Python 模块
在前面的几个章节中我们脚本上是用 python 解释器来编程,如果你从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
下面是一个使用 python 标准库中模块的例子。
import sys print('命令行参数如下:') for i in sys.argv: print(i) print(' Python 路径为:', sys.path, ' ')
注意:
- 1、import sys 引入 python 标准库中的 sys.py 模块;这是引入某一模块的方法。
- 2、sys.argv 是一个包含命令行参数的列表。
- 3、sys.path 包含了一个 Python 解释器自动查找所需模块的路径的列表。
import 语句
想使用 Python 源文件,只需在另一个源
文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN]
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support,需要把命令放在脚本的顶端:
support.py 文件代码
# Filename: support.py
def print_func( par ):
print ("Hello : ", par)
return
test.py 引入 support 模块:
test.py 文件代码
# Filename: test.py
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
以上实例输出结果:
$ python3 test.py
Hello : Runoob
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?
这就涉及到Python的搜索路径,搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块。
这看起来很像环境变量,事实上,也可以通过定义环境变量的方式来确定搜索路径。
from … import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]
from … import * 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
深入模块
模块除了方法定义,还可以包括可执行的代码。这些代码一般用来初始化这个模块。这些代码只有在第一次被导入时才会被执行。
每个模块有各自独立的符号表,在模块内部为所有的函数当作全局符号表来使用。
所以,模块的作者可以放心大胆的在模块内部使用这些全局变量,而不用担心把其他用户的全局变量搞混。
从另一个方面,当你确实知道你在做什么的话,你也可以通过 modname.itemname 这样的表示法来访问模块内的函数。
模块是可以导入其他模块的。在一个模块(或者脚本,或者其他地方)的最前面使用 import 来导入一个模块,当然这只是一个惯例,而不是强制的。被导入的模块的名称将被放入当前操作的模块的符号表中。
还有一种导入的方法,可以使用 import 直接把模块内(函数,变量的)名称导入到当前操作模块。比如:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种导入的方法不会把被导入的模块的名称放在当前的字符表中(所以在这个例子里面,fibo 这个名称是没有定义的)。
这还有一种方法,可以一次性的把模块中的所有(函数,变量)名称都导入到当前模块的字符表:
>>> from fibo import *
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这将把所有的名字都导入进来,但是那些由单一下划线(_)开头的名字不在此例。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
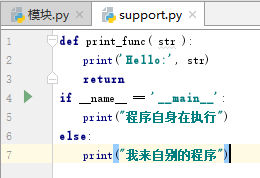
__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
运行输出如下:

运行结果:

说明: 每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
说明:__name__ 与 __main__ 底下是双下划线, _ _ 是这样去掉中间的那个空格。
dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
>>> import fibo, sys
>>> dir(fibo)
['__name__', 'fib', 'fib2']
>>> dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__',
'__package__', '__stderr__', '__stdin__', '__stdout__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe',
'_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv',
'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',
'call_tracing', 'callstats', 'copyright', 'displayhook',
'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix',
'executable', 'exit', 'flags', 'float_info', 'float_repr_style',
'getcheckinterval', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit',
'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path',
'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1',
'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit',
'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout',
'thread_info'