今天特地查了一下SQL Server下的校检函数有哪些。原本我只是在工作中用过一个CHECKSUM,今天特地学习了一下才发现原来还有其他的校检函数。
这里找到了别人对于SQL SERVER下这几个校检函数的学习总结,借此机会学习下别人的学习成果
http://bbs.51cto.com/thread-1145105-1.html
CHECKSUM和BINARY_CHECKSUM
- CHECKSUM和BINARY_CHECKSUM都是可以针对表中一行的单列或者多列又或是表达式生成数据类型为INT的校检值。
- 不同的地方是BINARY_CHECKSUM是转成了二进制后生成的校检值。
- 并不是所有的数据类型都可以用到CHECKSUM或BINARY_CHECKSUM上的。BINARY_CHECKSUM 在计算中忽略具有不可比数据类型的列。 不可比数据类型包括 text、ntext、image、cursor、xml 和不可比公共语言运行库 (CLR) 用户定义的类型。
- MSDN上讲到BINARY_CHECKSUM 可用于检测表中行的更改。但是也提到BINARY_CHECKSUM(*) 将为大多数(但不是全部)行更改返回不同的值,并可用于检测大多数行修改。
- 因为校检值是一个INT,根据INT的数值分布[-2147483648,2147483647],如果某长表中的行数大于2亿估计就会出现重复的情况了。这点在以前工作中就碰到过。
- CHECKSUM和BINARY_CHECKSUM的不同是:1)CHECKSUM是不区分大小写。它认为Jerry和jerry是同样的校检值;2)如果两个表达式具有相同的类型和字节表示,那么对于 BINARY_CHECKSUM 将返回相同的值。例如,BINARY_CHECKSUM 对于“2Volvo Director 20”和“3Volvo Director 30”将会返回相同的值。这段参考了http://ultrasql.blog.51cto.com/9591438/1607407
CHECKSUM_AGG
这个是个聚合函数。返回组中各值的校验和。 将忽略 Null 值。 后面可以跟随 OVER 子句。CHECKSUM_AGG 用于检测表中的更改。如果表达式列表中的某个值发生更改,则列表的校验和通常也会更改。 但只在极少数情况下,校验和会保持不变。很多情况下这个函数应该是用来检测表的数据是否有改动或者表的某个字段的数据是否有发生改动。
HASHBYTES
HASHBYTES是一个加密算法函数,用来对数据进行加密、或校验。它会返回其在 SQL Server 中的输入的 MD2、MD4、MD5、SHA、SHA1 或 SHA2 哈希值。它可以是作为加密功能和强度上更加强大的函数。可以用MD5替换CHECKSUM或BINARY_CHECKSUM避免重复。但是性能上可能有所下降。当然了,比起SHA-256这种加密强度极强的算法,MD5还是完全能接受的。
---------------------------------------------------- Update on 11/21/2015 ---------------------------------------------------------
这些函数的一个作用就是用于数据校验。举一个非常常用的场景 -- 哈希索引。在一些数据仓库(ETL)系统或者一些做EDI的系统里面,source传一些文件给到我们,我们再对这些文件进行处理(加载)。这当中就需要队列表。每次线程扫描目录的时候要能够知道文件是已经在队列表里面,不需要再进一次队列。那么我们就必然需要对“文件完整路径”和“修改时间”建立一条索引来加快每次检索的速度。而我们都知道SQL Server对索引的长度是有限制,最长不得超过16个字段或者900个字节长度(详细参考MSDN的文章)。像“文件完整路径”这种值肯定存在超过900个字节长度的可能性。解决办法就是对“文件完整路径”和“修改时间”建立一条哈希索引,因为哈希索引的长度即便是最长是SHA-256也不过64个字节,相比普通索引还是小得多的。需要说明,长度越长的哈希索引在加密过程所需要消耗的CPU越多,但是它会产生的哈希值冲突的可能性就越低。这个需要你根据对表具体的数据行增长和作为索引字段的个数的情况而选择合适的检验函数。
但是有一点还是需要肯定的是,像上面这样的例子尽量是不要选择CHECKSUM,原因是CHECKSUM返回的是一个INT类型的值。我们都知道INT支持的最大值不过是2亿多。这里做一个测试,在10万行的时候其实已经出现了哈希值冲突的情况了。这种情况选择MD5或者SHA-128/SHA-256。
USE [JerryDB] GO IF OBJECT_ID('dbo.ChecksumCollision') IS NOT NULL DROP TABLE dbo.ChecksumCollision GO CREATE TABLE dbo.ChecksumCollision(col1 NVARCHAR(4000), checksum_col AS CHECKSUM(col1)) GO INSERT dbo.ChecksumCollision(col1) SELECT CAST(CHECKSUM(NEWID()) AS VARCHAR(100)) FROM [dbo].[Numbers] WHERE [Num] <= 100000 select * from ( select col1, checksum_col, count(checksum_col) over (partition by checksum_col) as cnt from dbo.ChecksumCollision) t where cnt > 1 order by checksum_col
上面代码的运行结果

下面测试测试一下用HASHBYTES('MD5',XXX)的情况,
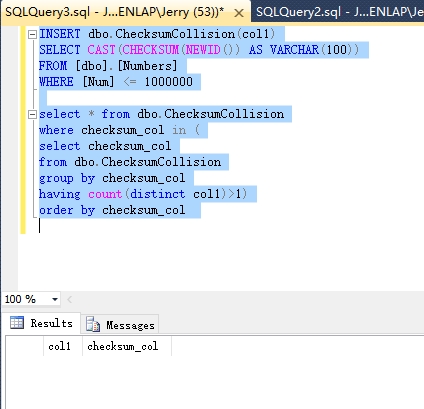
USE [JerryDB] GO IF OBJECT_ID('dbo.ChecksumCollision') IS NOT NULL DROP TABLE dbo.ChecksumCollision GO CREATE TABLE dbo.ChecksumCollision(col1 NVARCHAR(4000), checksum_col AS HASHBYTES('MD5',col1)) GO INSERT dbo.ChecksumCollision(col1) SELECT CAST(CHECKSUM(NEWID()) AS VARCHAR(100)) FROM [dbo].[Numbers] WHERE [Num] <= 1000000 select * from dbo.ChecksumCollision where checksum_col in ( select checksum_col from dbo.ChecksumCollision group by checksum_col having count(distinct col1)>1) order by checksum_col
上代码返回的结果
接下来来实现上面说的那个检查文件队列的例子
接下来我们建立一条索引
create index ix_ChecksumCollision_checksum_col on dbo.ChecksumCollision(checksum_col);
然后找一行来测试

然后试下运行下面的代码利用哈希索引找到改行
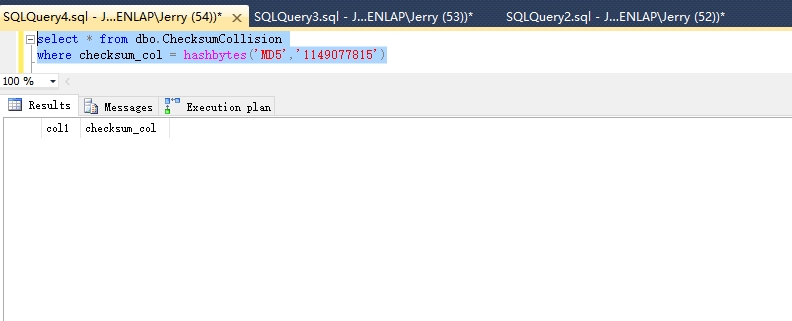
select * from dbo.ChecksumCollision where checksum_col = hashbytes('MD5',N'1149077815')
结果

观察执行计划,确定上面建的哈希索引是被使用到的

有1点需要说明的是:
不管是MD5或者SHA都是依赖数据类型来产生哈希值的,这就意味着N'Jerry'和'Jerry'产生的哈希值其实是一同的。像上面的查询语句如果改成这样则不会返回任何结果
关于性能,参考中的第三个链接有人对这些函数都做了性能比较。应该说SHA-512是最慢这点没错,毕竟用了整整64个字节来产生校检值。MD5倒是稍稍比CHECKSUM慢上一点而已。
参考:
http://www.brentozar.com/archive/2013/05/indexing-wide-keys-in-sql-server/
https://technet.microsoft.com/zh-cn/library/ms174415(v=sql.105).aspx