Checkpoints是实现SSIS包重载的基础。它的原理是把当前运行环境的配置、变量以及到了包运行到哪一步和哪一步失败这些信息写入到一个文件中。而且有一点很重要,Checkpoint只发生在Control Flow级别。
要实现包重载,配置上需要配置3个包级别的属性和1个任务属性:
CheckpointFilename: Checkpoint文件的文件名
CheckpointUsage: 3 options
- Never: 意思就是不用重载
- If Exists: 如果CheckpointFilename的文件存在就重载
- Always: 如果CheckpointFilename的文件不存在,包会失败
SaveCheckpoints: 意思很明显,要不要记录checkpoints.
上面那三个配置都是包级别的,下面这个是task级别的属性设置:
FailPackageOnFailure: 如果你希望你的包里面的每一个control flow的task都具备重新执行的能力,就必须把每一个task的这个属性都设置为true;
虽说Checkpoint只发生在Control Flow级别,但是通过简化Data Flow的逻辑或者说把每一个Data Flow的工作量细化,再结合raw file这种task来staging数据实现所谓的“Data Flow”级别的重载能力。
有两点点很重要需要说一下,CheckPoint的这种重启是基于”时间线“的。基于时间线的意思就是如果现在有一个包是这样的:
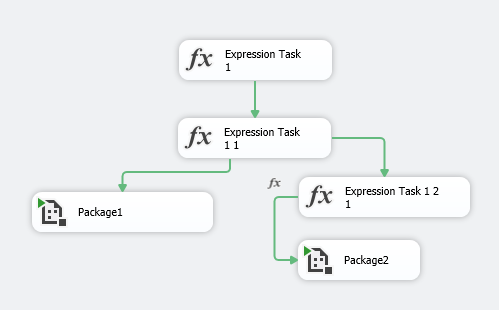
我曾经做过这样一个假设,如果说Package1和Package2分别代表着加载数据到不同的stage表里面,两种间没有先后的依赖关系,而上面这样的设计是为了利用SSIS的同步执行特性来同时执行Tasks。那么假设Package1会最终遇到Error而失败,但是Package2成功完成了。我们当然希望说下次CheckPoint知道这一点并且下次不需要再执行一遍Package2这条分支,然而一直失败,最终发现CheckPoint断定是否需要重新执行同一级别的分支任务的依据是其他分支(除产生错误所在分支以外的那些)中Task完成执行的时间点是否在错误的那个Task发生错误的时间点之前。这是非常坑爹的一点。不明白微软的SSIS工具不可以做到不基于时间线而是基于结果来断定下次再度开启那些任务呢。这点其实完全解释得通也是用户需要的。假设每个分支分别负责Load数据到不同的表,我肯定不希望明明没有问题的工作流要再跑一遍啦。以上的测试结果是基于SQL Server 2014版本的SSIS。
这种用raw file实现的重启功能存在一定的弊端。首先,付出两次的IO操作 — 生成raw file然后在另一个Task里面再读出,一写一读。当中还有一些影响因素,比如raw文件存放的位置是本地还是LAN下面的文件共享服务器,存放raw文件的磁盘是什么样的阵列类型,是RAID1?RAID0?RAID5? 最理想当然是RAID0(带区卷)了,性能最好。是否采用这种方法取决于两点:是否值得和是否适用? 值得是如果说是因为网络问题需要stage数据,那么发生的频率就是成了是否要采用这种做法的一个考虑因素。是否适用是指如果每次source或者upstream进来的数据量很大,比如几百万行,那两次IO操作的代价就非常大了,是否可以考虑比如缩小extract的间隔来减小每次的数据量。