s)
print(*s);
}
void println()
{
print('
');
}
template <typename T>
void println(const T& t)
{
print(t);
println();
}
};
class Uart : public Print
{
public:
virtual void print(char c) override { /* ... */ }
} uart;
class Oled : public Print
{
public:
virtual void print(char c) override { /* ... */ }
} oled;
void debug(Print& printer)
{
printer.println("debug");
}
int main()
{
debug(uart);
debug(oled);
}
顺便,实现相同功能的debug还可以是一个函数模板template <typename T> debug(T&),不管T是不是继承自Print,甚至根本不存在Print,只要debug中调用到的print和println等在T中都有实现就可以。
class Uart
{
public:
void println(const char* s) { /* ... */ }
};
class Oled
{
public:
void println(const char* s) { /* ... */ }
};
template <typename T>
void debug(T&& printer)
{
printer.println("debug");
}
int main()
{
Uart uart;
Oled oled;
debug(uart);
debug(oled);
}
如果有标准模板库(STL),Queue都不用自己写,用std::queue<char>就可以了,大小无限直至RAM耗尽。C++的STL是一系列容器和算法的集合,在绝大多数情况下可以提供最优的时间与空间复杂度,让你远离数据结构的烦恼。容器有顺序容器std::vector(自动增长的数组)和std::list(双向链表)等、关联容器std::set(集合)和std::map(键值对)等,算法有std::sort(排序)和std::transform(映射)等,琳琅满目。
容器和算法之间以迭代器为桥梁,各个容器定义的迭代器类型不同,但都有类似的接口,算法都是模板函数,与刚刚描述的模板debug很类似。一个迭代器类型至少要重载operator*(解引用)和operator++(前缀自增)运算符,运算符重载在这里有规定接口的意义。
要说重载最多的运算符,那应该是函数调用运算符operator()了,很多标准库算法都需要这样的参数,作为算法的谓词——有一个或两个参数,返回bool值。比如,给std::sort一个二元谓词,判断第一个参数是否小于第二个,就能得到非递减序的原序列。重载了operator()的对象称为仿函数,它们的类型在算法中都是作为模板参数的。对于不同的迭代器和仿函数类型,标准库算法函数模板会实例化成不同的函数,算法本身比较长,再加上实例化一多,程序体积就会很大,这是C++模板的一个弊端。
仿函数如此灵活,函数式范式于是顺理成章地在C++11被引入。由于有语法的限制和其他范式的诱惑,你很难用C++写一个纯函数式的程序,并且我也不想讲Haskell那样纯正的函数式编程。但是C++11提供的函数工具——lambda表达式和std::function等标准库组件还是很香的,甚至成为了我不得不用C++11的唯一理由,我们一起来看一看。
在C++11以前,传给函数的谓词可以是普通函数或重载了operator()的类的实例,无论是哪种,它都定义在使用处之外,想想正写到兴头上突然要回到全局作用域是什么感觉?这样的代码写起来读起来都不顺。C++11引入的lambda表达式允许你就地创建一个仿函数,参数和返回类型都由自己决定。lambda表达式不仅可以像函数一样使用全局可见的名字,还可以捕获局部变量,捕获方式可以选择以值捕获(拷贝对象)还是以引用捕获(保存指针),是一种非常灵活的语法。
比如,之前提到的debug函数可以接受回调函数作为参数,调用处传入一个lambda。如果uart定义在全局,就不用捕获;如果在局部,就要以引用方式捕获。
class Uart
{
public:
void print(const char*) { /* ... */ }
};
template <typename T>
void debug(T&& callback)
{
callback("debug
");
}
int main()
{
Uart uart;
debug([&](const char* s) {
uart.print(s);
});
}
但是,lambda本身只能立即使用,不能保存起来以后使用,因为lambda的类型是不知道的。C++11引入了多态函数包装器std::function,它可以包装符合模板参数类型的任意仿函数,通过operator()调用,而且它本身是一个类(而非多个类),实例可以拷贝,lambda可以借由std::function被保存。
class Debug
{
public:
using callback_t = std::function<void(const char*)>;
Debug& operator+=(const callback_t& f)
{
callbacks.push_back(f);
return *this;
}
void operator()()
{
for (auto& f : callbacks)
f("debug");
}
private:
std::vector<callback_t> callbacks;
} debug;
int main()
{
Uart uart;
debug += [&](const char* s) {
uart.print(s);
};
Oled oled;
debug += [&](const char* s) {
oled.print(s);
};
debug();
}
此外,还有std::bind可以绑定参数,生成一个新的仿函数。lambda表达式与std::function、std::bind等标准库组件提供的是一套对象级别的消息传递机制,可以一定程度上消除复杂的继承,为程序解耦,使程序更灵活。
以上为函数工具。C++距离纯正的函数式编程还有一段距离,但已经是大势所趋。并发和range库等新标准中添加的内容将帮助C++更好地支持函数式编程。
C++还提供了很多工具,在这里我再介绍3个,它们都与名字有关——起名字永远是让程序员头疼的问题。
所有标准库组件都以std::开头,std是标准库组件的命名空间。如果你在全局作用域内定义名字简短的函数,会造成命名空间污染——如果每个组件的初始化都叫init,不就乱了套了?在C++中,你可以定义自己的命名空间,比如namespace avr或namespace ee,把代码放在里面以避免污染。命名空间可以嵌套,可以内联,还可以在using指令以后省略。
也许你已经注意到,类定义中总有public和private等字样,它们用于规定类中函数和数据的可访问性:public的任何地方都能访问;protected的只有所属类和子类能访问;private的只有所属类自己能访问。在类中规定可访问性不仅是在告诉客户哪些属于实现细节、哪些属于公开接口,更是让编译器强迫客户这么做,体现了封装的原则。
在C中,枚举类型中定义的枚举元素是全局可见的,不同枚举类型不能定义相同的名字,否则就会冲突——在为红绿灯写好RED、YELLOW和GREEN以后,你不能再为状态指示灯定义RED和GREEN!还好,C++11引入了强类型枚举,为枚举元素限定了作用域,访问需要加上类型名字和作用域运算符::。强类型枚举的元素不能隐式转换为int,默认情况下不能用|运算符连接,不过你可以手动地重载operator|。
总之,C++可以提高程序的可读性、使大型程序易于维护,以及为你提供编程思路。C++是一个有机整体,各个范式、各个功能都不能割裂开来使用。当然,没个十年八年,你也不要妄想精通C++,在实际开发中,尤其是在写单片机程序时,使用C++众多功能的一个子集就可以了,这个子集是要由你根据喜好,或你的团队根据开发习惯确定的。不过这个子集大概只能限于单片机开发,因为实践表明,从C++功能中抽离出一个子集用于通用开发的尝试都是失败的。
另外,之前听过一个笑话,说在数据结构课程中,老师讲到链表时发现学生都听不懂,原来他们是从Python开始接触编程的。有人说学习了C++以后,学习计算机方面的其他知识都会变得容易,我认为是有道理的。过程式、基于对象、面向对象、泛型、函数式,五种编程范式涵盖了绝大多数主流编程语言,赋予你触类旁通的能力;下到内嵌汇编,上到网络编程,小到以字节为单位的内存控制,大到复杂而精巧的数据结构,C++都能胜任,为你今后的学习提供工具、打下基础。学习C++也许不是速效的,但长期投入一定是会有收获的。
事件驱动
从逻辑上看,单片机程序都应该是事件驱动的——对外部事件作出反应,不正是嵌入式系统的职责吗?可惜的是,为了实现这样的功能,我们建立了主循环,每隔一段时间扫描一次输入设备,判断有无需要响应的事件发生,如果有则执行相应的动作——事件的检测喧宾夺主,编程的意图被轻视了。更有甚者,输入和输出设备同时对主循环提出了苛刻的要求——每一毫秒切换一位数码管显示,还不能停止按键扫描。输入和输出紧耦合了起来,程序变得复杂,难以维护和扩展。
不信?请看:
实现以下功能:按下一个按键时,数码管显示的十六进制数字加1;保持按下1000毫秒后,每200毫秒数字加1;再加入另一个按键,但它的效果是数字减1。
我的实现:
#include <ee1/delay.h>
#include <ee1/button.h>
#include <ee1/segment.h>
int main()
{
button_init(PIN_NULL, PIN_NULL);
segment_init(PIN_4, PIN_5);
uint8_t num = 0;
int8_t delta[2] = {-1, 1};
uint16_t pressing[2] = {0};
bool triggered[2] = {false};
while (1)
for (uint8_t d = 0; d != SEGMENT_DIGIT_COUNT; ++d)
{
for (uint8_t b = 0; b != 2; ++b)
{
if (button_down(b))
{
++pressing[b];
if (triggered[b])
{
if (pressing[b] == 100)
{
pressing[b] = 0;
num += delta[b];
}
}
else
{
if (pressing[b] == 1)
{
num += delta[b];
}
else if (pressing[b] == 500)
{
num += delta[b];
pressing[b] = 0;
triggered[b] = true;
}
}
}
else
{
pressing[b] = 0;
triggered[b] = false;
}
}
segment_hex(num);
segment_display(d);
delay(1);
}
}
有必要解释一下程序是如何判断按键长按与连续按下的。每个按键对应pressing和triggered两个数组中的各一个元素:pressing表示从上一次触发事件开始按键保持按下了多少毫秒;triggered表示按键按下是否超过500毫秒,也就是是否处于长按的判定范围。程序每一毫秒扫描一次按键:如果按键已松开,把pressing清零,triggered置false;否则,在长按中,每100毫秒触发一次事件,把显示的数字加上或减去1;还未进入长按时,第1毫秒触发,第500毫秒也要触发,并且把triggered置true。更外层的for循环执行动态扫描,点亮数码管的每一位各1毫秒;这个for循环放在while循环中持续运行。
这个程序最主要的问题,在于输入和输出耦合得太紧,在输入、输出或它们之间的关系上改动都不方便。比如,要加入新的按键,也许连接在165上,读取方式与板载按键不同,怎么办?又如,现在按键按下和长按都有动作了,那么松开呢?双击呢?如果要加的话,可能代码翻倍都不止。并且层层缩进,可读性也不好:delay(1)在哪层循环中,恐怕一眼看不出来吧。
按键的判定可以改用状态机,但这不是我们讨论的重点。我们主要解决输入输出耦合的问题,为此我们引入事件驱动的编程范式。事件驱动是一种编程范式,聚焦于事件的发生与处理,事件就是输入和输出之间的纽带。在这个例子中,按键按下与长按是两个事件,事件发生时,显示的数字加上或减去1。动态扫描需要每隔一段时间显示一次,很容易联想到定时器中断,定时器中断也是一个事件。按键需要每隔一段时间读取一次,也可以作为定时器中断事件的处理。
有了这样的思路,就可以动手写代码了。由于应用程序需要定时器和按键事件,其中按键又依赖定时器,我们从定时器写起。
timer.h:
#ifndef TIMER_H_
#define TIMER_H_
void timer_append(void (*func)());
#endif
定时器接口只有一个函数timer_append,用于添加一个事件处理函数。在第一次添加的时候,函数调用开发板库中的初始化。实现在timer.c中:
#include "timer.h"
#include <stdlib.h>
#include <ee2/timer.h>
static void timer_callback();
#define CALLBACK_MAX 2
static void (*callback_table[CALLBACK_MAX])() = {NULL};
static uint8_t callback_count;
void timer_append(void (*func)())
{
if (callback_count == 0)
{
timer_init();
timer_register(timer_callback);
}
if (callback_count < CALLBACK_MAX)
callback_table[callback_count++] = func;
}
static void timer_callback()
{
for (uint8_t i = 0; i != callback_count; ++i)
callback_table[i]();
}
定时器组件的效果是,每次调用timer_append时的参数都会被每个一毫秒依次调用一次。
定时器是全局唯一的,因此一套函数就可以作为接口,但按键可以存在多个,为了指明一次调用对哪个按键有效,我们需要定义一个类型表示按键。同时,定时器的事件类型也只有一种,而按键有按下、长按、松开等,还需要一个枚举类型表示事件类型。button.h:
#ifndef BUTTON_H_
#define BUTTON_H_
#include <stdbool.h>
typedef enum
{
BUTTON_PRESSED, BUTTON_RELEASED, BUTTON_LONG,
} ButtonEvent;
struct Button_t;
typedef struct Button_t* Button;
Button button_create(bool (*down)());
void button_register(Button b, void (*callback)(ButtonEvent));
#endif
button_create用于创建一个按键,参数为判断按键是否按下的函数;button_register给按键注册事件处理函数,这个函数有一个参数指明事件类型。button.c:
#include "button.h"
#include <stdint.h>
#include <stdlib.h>
#include "timer.h"
static void button_update(Button b);
static void button_callback();
typedef enum
{
BUTTON_IDLE, BUTTON_WAS_PRESSED, BUTTON_LONG_TRIGGERED,
} ButtonStatus;
struct Button_t
{
uint16_t pressing;
uint8_t status;
bool (*input)();
void (*handler)(ButtonEvent);
};
#define BUTTON_MAX 2
static Button button_table[BUTTON_MAX] = {NULL};
static uint8_t button_count = 0;
Button button_create(bool (*down)())
{
if (button_count == 0)
timer_append(button_callback);
if (button_count >= BUTTON_MAX)
return NULL;
Button b = malloc(sizeof(struct Button_t));
b->pressing = 0;
b->status = 0;
b->input = down;
b->handler = NULL;
button_table[button_count++] = b;
return b;
}
void button_register(Button b, void (*callback)(ButtonEvent))
{
b->handler = callback;
}
static void button_update(Button b)
{
if (b->input())
{
++b->pressing;
if (b->status == BUTTON_LONG_TRIGGERED)
{
if (b->pressing == 100)
{
b->pressing = 0;
if (b->handler)
b->handler(BUTTON_LONG);
}
}
else
{
if (b->status == BUTTON_IDLE)
{
b->status = BUTTON_WAS_PRESSED;
if (b->handler)
b->handler(BUTTON_PRESSED);
}
else if (b->pressing == 500)
{
b->pressing = 0;
b->status = BUTTON_LONG_TRIGGERED;
if (b->handler)
b->handler(BUTTON_LONG);
}
}
}
else
{
if (b->status != BUTTON_IDLE && b->handler)
b->handler(BUTTON_RELEASED);
b->pressing = 0;
b->status = BUTTON_IDLE;
}
}
static void button_callback()
{
for (uint8_t i = 0; i != button_count; ++i)
button_update(button_table[i]);
}
Button_t结构体保存按键的信息,包括输入input、状态pressing与status、输出handler。button_update读取按键输入并更新其状态,并且可能调用回调函数。button_callback中对每个按键调用button_update,它本身又被注册给定时器。
现在可以编写应用程序了。main.c:
#include <stdbool.h>
#include <ee2/button.h>
#include <ee2/segment.h>
#include "timer.h"
#include "button.h"
uint8_t num = 0;
bool button_down_0()
{
return button_down(BUTTON_0);
}
bool button_down_1()
{
return button_down(BUTTON_1);
}
void num_decrease(ButtonEvent e)
{
switch (e)
{
case BUTTON_PRESSED:
case BUTTON_LONG:
--num;
break;
default:
break;
}
}
void num_increase(ButtonEvent e)
{
switch (e)
{
case BUTTON_PRESSED:
case BUTTON_LONG:
++num;
break;
default:
break;
}
}
void segment_scan()
{
static uint8_t d = 0;
segment_hex(num);
segment_display(d);
if (++d == SEGMENT_DIGIT_COUNT)
d = 0;
}
int main()
{
button_init(PIN_NULL, PIN_NULL);
Button button_l = button_create(button_down_0);
button_register(button_l, num_decrease);
Button button_r = button_create(button_down_1);
button_register(button_r, num_increase);
segment_init(PIN_4, PIN_5);
timer_append(segment_scan);
while (1)
;
}
我们先写了几个函数:button_down_0和button_down_1分别返回两个按键是否按下;num_decrease和num_increase是两个按键事件的回调函数;segment_scan是定时器回调函数,每次调用时显示数码管的一位。在main中,我们先初始化按键,创建两个按键,然后注册以回调函数,再初始化数码管并给定时器注册回调函数,最后进入死循环以保持程序运行。整个程序的运行流程为:先执行main中的初始化,然后在每一毫秒触发的定时器中断中,通过库调用到timer_callback,其中依次调用button_callback和segment_scan;button_callback调用对每个按键调用button_update,其中会调用注册给按键的回调函数num_decrease和num_increase。
这是一个简单的事件驱动范式的程序,虽然代码有点长,但是一旦你把逻辑理清楚,就会发现程序结构还是很清晰的,并且可以在此基础上扩展额外的功能,或者把这种结构应用于其他场合。
从这个简单的例子中我们可以发现:事件有多种、多个,有的事件依赖于其他事件;一个事件的处理函数可能不止一个。事实上,事件驱动架构中还有很多值得斟酌的细节。
事件的粒度。比如,是把一个按键的各种行为作为一个事件,注册一个回调函数,还是每种行为有各自的?或者更大一点,一组按键共用一个?粒度较小的写起来更加自如,不用在回调函数中写switch-case,但是事件驱动的库可能需要消耗更多内存;粒度较大的可以省内存,但是回调函数中需要频繁的分支语句,可读性降低,时间性能也会下降。如果需要两个按键同时按下的事件,粒度比按键组更小的事件恐怕无法胜任;如果每个最小的事件都有独立的事件处理函数,那么大粒度省内存,小粒度高性能。
回调函数的结构。一个事件可以被注册多少个回调函数?一个、有限个,或是在内存耗尽前可以无限个?如果是多个,是否允许相同的回调函数被注册多次,然后被调用多次?是否需要删除一个回调函数?多个回调函数以什么顺序调用?注册顺序,与注册顺序相反的顺序,或者其他?限制一个回调函数很省事,但是可能造成组件之间耦合过于紧密;允许多个回调函数丰富功能,但需要考虑数据结构的问题。有限个通常用固定大小的数组,插入、删除、查找、遍历等操作都可以在确定时间内完成;无限个的情况,如果要求有序但不需要删除,可以用可变数组,需要的话可以用链表,不允许重复的话也可以用二叉树,取决于数据规模。
事件的控制。有些时候客户需要回调函数不被调用,但不能对已注册的回调函数进行修改,因为其他组件也注册过。可以在回调函数中设置指示是否执行的变量,也可以增加启用、禁用事件的接口。当事件禁用时,相应的读取操作可以省略,提升性能。如果有禁用的功能的话,事件是何时启用的呢?是在注册时自动启用,还是需要手动启用?以及,如果客户需要模拟事件的发生,是把已注册的回调函数返回给客户供其调用,还是增加特定的接口呢?
参数包含的信息。在上面的例子中,按键事件的回调函数有一个指明事件类型的参数,但是仅这一个参数并没有包含事件的所有信息,比如是哪个按键触发了这一事件。事件源可以作为回调函数的参数,使客户可以向若干个相同类型的事件源注册相同的回调函数,通过事件源作为参数执行相似的动作,从而增强可读性的同时减小程序体积。有些事件包含的信息过于复杂,回调函数不一定需要其中的所有内容,全部传入浪费资源,可以先传入一小部分,然后让回调函数选择性地向事件源索取其余信息。
以上各种细节,是你在设计一个事件驱动的库时需要考虑的,也是在使用一个现有的事件驱动的库时需要明确的。最后我们来谈一谈事件驱动的应用与利弊。
事件驱动范式的好处主要体现在开发者上,解耦、增加可读性,使程序易于维护和扩展,减少开发者的工作量。事件驱动是一套约定俗成的架构,掌握了它可以让你在面对这一风格的库时更加得心应手。无论是从零开始搭建还是使用现有的库,你都会感觉到编程思路的转变,关注点从底层转向应用,甚至有点搭积木式编程的意味,这不正契合了“走向高层”的主题吗?
对程序员友好的东西往往对执行程序的不友好,事件驱动架构相比于输入输出直接耦合的程序,由于添加了一层或多层回调,再加上诸多细节,性能会受到一些影响,好在它并不是很严重。在人机交互的应用中,人的反应比机器慢很多,允许一些性能下降并不会造成什么影响;在嵌入式应用中,开发效率的重要性也日益增加,同时伴随着工艺与性能的提升,事件驱动架构的负面影响通常可以忽略。
对老鸟友好的东西往往对新手不太友好,事件驱动范式的入门需要花一些功夫,重在理解信息传递的路径与程序执行的流程。在设计一个事件驱动的程序的过程中,除了上面提到的诸多细节外,你还会遇到组件难以明确划分等各种问题。当然,你会在解决这些问题的过程中有很多收获。对于一个项目而言,如果事件驱动的底层是从零开始编写的,那么初期投入也会稍大一些,不过整体来看还是划算的。
一言以蔽之,事件驱动这玩意儿,学它、用它,不会错的。
RTOS
实时操作系统(RTOS)是一类操作系统。带有操作系统的计算机系统相比不带有的,最显著的特点是支持多任务。我们之前写的程序,在监控按键的同时,开了一个定时器中断用于数码管动态扫描,两个任务同时进行,是多任务吗?不完全是。监控按键与动态扫描两个任务只有一个可以占据main函数,另一个必须放在中断里,中断里的任务不能执行太长时间,否则就会干扰main函数的运行。而操作系统中的任务调度器可以给每个任务分配一定的运行时间,CPU一会执行这个,一会执行那个,每个任务都好像独占了CPU连续执行一样。
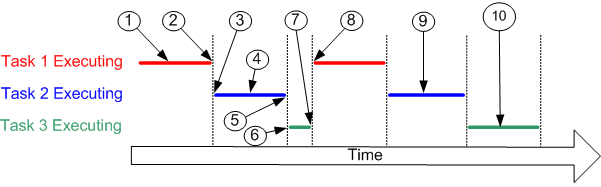
RTOS与其他操作系统的主要区别在于任务调度器的设计。在RTOS中,所有任务都有优先级,优先级高的被调度器保证优先执行,以获得最短的响应时间。在与现实世界打交道的嵌入式系统中,这样的功能往往是必要的。
操作系统通常需要中档的硬件,8位的AVR稍差了一点,主频和存储容量达不到一些操作系统的要求,不过还是有可选项的。我们来试着在开发板上运行FreeRTOS。FreeRTOS是一个免费的、为单片机设计的RTOS,是目前嵌入式市场占有率第二的操作系统,仅次于Linux。
首先去官网下载代码。下载的是一个.zip压缩包,找到FreeRTOS文件夹,目录下Demo和Source中的部分代码是需要使用的。作为一个跨平台的系统,大多数代码平台无关,只存一份,其他平台相关的代码,每个平台都有独立的实现,源码是demo都是如此,这使得代码组织有些复杂,你可以参考官方文档。
官方提供了ATmega323单片机的demo,为了在开发板上运行,需要做一些修改。demo基于WinAVR平台,它与Atmel Studio一样,都是基于avr-gcc的。如果你有WinAVR的话,直接用makefile就可以编译;Atmel Studio虽然也提供了make,但有些微区别,没法直接用makefile,因此我们自己建立项目来编译。
-
新建项目,然后在Solution Explorer中建3个文件夹:
source、port和demo。 -
拷贝一些文件到这些目录下:
-
source:Sourceinclude所有文件、Source下的tasks.c、queue.c、list.c和croutine.c; -
port:SourceportableGCCATmega323所有文件和SourceportableMemMang`下的heap_1.c; -
demo:DemoCommoninclude所有文件、DemoCommonMinimal下的crflash.c、integer.c、PollQ.c和comtest.c、DemoAVR_ATMega323_WinAVR除makefile以外的所有文件,再把ParTest.c和serial.c拎出来,main.c拎到外面。
我是怎么知道的呢?我参考了官方文档和
makefile文件。 -
-
在Solution Explorer中Add Existing Item,在项目属性->Toolchain->AVR/GNU C Compiler->Directories中添加这三个目录。
-
修改代码,使之适用于我们的开发板:
修改的理由有以下几种:
-
ATmega323和ATmega324的寄存器略有不同;
-
WinAVR和Atmel Studio提供的工具链中的一些定义方式不同;
-
硬件配置与连接不同。
所以需要做以下修改:
-
port.c中:TIMSK改为TIMSK1;SIG_OUTPUT_COMPARE1A改为TIMER1_COMPA_vect;54行改为0x02; -
FreeRTOSConfig.h中:48行改为25000000; -
serial.c中:UDR、UCSRB、UCSRC、UBRRL、UBRRH分别改为UDR0、UCSR0B、UCSR0C、UBRR0L、UBRR0H;67行改为0x00;188行改为ISR(USART0_RX_vect);207行改为ISR(USART0_UDRE_vect); -
comtest.c中:71行改为4;72行改为2; -
ParTest.c中:DDRB改为DDRC;PORTB改为PORTC;49行改为0x00;50行改为3;72和99行把uxLED改为(4 + uxLED);76行把if和else的大括号中的语句对调; -
main.c中:删除81和84行;111行改为0;117行改为3;127行改为2;153行返回类型改为int。
-
不出意外的话,现在代码可以通过编译了(我这里有3个warning)。下载到单片机上,连接TX和RX,你会发现红灯和黄灯分别以300ms和400ms为周期闪烁,绿灯和串口黄灯一起闪烁,蓝灯不亮。
实际上,程序创建了1个整数计算、2个串口收发、2个队列收发、2个寄存器测试、1个错误检查和1个空闲共9个任务,以及2个LED闪烁协程。每过一毫秒,定时器产生一次中断,任务调度器暂停当前任务,换一个任务开始运行。为了理解这个过程,我们先介绍上下文这个概念。
一个任务在执行的过程中,需要一些临时变量,它们有的保存在栈上(栈是内存中的一块区域,寄存器SP指向栈顶),有的在寄存器中;此外,条件分支语句还要用到寄存器SREG中的位,这些位在之前的语句中被置位或清零;还有记录当前程序执行到哪的程序计数器。这些一起构成了任务执行的上下文:寄存器r0到r31、SREG、SP和PC。不同任务的上下文是不共享的,但它们却要占用相同的位置,为此,在切换任务时需要把前一个上下文保存起来,并恢复要切换到的任务的上下文,这个过程称为上下文切换,然后才能继续这个任务。
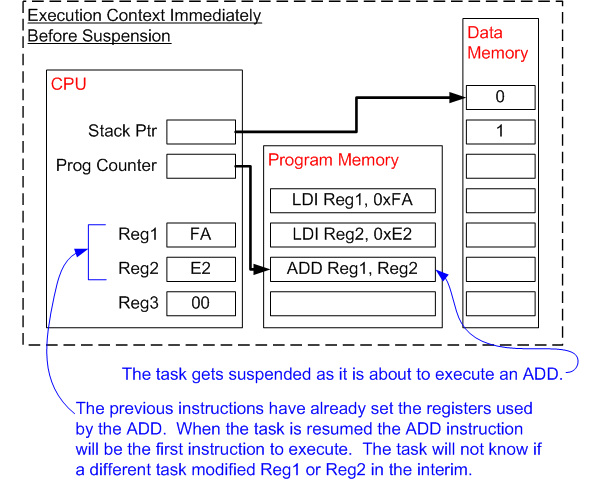
我们来结合代码分析一下这个过程。
void TIMER1_COMPA_vect( void ) __attribute__ ( ( signal, naked ) );
void TIMER1_COMPA_vect( void )
{
vPortYieldFromTick();
asm volatile ( "reti" );
}
void vPortYieldFromTick( void ) __attribute__ ( ( naked ) );
void vPortYieldFromTick( void )
{
portSAVE_CONTEXT();
if( xTaskIncrementTick() != pdFALSE )
{
vTaskSwitchContext();
}
portRESTORE_CONTEXT();
asm volatile ( "ret" );
}
typedef void TCB_t;
extern volatile TCB_t * volatile pxCurrentTCB;
#define portSAVE_CONTEXT()
asm volatile ( "push r0
"
"in r0, __SREG__
"
"cli
"
"push r0
"
"push r1
"
"clr r1
"
"push r2
"
"push r3
"
"push r4
"
"push r5
"
"push r6
"
"push r7
"
"push r8
"
"push r9
"
"push r10
"
"push r11
"
"push r12
"
"push r13
"
"push r14
"
"push r15
"
"push r16
"
"push r17
"
"push r18
"
"push r19
"
"push r20
"
"push r21
"
"push r22
"
"push r23
"
"push r24
"
"push r25
"
"push r26
"
"push r27
"
"push r28
"
"push r29
"
"push r30
"
"push r31
"
"lds r26, pxCurrentTCB
"
"lds r27, pxCurrentTCB + 1
"
"in r0, 0x3d
"
"st x+, r0
"
"in r0, 0x3e
"
"st x+, r0
"
);
#define portRESTORE_CONTEXT()
asm volatile ( "lds r26, pxCurrentTCB
"
"lds r27, pxCurrentTCB + 1
"
"ld r28, x+
"
"out __SP_L__, r28
"
"ld r29, x+
"
"out __SP_H__, r29
"
"pop r31
"
"pop r30
"
"pop r29
"
"pop r28
"
"pop r27
"
"pop r26
"
"pop r25
"
"pop r24
"
"pop r23
"
"pop r22
"
"pop r21
"
"pop r20
"
"pop r19
"
"pop r18
"
"pop r17
"
"pop r16
"
"pop r15
"
"pop r14
"
"pop r13
"
"pop r12
"
"pop r11
"
"pop r10
"
"pop r9
"
"pop r8
"
"pop r7
"
"pop r6
"
"pop r5
"
"pop r4
"
"pop r3
"
"pop r2
"
"pop r1
"
"pop r0
"
"out __SREG__, r0
"
"pop r0
"
);
在定时器中断TIMER1_COMPA_vect中,vPortYieldFromTick被调用,其中依次调用portSAVE_CONTEXT、xTaskIncrementTick、vTaskSwitchContext(可能不调用)和portRESTORE_CONTEXT,执行汇编语句ret;最后执行reti。
在介绍中断的时候,我们提到过编译器添加的额外代码,把用到的寄存器都push进栈。但是,编译器只会保护该中断用到的寄存器,而上下文包括所有寄存器,需要手动地编写代码,那么也就无需编译器添加多余的代码了。函数TIMER1_COMPA_vect被添加attributenaked,表示无需添加任何代码,把用户编写的原原本本地编进去就够了。
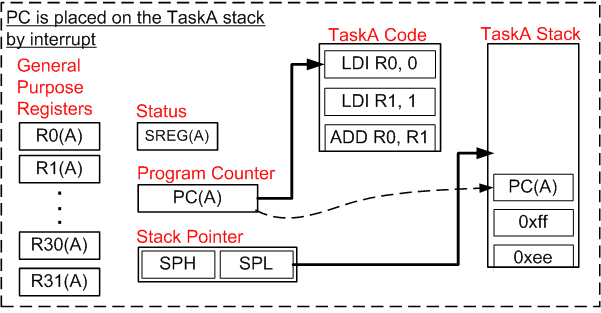
进入中断时,PC被push进栈(这是硬件做的),PC内容变为TIMER1_COMPA_vect的地址,随后开始执行,PC再次push进栈(没有在图片中表示出来),开始执行portSAVE_CONTEXT保存上下文。由于它是宏,就没有PC进栈的过程。
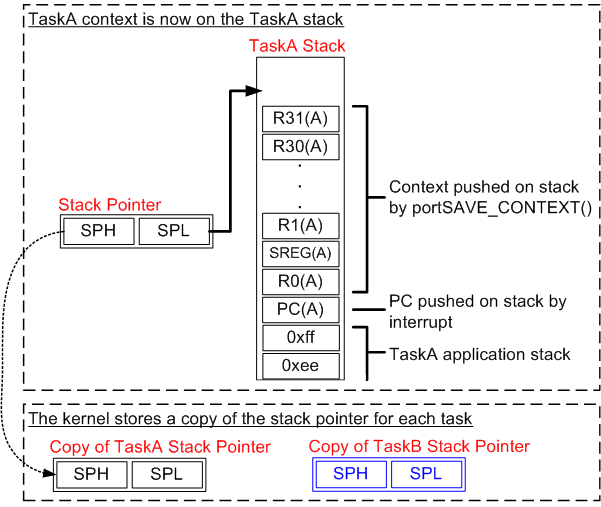
然后,r0、SREG、r1到r31依次进栈,上下文的内容保存完成,其位置还需要另存。SP指向栈顶,代表着上下文的位置,它被复制到pxCurrentTCB所指的位置中。pxCurrentTCB实际上是结构体TCB_t指针,该结构体保存着当前执行的任务的信息,前两个字节保存栈指针。这样,上下文就保存完成了。
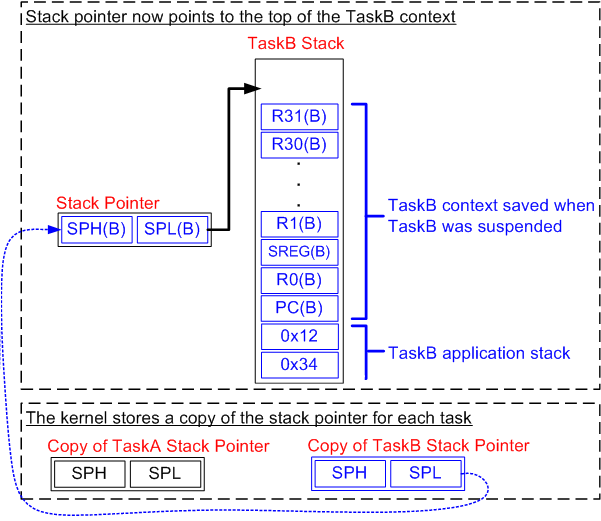
xTaskIncrementTick把软件计数器加1,并检查是否需要任务切换。为了讲解,我们假定它需要,那么vTaskSwitchContext就会被调用,pxCurrentTCB指向另一个TCB_t变量,那里保存着另一个任务的上下文,我们要恢复它。

恢复过程是,先用pxCurrentTCB取出SP,再按相反的顺序出栈,上下文中就只剩PC没有恢复了(ret和vPortYieldFromTick的调用抵消,一起忽略)。最后执行reti,该汇编语句从栈顶取两个字节放进PC,并跳转到其位置继续执行。此时,PC的内容就是该任务之前被中断时执行到的位置,现在从PC开始继续执行,也就是继续执行该任务。上下文切换完成。
在对FreeRTOS稍有了解后,我们动手写一个基于FreeRTOS的程序。在学习数码管的时候,你很可能考虑过,在后台创建一个任务,执行数码管的扫描。现在,FreeRTOS给了你这个机会。我们创建两个任务,一个每一毫秒显示数码管的一位,另一个每200毫秒更新显示的数字。
#include <stdlib.h>
#include "FreeRTOS.h"
#include "task.h"
#include "semphr.h"
#include <ee2/segment.h>
SemaphoreHandle_t mutex;
portTASK_FUNCTION(segment_scan, pvParameters)
{
while (1)
{
static uint8_t digit = 0;
xSemaphoreTake(mutex, 1000);
segment_display(digit);
xSemaphoreGive(mutex);
if (++digit == 2)
digit = 0;
vTaskDelay(1);
}
}
portTASK_FUNCTION(segment_set, pvParameters)
{
while (1)
{
static uint8_t number = 0;
xSemaphoreTake(mutex, 1000);
segment_dec(number);
xSemaphoreGive(mutex);
if (++number == 100)
number = 0;
vTaskDelay(200);
}
}
int main()
{
segment_init(PIN_8, PIN_9);
mutex = xSemaphoreCreateMutex();
xTaskCreate(segment_scan, "scan", configMINIMAL_STACK_SIZE, NULL, 1, NULL);
xTaskCreate(segment_set, "set", configMINIMAL_STACK_SIZE, NULL, 2, NULL);
vTaskStartScheduler();
return 0;
}
两个任务都需要使用数码管这一资源。如果一个任务正在调用segment_dec,还没返回时,定时器中断发生,切换到另一个任务,其中调用了segment_display,就会发生冲突。我们用一个互斥量mutex来解决。当一个任务调用了xSemaphoreTake后,在它调用xSemaphoreGive前,mutex会进入锁定状态,如果另一个任务试图调用xSemaphoreTake,则会阻塞住,切换到另一个任务。这样就保证两个任务不会冲突。资源共享是并行程序要着重处理的问题之一。
FreeRTOS还有很多功能等待你去发掘,RTOS就更多了。最后,我们来谈谈RTOS的长处和短处。
RTOS是多任务的,这是对代码顺序执行的编程模型的颠覆,使程序可以实现更多功能,比如两个连续的(不调用delay之类的函数的)任务同时执行。即使是大多数情况下中断可以解决的问题,RTOS的引入也能让你更快地实现相同功能,这既体现在编程思路的改进,还有现成API可供使用,提高开发效率。如果涉及到程序在平台间的移植,RTOS能提供的帮助就更多了。
RTOS是事件驱动的,尽管表面上不太看得出来。这也能带来一些收益,我们将在本文最后一节进行分析。
然而,RTOS的运行负担较大,包括时间和空间,比如在AVR平台上,一次任务调度至少需要100多个指令周期。在应用本身不太复杂的情况下,这一点尤为严重,需要根据应用决定是否使用。我把RTOS安排到了最后一篇,显然是建议在AVR单片机开发中,尽可能不要使用RTOS。
最后,RTOS对个人发展是有好处的。Linux尽管不是RTOS,作为安装量最大的操作系统内核,是嵌入式开发者必须精通的。各种RTOS与Linux一样都是操作系统,无非是调度策略不同(Linux也有实时的),很多内容都是相通的。学习RTOS对学习Linux有很大帮助,这对你的嵌入式道路是有益无害的。
融会贯通
C++是一门编程语言,可以脱离事件驱动和RTOS存在。事件驱动可以用C实现,但C++等面向对象语言更合适;RTOS往往是事件驱动的。
C++可以为事件驱动架构提供很大的帮助。事件源可以用对象来表示,注册、启用、询问等操作可以用类成员函数来实现,必要时事件源的类还可以用上继承。回调函数的类型也有了更多选择,在C中几乎只能是函数指针,而在C++中还可以用继承自某一基类的仿函数,或std::function多态函数。存储回调函数的数据结构用C++来表示也会方便许多。
RTOS使用系统层级的事件驱动架构。当一个任务想要获取信号量但是没有成功时,它不是一直等待直到获取,而是向该信号量注册此任务,然后切换到另一任务执行。当另一任务释放该信号量时,它会查看哪些任务阻塞在该信号量上,如果有优先级更高的则切换过去执行。这样每时每刻都有任务在执行,没有资源被浪费。
RTOS为应用层级的事件驱动架构提供更多选择。在没有RTOS的程序中,外设的扫描和回调函数的执行一般都放在中断中,而初始化却在main中,会出现一些数据共享的问题。有时回调函数执行时间过长,会错过定时器中断,导致事件没有被检测到。RTOS提供了另一种结构:一个高优先级的任务扫描外设,检测到事件时把事件信息放到一个消息队列中,另一个低优先级的任务从队列中获取消息,并执行相应的事件处理函数。事件处理函数可以长时间运行而不影响事件监测,还可以在新的任务中并发执行。
如果你对本文所介绍的三个主题都很有兴趣,我推荐你学习C#编程。C#主要用于编写Windows平台的窗口程序,语法与C++类似,使用事件驱动机制处理消息,支持并发与异步,有极其丰富的标准库,包括数据结构、图形、网络、数据库等,是一门实用性很强的、能快速地学以致用的语言。
AVR单片机教程就到这里。希望你能早日站在高层,“会当凌绝顶,一览众山小”!