#coding=utf8
# 用python 2.x来运行下面的程序
# s1="黎明"
# s2=u"小丽丽"
#
# print repr(s1)
# print repr(s2)
#
# print (s1)
# print (s2)
# print (s1.decode("utf8"))
# print type(s1.decode("utf8"))
# print type(s1.decode("gbk"))
#
# print s2.encode("utf8")
# print s2.encode("gbk")
#
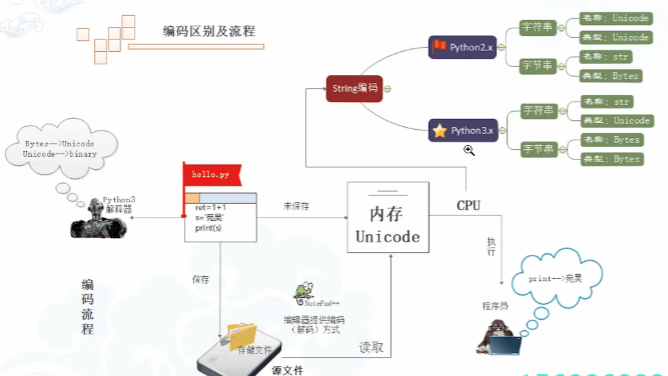
# python 3.x:
# 1、str unicode
# 2、unicode
s="李杰"
s2=b"hello" #bytes是数据类型
print (type(s))
print (type(s2))
print(type(b"he"+b"llo"))
# unicode utf8 gbk都是编码规则,保存的是这些编码规则下的二进制数
# 为什么内存存储里面一定是unicode,不能是utf8
# 如果保存为utf8,如果对方是GBK,由于两者没有直接的对应匹配关系,所以要先翻译为unicode,才能转为GBK
# 程序执行前和执行后两个状态decode和encode
# 编码就是明文与二进制数字的对应